Automated Conversion Notice
Warning: This paper was automatically converted from LaTeX. While we strive for accuracy, some formatting or mathematical expressions may not render perfectly. Please refer to the original ArXiv version for the authoritative document.
1 Introduction
Occam’s razor, a foundational principle in scientific inquiry, suggests that the simplest among competing hypotheses should be selected. This principle has emphasized simplicity and parsimony in scientific thinking for centuries. Yet, the advent of deep neural networks (DNNs), with their multi-million parameter configurations and complex architectures, poses a stark challenge to this time-honored principle. The question arises: how do we reconcile the effectiveness of these intricate models with the pursuit of simplicity?
It is natural to pose this question in terms of model complexity. Unfortunately, many existing definitions of model complexity are problematic for DNNs. For instance, the parameter count, which in classical statistical learning theory is a commonly-used measure of the amount of information captured in a fitted model, is well-known to be inappropriate in deep learning. This is clear from technical results on generalization (Zhang et al.,, 2017), pruning (Blalock et al.,, 2020) and distillation (Hinton et al.,, 2015): the amount of information captured in a trained network is in some sense decoupled from the number of parameters.
As forcefully argued in (Wei et al.,, 2022), the gap in our understanding of DNN model complexity is induced by singularities, hence the need for a singularity-aware complexity measure. This motivates our appeal to Singular Learning Theory (SLT), which recognizes the necessity for sophisticated tools in studying statistical models exhibiting singularities. Roughly speaking, a model is singular if there are many ways to vary the parameters without changing the function; the more ways to vary without a change, the more singular (and thus more degenerate). DNNs are prime examples of such singular statistical models, characterized by complex degeneracies that make them highly singular.
SLT continues a longstanding tradition of using free energy as the starting point for measuring model complexity (Bialek et al.,, 2001), and here we see the implications of singularities. Specifically, the free energy, also known as the negative log marginal likelihood, can be shown to asymptotically diverge with sample size according to the law ; the coefficient of the linear term is the minimal loss achievable and the coefficient of the remaining logarithmic divergence is then taken as the model complexity of the model class. In regular statistical models, the coefficient is the number of parameters (divided by 2). In singular statistical models, is not tied to the number of parameters, indicating a different kind of complexity at play.
The LLC arises out of a consideration of the local free energy. We explore the mathematical underpinnings of the LLC in Section 3, utilizing intuitive concepts like volume scaling to aid understanding. Our contributions encompass 1) the definition of the new LLC complexity measure, 2) the development of a scalable estimator for the LLC, and 3) empirical validations that underscore the accuracy and practicality of the LLC estimator. In particular, we demonstrate that the estimator is accurate and scalable to modern network size in a setting where theoretical learning coefficients are available for comparison. Furthermore, we show empirically that some common training heuristics effectively control the LLC.
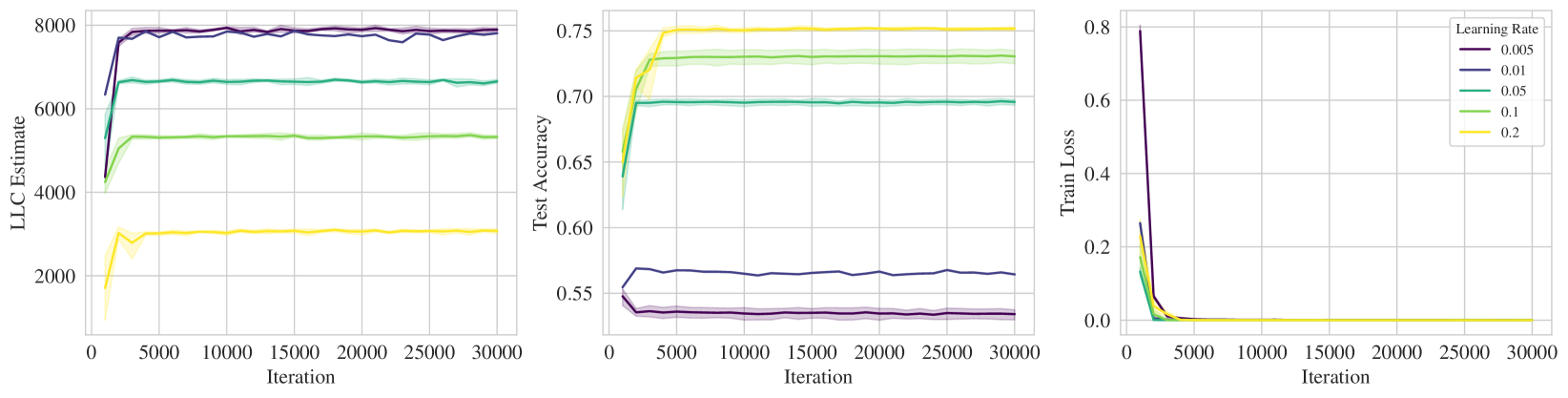
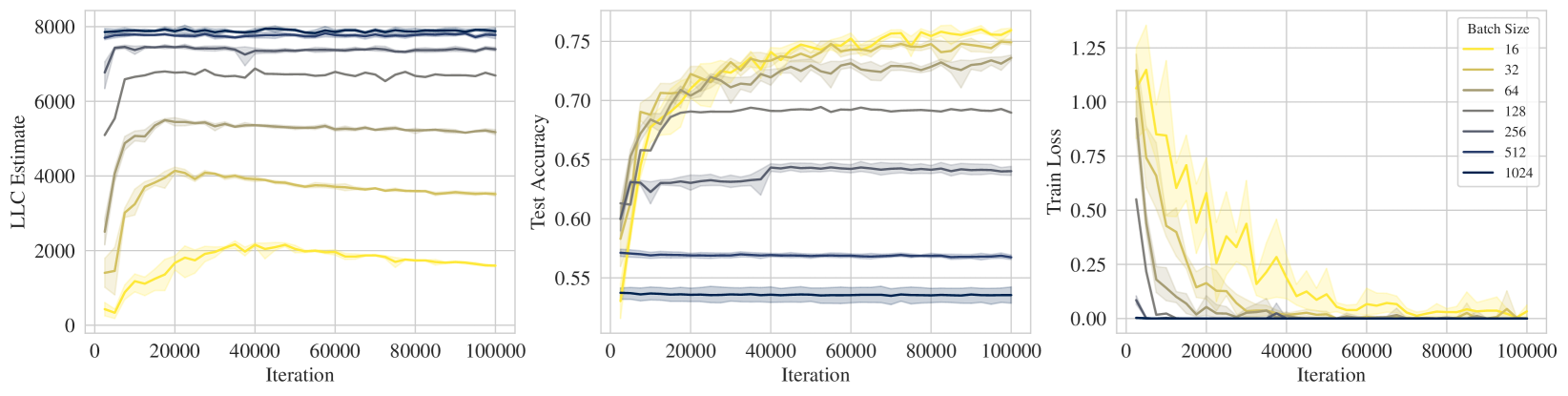
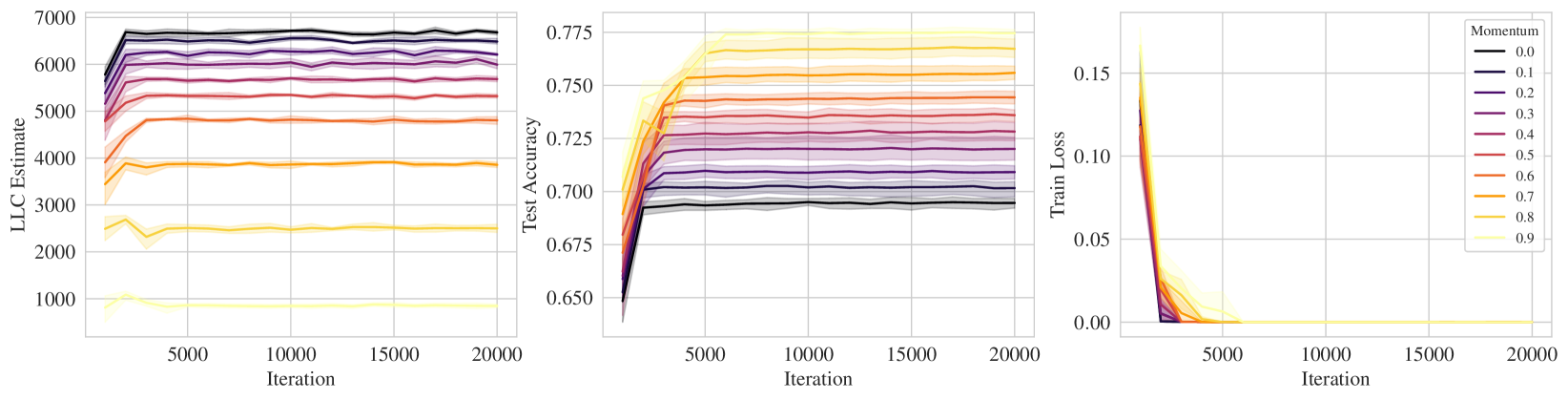
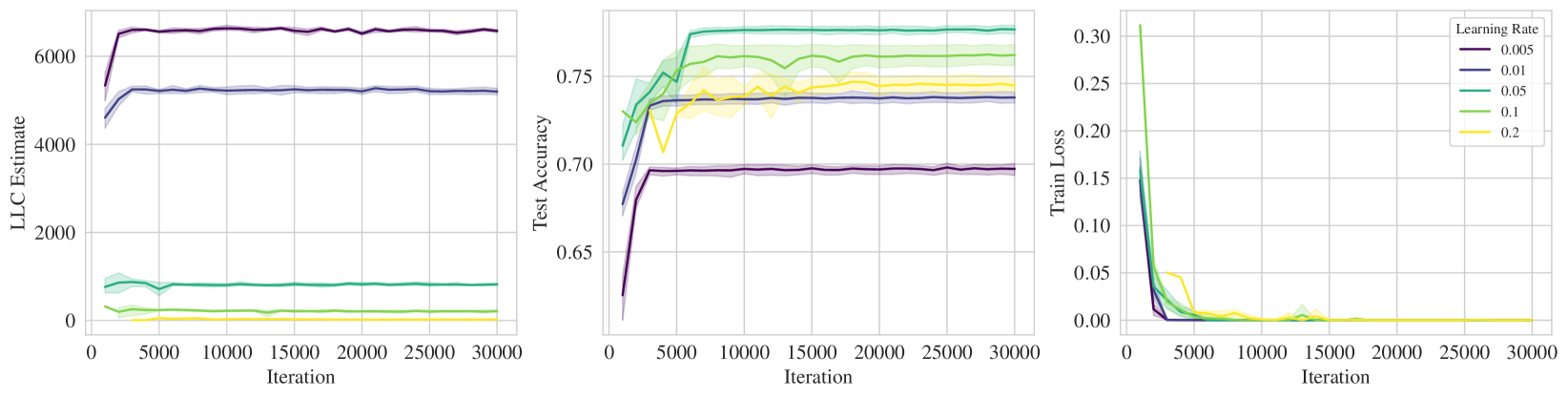
On this last point, we preview some results; Figure 1 displays the LLC estimate, test accuracy, and and training loss over the course of training ResNet18 on CIFAR10. Loosely speaking, lower LLC means a less complex, and thus more degenerate, neural network. In each of the rows, lighter colors represent stronger implicit regularization, e.g., higher learning rate, lower batch size, higher SGD momentum, which we see corresponds to a preference for lower LLC, i.e., simpler neural networks.
2 Setup
Let be a compact space of parameters . Consider the model-truth-prior triplet
| (1) |
where is the true data-generating mechanism, is the posited model with parameter representing the neural network weights, and is a prior on . Suppose we are given a training dataset of input-output pairs, , drawn i.i.d. from .
To these objects, we can associate the sample negative log likelihood function defined as and its theoretical counterpart defined as It is appropriate to also call and the training and population loss, respectively, since using the negative log likelihood encompasses many classic loss functions used in machine learning and deep learning, such as mean squared error (MSE) and cross-entropy.
The behavior of the training and population losses is highly nontrivial for neural networks. To properly account for model complexity of neural network models, it is critical to engage with the challenges posed by singularities. To appreciate this, we follow (Watanabe,, 2009) and make the following distinction between regular and singular statistical models. A statistical model is called regular if it is 1) identifiable, i.e. the parameter to distribution map is one-to-one, and 2) its Fisher information matrix is everywhere positive definite. We call a model singular if it is not regular. For an introduction to the implications of singular learning theory for deep learning, we refer the readers to Appendix A and further reading in (Wei et al.,, 2022). We shall assume throughout the triplet (1) satisfies a few fundamental conditions in SLT (Watanabe,, 2009). These conditions are stated and discussed in an accessible manner in A.1.
3 The local learning coefficient
In this paper, we introduce the Local Learning Coefficient (LLC), an extension of Watanabe, (2009)’s global learning coefficient, referred to as simply learning coefficient there. Below we focus on explaining the LLC through its geometric intuition, specifically as an invariant based on the volume of the loss landscape basin.
For readers interested in the detailed theoretical foundations, we have included comprehensive explanations in the appendices. Appendix A offers a short introduction to the basics of Singular Learning Theory (SLT), and Appendix B sets out formal conditions of the well-definedness of the LLC. This structure ensures that readers with varying levels of familiarity with SLT can engage with the content at their own pace.
3.1 Complexity via counting low loss parameters
At a local minimum of the population loss landscape there is a natural notion of complexity, given by the number of bits required to specify the minimum to within a tolerance . This idea is well-known in the literature on minimum description length (Grünwald and Roos,, 2019) and was used by (Hochreiter and Schmidhuber,, 1997) in an attempt to quantify the complexity of a trained neural network. However, a correct treatment has to take into consideration the degeneracy of the geometry of the population loss , as we now explain.
Consider a local minimum of the population loss and a closed ball centered on such that for all we have . Given a tolerance we can consider the set of parameters whose loss is within the tolerance, the volume of which we define to be
| (2) |
The minimal number of bits to specify this set within the ball is
| (3) |
This can be taken as a measure of the complexity of the set of low loss parameters near . However, as it stands this notion depends on and has no intrinsic meaning. Classically, this is addressed as follows: if a model is regular and thus is locally quadratic around , the volume satisfies a law of the form where is a constant that depends on the curvature of the basin around the local minimum , and is the dimension of .
This explains why is a valid measure of complexity in the regular case, albeit one that cannot distinguish from any other local minima. The curvature is less significant than the scaling exponent, but can distinguish local minima and is sometimes used as a complexity measure.
The population loss of a neural network is not locally quadratic near its local minima, from which it follows that the functional form of the volume is more complicated than in the regular case. The correct functional form was discovered by Watanabe, (2009) and we adapt it here to a local neighborhood of a parameter (see Appendix A for details):
Definition 1 (The Local Learning Coefficient (LLC), ).
There exists a unique rational111The fact that is rational-valued, and not real-valued, as one would naively assume, is a deep fact of algebraic geometry derived from the celebrated Hironaka’s resolution of singularities. number , a positive integer and some constant such that asymptotically as ,
| (4) |
We call the Local Learning Coefficient (LLC), and the local multiplicity.
In the case where , the formula simplifies, and
| (5) |
Thus, the LLC is the (asymptotic) volume scaling exponent near a minimum in the loss landscape: increasing the error tolerance by a factor of increases the volume by a factor of . Applying Equation (3), the number of bits needed to specify within , for sufficiently small and in the case , is approximated by
Informally, the LLC tells us the number of additional bits needed to halve an already small error of :
See Figure LABEL:fig:volume_scaling for simple examples of the LLC as a scaling exponent. We note that, in contrast to the regular case, the scaling exponent depends on the underlying data distribution .
The (global) learning coefficient was defined by Watanabe, (2001). If is taken to be a global minimum of the population loss , and the ball is taken to be the entire parameter space , then we obtain the global learning coefficient as the scaling exponent of the volume . The learning coefficient and related quantities like the WBIC (Watanabe,, 2013) have historically seen significant application in Bayesian model selection (e.g. Endo et al.,, 2020; Fontanesi et al.,, 2019; Hooten and Hobbs,, 2015; Sharma,, 2017; Kafashan et al.,, 2021; Semenova et al.,, 2020).
In Appendix C, we prove that the LLC is invariant to local diffeomorphism: that is, roughly, a locally smooth and invertible change of variables. This property is motivated by the desire that a good complexity measure should not be confounded by superficial differences in how a model is represented: two models which are essentially the same should have the same complexity.
4 LLC estimation
Having established the intuition behind the theoretical LLC in terms of volume scaling, we now turn to the task of estimating it. As described in the introduction, the LLC is a coefficient in the asymptotic expansion of the local free energy. It is this fact that we leverage for estimation. There is a mathematically rigorous link between volume scaling and the appearance of the LLC in the local free energy which we will not discuss in detail; see (Watanabe,, 2009, Theorem 7.1).
We first introduce what we call the idealized LLC estimator which is theoretically sound, albeit intractable from a computational point of view. In the sections that follow the introduction of the idealized LLC estimator, we walk through the steps taken to engineer a practically implementable version of the idealized LLC estimator.
4.1 Idealized LLC estimator
Consider the following integral
| (6) |
where is again the sample negative log likelihood, denotes a small ball of radius around and is a prior over model parameters . If (6) is high, there is high posterior concentration around . In this sense, (6) is a measure of the concentration of low-loss solutions near . Next consider a log transformation of with a negative sign, i.e.,
| (7) |
This quantity is sometimes called (negative) log marginal likelihood or free energy, depending on the discipline. Given a local minimum of the population negative log likelihood , it can be shown using the machinery of SLT that, asymptotically in , we have
| (8) |
where is the theoretical LLC expounded in Section 3. Remarkably, the asymptotic approximation in (8) holds even for singular models such as neural networks; further discussion on this can be found in Appendix B.
The asymptotic approximation in (8) suggests that a reasonable estimator of might come from re-arranging (8) to give what we call the idealized LLC estimator,
| (9) |
But as indicated by the name, the idealized LLC estimator cannot be easily implemented; computing or even MCMC sampling from the posterior to estimate is made no less challenging by the need to confine sampling to the neighborhood . In what follows, we use the idealized LLC estimator as inspiration for a practically-minded LLC estimator.
4.2 Surrogate for enforcing
The first step towards a practically-minded LLC estimator is to circumvent the constraint posed by the neighborhood . To this end, we introduce a localizing Gaussian prior that acts as a surrogate for enforcing the domain of integration given by . Specifically, let
be a Gaussian prior centered at the origin with scale parameter . We replace (6) with
which, for , can also be recognized as the normalizing constant to the posterior distribution given by
| (10) |
where plays the role of an inverse temperature. Large values of force the posterior distribution in (10) to stay close to . A word on the notation : this is a distribution in solely, the parameters are fixed, hence the normalizing constant to (10) is an integral over only. As is to be viewed as a proxy to (6), we shall accordingly treat
as a proxy for in (7). Although it is tempting at this stage to simply drop into the idealized LLC estimator in place of , we have to address estimation of , the subject of the next section.
4.3 The LLC estimator
Let us denote the expectation of a function with respect to the posterior distribution in (10) as
Consider the quantity
| (11) |
where the inverse temperature is deliberately set to . The quantity in (11) may be regarded as a localized version of the widely applicable Bayesian information criterion (WBIC) first introduced in (Watanabe,, 2013). It can be shown that (11) is a good estimator of in the following sense: the leading order terms of (11) match those of when we perform an asymptotic expansion in sample size . This justifies using (11) to estimate . Further discussion on this can be found in in Appendix D
Going back to (9), we approximate first with , which is further estimated by (11). We are finally ready to define the LLC estimator.
Definition 2 (Local Learning Coefficient (LLC) estimator).
Let be a local minimum of . Let . The associated local learning coefficient estimator is given by
| (12) |
Note that depends on but we have suppressed this in the notation. Let us ponder the pleasingly simple form that is the LLC estimator. The expectation term in (12) is a measure of the loss under perturbation near . If the perturbed loss, under this expectation, is very close to , then is small. This accords with our intuition that if is simple, its loss should not change too much under reasonable perturbations. Finally we note that in applications, we use the empirical loss to determine a critical point of interest, i.e., We lose something by plugging in to (12) directly since we end up using the dataset twice. However we do not observe adverse effects in our experiments, see Figure 4 for an example.
4.4 The SGLD-based LLC estimator
The LLC estimator defined in (12) is not prescriptive as to how the expectation with respect to the posterior distribution should actually be approximated. A wide array of MCMC techniques are possible. However, to be able to estimate the LLC at the scale of modern deep learning, we must look at efficiency. In practice, the computational bottleneck to implementing (12) is the MCMC sampler. In particular, traditional MCMC samplers must compute log-likelihood gradients across the entire training dataset, which is prohibitively expensive at modern dataset sizes.
If one modifies these samplers to take minibatch gradients instead of full-batch gradients, this results in stochastic-gradient MCMC, the prototypical example of which is (Welling and Teh,, 2011)’s Stochastic Gradient Langevin Dynamics (SGLD). The computational cost of this sampler is much lower: roughly the cost of a single SGD step times the number of samples required. The standard SGLD update applied to sampling (10) at the optimal temperature required for the LLC estimator is given by
where is a randomly sampled minibatch of samples of size for step and controls both step size and variance of injected Gaussian noise. Crucially, the log-likelihood gradient is evaluated using mini-batches. In practice, we choose to shuffle the dataset once and partition it into a sequence of size segments as minibatches instead of drawing fresh random samples of size .
Let us now suppose we have obtained approximate samples of the tempered posterior distribution at inverse temperature via SGLD. This is usually taken from the SGLD trajectory after burn-in. We can then form what we call the SGLD-based LLC estimator,
| (13) |
For further computation saving, we also recycle the forward passes that compute , which is required for computing via back-propagation, as unbiased estimate of . Here by , we mean , though the notation suppresses the dependence on for brevity. Pseudocode for this minibatch version of the SGLD-based LLC estimator is provided in Appendix G. Henceforth, when we say the SGLD-based LLC estimator, we are referring to the minibatch version. In Appendix H, we give a comprehensive guide on best practices for implementing the SGLD-based LLC estimator including choices for , number of SGLD iterations, and required burn-in.
5 Experiments
The goal of our experiments is to give evidence that the LLC estimator is accurate, scalable and can reveal insights on deep learning practice. Throughout the experiments, we implement the minibatch version of the SGLD-based LLC estimator presented in the pseudo-algorithm in Appendix G.
There are also a number of experiments we performed that are relegated to the appendices due to space constraints. They include
-
deploying LLC estimation on transformer language models (Section L)
-
an experiment on a small ReLU network verifying that SGLD sampler is just as accurate as one that uses full-batch gradients (Appendix M)
-
an experiment comparing the optimizers SGD and entropy-SGD with the latter having intimate connection to our notion of complexity (Appendix N)
Every experiment described in the main text below has an accompanying section in the Appendix that offers full experimental details, further discussion, and possible additional figures/tables.
5.1 LLC for Deep Linear Networks (DLNs)
In this section, we verify the accuracy and scalability of our LLC estimator against theoretical LLC values in deep linear networks (DLNs) up to 100M parameters. Recall DLNs are fully-connected feedforward neural networks with identity activation function. The input-output behavior of a DLN is obviously trivial; it is equivalent to a single-layer linear network obtained by multiplying together the weight matrices. However, the geometry of such a model is highly non-trivial — in particular, the optimization dynamics and inductive biases of such networks have seen significant research interest (Saxe et al.,, 2013; Ji and Telgarsky,, 2018; Arora et al.,, 2018).
Thus one reason we chose to study DLN model complexity is because they have long served as an important sandbox for deep learning theory. Another key factor is the recent clarification of theoretical LLCs in DLNs by Aoyagi, (2024), making DLNs the most realistic setting where theoretical learning coefficients are available. The significance of Aoyagi, (2024) lies in the substantial technical difficulty of deriving theoretical global learning coefficients (and, by extension, theoretical LLCs) which means that these coefficients are generally unavailable except in a few exceptional cases, with most of the research conducted decades ago (Yamazaki and Watanabe, 2005b, ; Aoyagi et al.,, 2005; Yamazaki and Watanabe,, 2003; Yamazaki and Watanabe, 2005a, ). Further details and discussion of the theoretical result in Aoyagi, (2024) can be found in Appendix I.
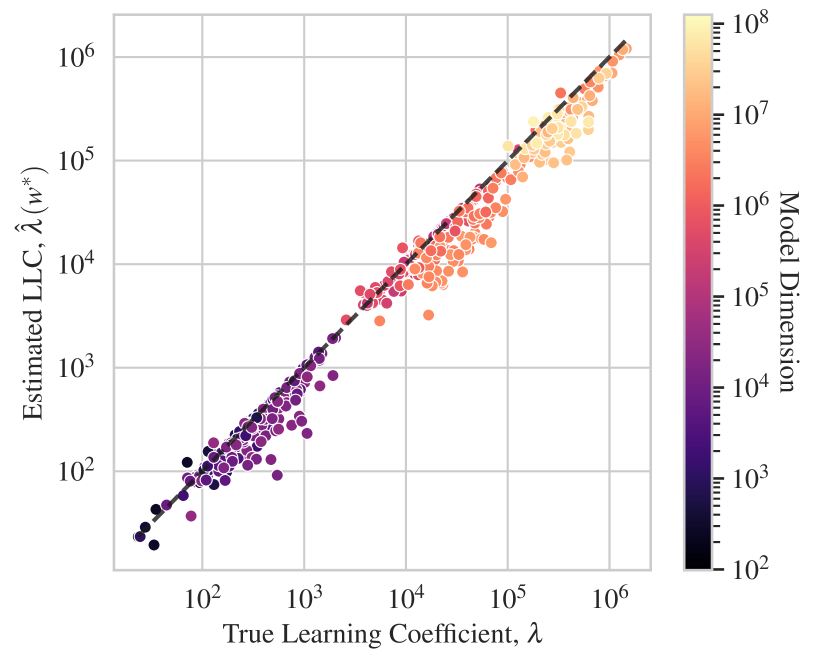
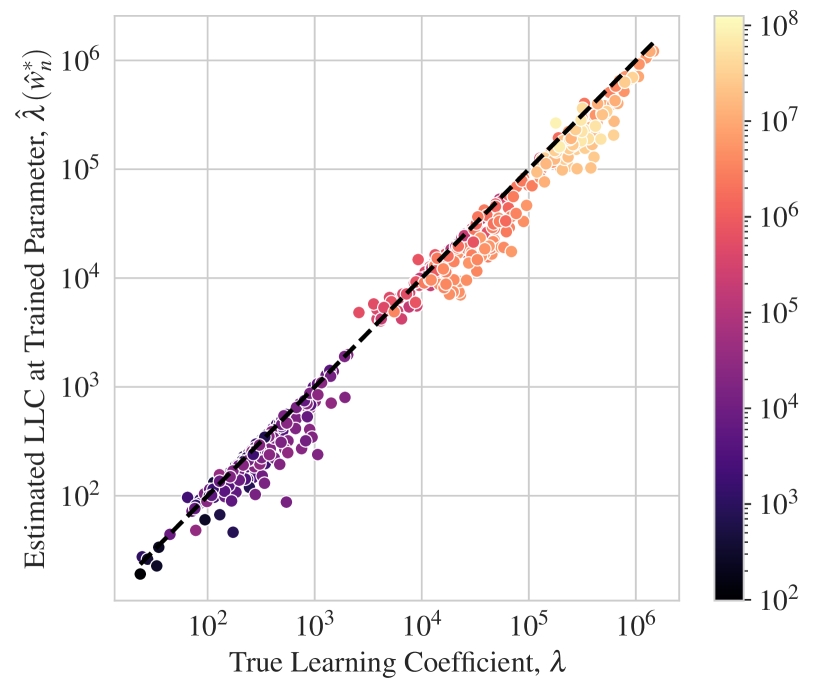
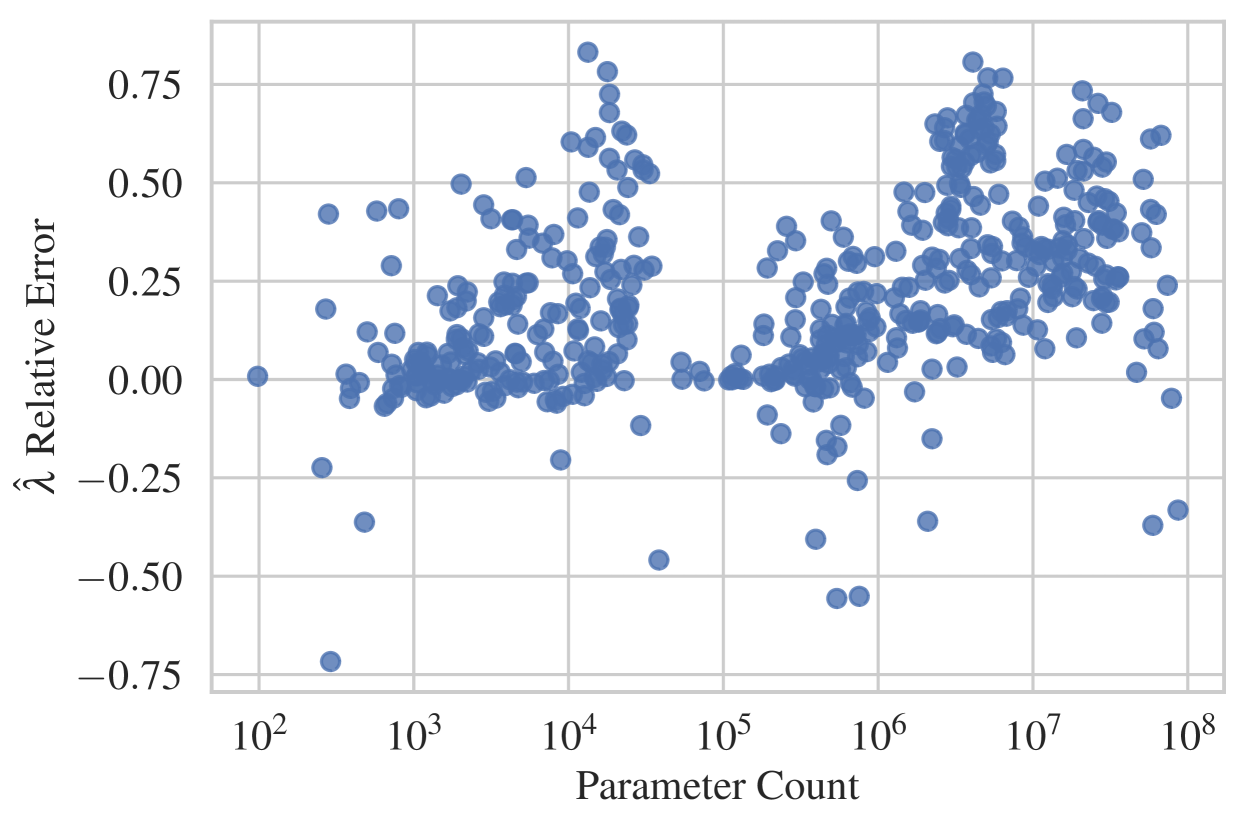
The results are summarized in Figure 4. Our LLC estimator is able to accurately estimate the learning coefficient in DLNs up to 100M parameters. We further show that accuracy is maintained even if (as is typical in practice) one does not evaluate the LLC at a local minimum of the population loss, but is instead forced to use SGD to first find a local minimum . Further experimental details and results for this section are detailed in Appendix J. Overall it is quite remarkable that our LLC estimator, after the series of engineering steps described in Section 4, maintains such high levels of accuracy.
5.2 LLC for ResNet
Here, we empirically test whether implicit regularization effectively induces a preference for simplicity as manifested by a lower LLC. We examine the effects of SGD learning rate, batch size, and momentum on the LLC. Note that we do so in isolation, i.e., we do not look at interactions between these factors. For instance, when we vary the learning rate, we hold everything else constant including batch size and momentum values.
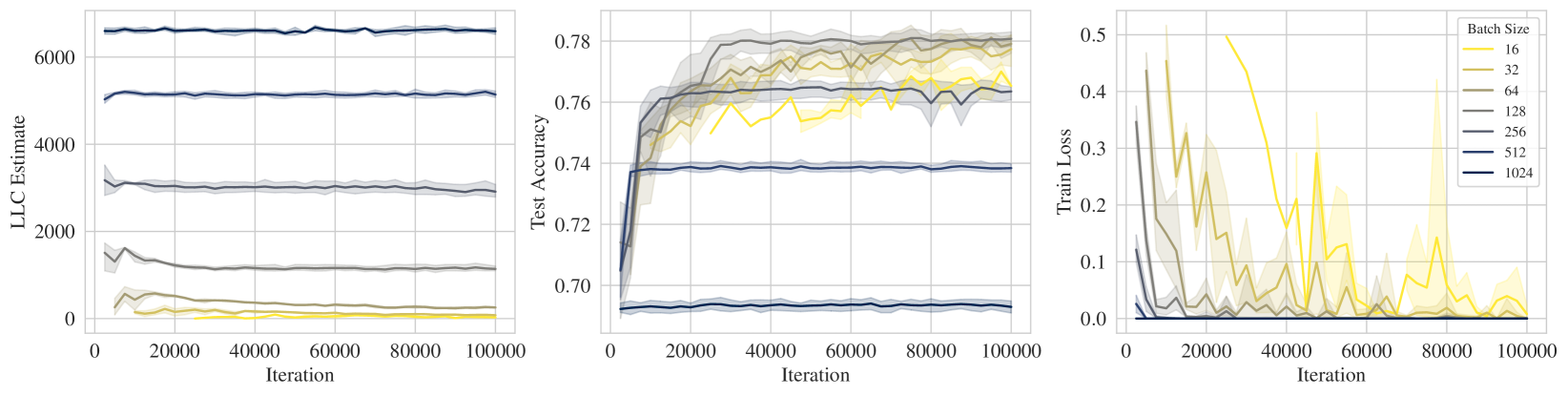
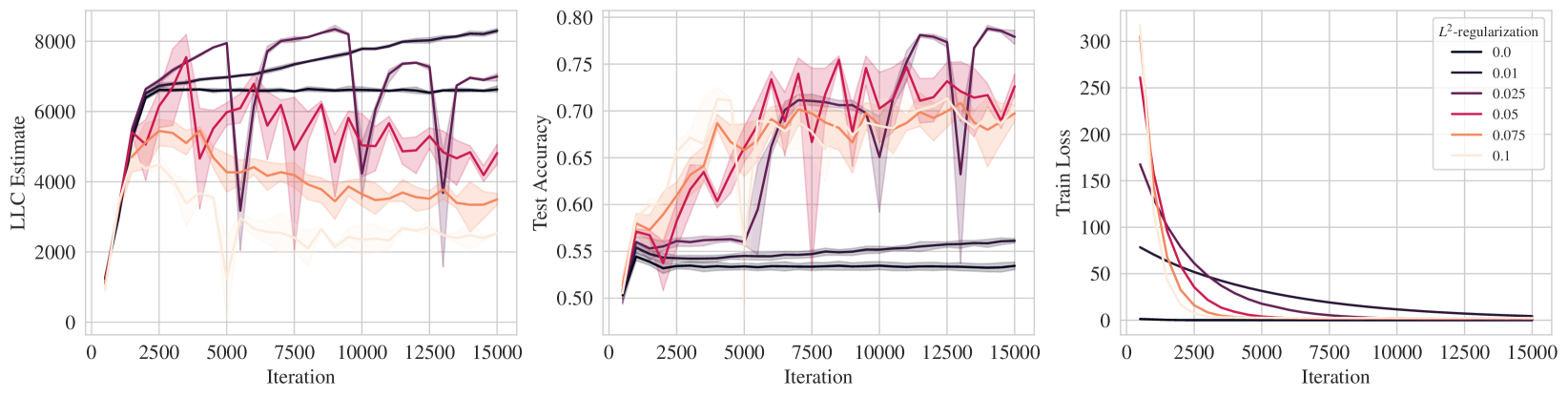
We perform experiments on ResNet18 trained on CIFAR10 and show the results in Figure 1. We see that the training loss reaches zero in most instances and therefore on its own cannot distinguish between the effect of the implicit regularization. In contrast, we see that there is a consistent pattern of “stronger implicit regularization = higher test accuracy = lower LLC". Specifically, higher learning rate, lower batch size, higher momentum all apply stronger implicit regularization which is reflected in lower LLC. Full experimental details can be found in Appendix K. Note that in Figures 1 we employed SGD without momentum in the top two rows. We repeat the experiments in these top two rows for SGD with momentum; the associated results in Figure K.1 support very similar conclusions. We also conducted some explicit regularization experiments involving L2 regularization (Figure K.2 in Appendix K) and again conclude that stronger regularization is accompanied by lower LLC.
In contrast to the LLC estimates for DLN, the LLC estimates for ResNet18 cannot be calibrated as we do not know the true LLC values. With many models in practice, we find value in the LLC estimates by comparing their relative values between models with shared context. For instance, when comparing LLC values we might hold everything constant while varying one factor such as SGD batch size, learning rate, or momentum as we have done in this section.
6 Related work
We briefly cover related work here; more detail may be found in Appendix E. The primary reference for the theoretical foundation of this work, known as SLT, is Watanabe, (2009). The global learning coefficient, first introduced by (Watanabe,, 2001), provides the asymptotic expansion of the free energy, which is equivalent to the negative log Bayes marginal likelihood, an all-important important quantity in Bayesian analysis. Subsequent research has utilized algebraic-geometric tools to calculate the learning coefficient for various machine learning models (Yamazaki and Watanabe, 2005b, ; Aoyagi et al.,, 2005; Aoyagi,, 2024; Yamazaki and Watanabe,, 2003; Yamazaki and Watanabe, 2005a, ). SLT has also enhanced the understanding of model selection criteria in Bayesian statistics. Of particular relevance to this work is Watanabe, (2013), which introduced the WBIC estimator of free energy. This estimator has been applied in various practical settings (Endo et al.,, 2020; Fontanesi et al.,, 2019; Hooten and Hobbs,, 2015; Sharma,, 2017; Kafashan et al.,, 2021; Semenova et al.,, 2020).
The LLC can be seen as a singularity-aware version of basin broadness measures, which attempt to connect geometric "broadness" or "flatness" with model complexity (Hochreiter and Schmidhuber,, 1997; Jiang et al.,, 2019). In particular, the LLC estimator bears resemblance to PAC-Bayes inspired flatness/sharpness measures (Neyshabur et al.,, 2017), but takes into account the non-Gaussian nature of the posterior distribution in singular models.
The LLC is set apart from classic model complexity measures such as Rademacher complexity (Koltchinskii and Panchenko,, 2000) and the VC dimension (Vapnik and Chervonenkis,, 1971) because it measures the complexity of a specific model rather than the complexity over the function class where is the neural network function. This makes the LLC an appealing tool for understanding the interplay between function class, data properties, and training heuristics.
Concurrent work by (Chen et al., 2023a, ) proposes a measure called the learning capacity, which can be viewed as a finite- version of the learning coefficient, and investigates its behavior as a function of training size .
7 Outlook
An exciting direction of future research is to study the role of the LLC in detecting phase transitions and emergent abilities in deep learning models. A first step in this direction was undertaken in (Chen et al., 2023b, ) where the energy (training loss) and entropy (both estimated and theoretical LLC) were tracked as training progresses; it was observed that energy and entropy proceed along staircases in opposing directions. Further, Hoogland et al., (2024) showed how the estimated LLC can be used to detect phase transitions in the formation of in-context learning in transformer language models. It is natural to wonder if the LLC could shed light on the hypothesis that SGD-trained neural networks sequentially learn the target function with a “saddle-to-saddle" dynamic. Previous theoretical works had to devise complexity measures on a case-by-case basis (Abbe et al.,, 2023; Berthier,, 2023). We posit that the free energy perspective could offer a more unified and general approach to understanding the intricate dynamics of learning in deep neural networks by accounting for competition between model fit and model complexity during training.
Appendix A Background on Singular Learning Theory
Most models in machine learning are singular: they contain parameters where the Fisher information matrix is singular. While these parameters where the Fisher information is degenerate form a measure zero subset, their effect is far from negligible. Singular Learning Theory (SLT) shows that the geometry in the neighbourhood of these degenerate points determines the asymptotics of learning (Watanabe,, 2009). The theory explains observable effects of degeneracy in common machine learning models under practical settings (Watanabe,, 2018) and has the potential to account for important phenomena in deep learning (Wei et al.,, 2022). The central quantity of SLT is the learning coefficient . Many notable SLT results are conveyed through the learning coefficient which can be thought of as the complexity of the model class relative to the true distribution. In this section we carefully define the (global) learning coefficient , which we then contrast with the local learning coefficient .
For notational simplicity, we consider here the unsupervised setting where we have the model parameterised by a compact parameter space . We assume fundamental conditions I and II of (Watanabe,, 2009, §6.1, §6.2). In particular is defined by a finite set of real analytic inequalities, at every parameter the distribution should have the same support as the true density , and the prior density is a product of a positive smooth function and non-negative real analytic . We refer to
| (14) |
as the model-truth-prior triplet.
Let be the Kullback-Leibler divergence between the truth and the model
and define the (average) negative log likelihood to be
where is the entropy of the true distribution. Set . Let
be the set of optimal parameters. We say the truth is realizable by the model if . We do not assume that our models are regular or that the truth is realizable, but we do assume the model-truth-prior triplet satisfies the more general condition of relative finite variance (Watanabe,, 2013). We also assume that there exists in the interior of satisfying .
Following Watanabe, (2009) we define:
Definition 3.
The zeta function of (14) is defined for by
and can be analytically continued to a meromorphic function on the complex plane with poles that are all real, negative and rational (Watanabe,, 2009, Theorem 6.6). Let be the largest pole of and its multiplicity. Then, the learning coefficient and its multiplicity of the triple (14) are defined to be and respectively.
When is a singular model, is an analytic variety which is in general positive dimensional (not a collection of isolated points). As long as on the learning coefficient is equal to a birational invariant of known in algebraic geometry as the Real Log Canonical Threshold (RLCT). We will always assume this is the case, and now recall how is described geometrically.
With for sufficiently small , resolution of singularities (Hironaka,, 1964) gives us the existence of a birational proper map from an analytic manifold which monomializes in the following sense, described precisely in (Watanabe,, 2009, Theorem 6.5): there are local coordinate charts covering with coordinates such that the reparameterisation puts and into normal crossing form
| (15) | |||
| (16) | |||
| (17) |
for some positive smooth function . The RLCT of is independent of the (non-unique) resolution map , and may be computed as (Watanabe,, 2009, Definition 6.4)
| (18) |
The multiplicity is defined as
For there exist coordinate charts such that and (15), (16) hold. The RLCT of at is then (Watanabe,, 2009, Definition 2.7)
| (19) |
We then have the RLCT . In regular models, all are and hence the RLCT and , see (Watanabe,, 2009, Remark 1.15).
A.1 Background assumptions in SLT
There are a few technical assumptions throughout SLT that we shall collect in this section. We should note that these are only sufficient but not necessary conditions for many of the results in SLT. Most of the assumptions can be relaxed on a case by case basis without invalidating the main conclusions of SLT. For in depth discussion see Watanabe, (2009, 2010, 2018).
With the same hypotheses as above, the log likelihood ratio
is assumed to be an -valued analytic function of with that can be extended to a complex analytic function on . A more conceptually significant assumption is the condition relatively finite variance, which consists of the following two requirements:
-
For any optimal parameters , we have almost everywhere. This is also known as essential uniqueness.
-
There exists such that for all , we have
Note that if the true density is realizable by the model, i.e. there exist such that almost everywhere, then these conditions are automatically satisfied. This includes settings for which the training labels are synthetically generated by passing inputs through a target model (in which case realizability is satisfied by construction), such as our experiments involving DLNs and some of the experiments involving MLPs. For experiments involving real data, it is unclear how reasonable it is to assume that relative finite variance holds.
Appendix B Well-definedness of the theoretical LLC
Here we remark on how we adapt the (global) learning coefficient of Definition 3 to define the local learning coefficient in terms of the poles of a zeta function, and how this relates to the asymptotic volume formula in Definition 1 of the main text.
In addition to the setup described above, now suppose we have a local minimum of the negative log likelihood and as in Section 3.1 we assume to be a closed ball centered on such that is the minimum value of on the ball. We define
then we can form the local triplet with parameter space . Note that is cut out by a finite number of inequalities between analytic functions, and hence so is .
Provided the prior does not contribute to the leading terms of the asymptotic expansions considered, and in particular does not appear in the asymptotic formula for the volume in Definition 1, and so we disregard it in the main text for simplicity.
Assuming relative finite variance ofr the local triplet, we can apply the discussion of Section A. In particular, we can define the LLC and the local multiplicity in terms of the poles of the “local” zeta function
Note that since differ by which does not depend on .
In order for the LLC to be a learning coefficient in its own right, it must be related, asymptotically, to the local free energy in the manner stipulated in (8) in the main text. We verify this next. To derive the asymptotic expansion of the local free energy , we assume in addition that if and . That is, is at least as degenerate as any nearby minimiser. Note that the KL divergence for this triplet is just the restriction of to , but the local triplet has its own set of optimal parameters
| (20) |
Borrowing the proof in Watanabe, (2009, §3), we can show that
| (21) |
where the difference between and contributes a summand to the constant term. Note that the condition of relative finite variance is used to establish (21). This explains why we can consider as a local learning coefficient, following the ideas sketched in (Watanabe,, 2009, Section 7.6). The presentation of the LLC in terms of volume scaling given in the main text now follows from (Watanabe,, 2009, Theorem 7.1).
Appendix C Reparameterization invariance of the LLC
The LLC is invariant to local diffeomorphism of the parameter space - roughly a locally smooth and invertible change of variables.
Note that this automatically implies several weaker notions of invariance, such as rescaling invariance in feedforward neural networks; other e.g. Hessian-based complexity measures have been undermined by their failure to stay invariant to this symmetry (Dinh et al.,, 2017). We now show how the LLC is invariant to local diffeomorphism. The fact that the LLC is an asymptotic quantity is crucial; this property would not hold for the volume itself, for any value of .
Let and be open subsets of parameter spaces and . A local diffeomorphism is an invertible map , such that both and are infinitely differentiable. We further require that respect the loss function: that is, if and are loss functions on each space, we insist that for all .
Supposing such a exists, the statement to be proved is that the LLC at under is equal to the LLC at under . Define
Now note that by the change of variables formula for diffeomorphisms, we have
where is the Jacobian determinant of at .
The fact that is a local diffeomorphism implies that there exists constants such that for all . This means that
Finally, applying the definition of the LLC and its multiplicity , and leveraging the fact that this definition is asymptotic as , we can conclude that
which demonstrates that the LLC is preserved by the local diffeomorphism .
Appendix D Consistency of local WBIC
In the main text, we introduced (11) as an estimator of . Our motivation for this estimator comes directly from the well-known widely applicable Bayesian information criterion (WBIC) (Watanabe,, 2013). In this section, we refer to (11) as the local WBIC and denote it
It is a direct extension of the proofs in Watanabe, (2013) to show that the first two terms in the asymptotic expansion of the local WBIC match those of . By this we mean that it can be shown that
and
| (22) |
This firmly establishes that (11) is a good estimator of . However, it is important to understand that we cannot immediately conclude that it is a good estimator of .
We conjecture that is equal to the LLC given certain conditions on . So far, all our empirical findings suggest this. Detailed proof of this conjecture, in particular ascertaining the exact conditions on , will be left as future theoretical work.
Appendix E Related work
We review both the singular learning theory literature directly involving the learning coefficient, as well as research from other areas of machine learning that may be relevant. This is an expanded version of the discussion in Section 6.
Singular learning theory. Our work builds upon the singular learning theory (SLT) of Bayesian statistics: good references are Watanabe, (2009, 2018). The global learning coefficient, first introduced by (Watanabe,, 2001), provides the asymptotic expansion of the free energy, which is equivalent to the negative log Bayes marginal likelihood, an all-important important quantity in Bayesian analysis. Later work used algebro-geometric tools to bound or exactly calculate the learning coefficient for a wide range of machine learning models, including Boltzmann machines Yamazaki and Watanabe, 2005b , single-hidden-layer neural networks Aoyagi et al., (2005), DLNs Aoyagi, (2024), Gaussian mixture models Yamazaki and Watanabe, (2003), and hidden Markov models Yamazaki and Watanabe, 2005a .
SLT has also enhanced the understanding of model selection criteria in Bayesian statistics. Of particular relevance to this work is Watanabe, (2013), which introduced the WBIC estimator of free energy. This estimator has been applied in various practical settings (e.g. Endo et al.,, 2020; Fontanesi et al.,, 2019; Hooten and Hobbs,, 2015; Sharma,, 2017; Kafashan et al.,, 2021; Semenova et al.,, 2020). Some of the estimation methodology in this paper can be seen as a localized extension of the WBIC. Several other papers have explored improvements or alternatives to this estimator Iriguchi and Watanabe, (2007); Imai, 2019a ; Imai, 2019b .
Basin broadness. The learning coefficient can be seen as a Bayesian version of basin broadness measures, which typically attempt to empirically connect notions of geometric “broadness" or “flatness" with model complexity Hochreiter and Schmidhuber, (1997); Jiang et al., (2019). However, the evidence supporting the (global) learning coefficient (in the Bayesian setting) is significantly stronger: the learning coefficient provably determines the Bayesian free energy to leading order Watanabe, (2009). We expect the utility of the learning coefficient as a geometric measure to apply beyond the Bayesian setting, but whether the connection with generalization will continue to hold is unknown.
Neural network identifiability. A core observation leading to singular learning theory is that the map from parameters to statistical models may not be one-to-one (in which case, the model is singular). This observation has been made in parallel by researchers studying neural network identifiability Sussmann, (1992); Fefferman, (1994); Kůrková and Kainen, (1994); Phuong and Lampert, (2020). Recent work222Within the context of singular learning theory, this fact was known at least as early as Fukumizu, (1996). has shown that the degree to which a network is identifiable (or inverse stable) is not uniform across parameter space Berner et al., (2019); Petersen et al., (2020); Farrugia-Roberts, (2023). From this perspective, the LLC can be viewed as a quantitative measure of “how identifiable" the network is near a particular parameter.
Statistical mechanics of the loss landscape. A handful of papers have explored related ideas from a statistical mechanics perspective. Jules et al., (2023) use Langevin dynamics to probe the geometry of the loss landscape. Zhang et al., (2018) show how a bias towards “wide minima" may be explained by free energy minimization. These observations may be formalized using singular learning theory LaMont and Wiggins, (2019). In particular, the learning coefficient may be viewed as a heat capacity LaMont and Wiggins, (2019), and learning coefficient estimation corresponds to measuring the heat capacity by molecular dynamics sampling.
Other model complexity measures. The LLC is set apart from a number of classic model complexity measures such as Rademacher complexity (Koltchinskii and Panchenko,, 2000), the VC dimension (Vapnik and Chervonenkis,, 1971) because the latter measures act on an entire class of functions while the LLC measures the complexity of a specific individual function within the context of the function class carved out by the model (e.g. via DNN architecture). This affords the LLC a better position for unraveling the theoretical mysteries of deep learning, which cannot be disentangled from the way in which DNNs are trained or the data that they are trained on.
In the context studied here, our proposed LLC measures the complexity of a trained neural network rather than complexity over the entire function class of neural networks. It is also sensitive to the data distribution, making it ideal for understanding the intricate dance between function class, data properties, and implicit biases baked into different training heuristics.
Like earlier investigations by Le, (2018); Zhang et al., (2018); LaMont and Wiggins, (2019), our notion of model complexity appeals to the correspondence between parameter inference and free energy minimization. This mostly refers to the fact that the posterior distribution over has high concentration around if the associated local free energy, , is low. Viewed from the free energy lens, it is thus not surprising that “flatter” minima (low ) might be preferred over “sharper” minima (high ) even if the former has high training loss (higher ). Put another way, (8) reveals that parameter inference is not about seeking the solution with the lowest loss. In the terminology of Zhang et al., (2018), parameter inference plays out as a competition between energy (loss) and entropy (Occam’s factor). Despite spiritual similarities, our work starts to depart from that of Zhang et al., (2018) and Le, (2018) in our technical treatment of the local free energy. These prior works rely on the Laplace approximation to arrive at the result
| (23) |
where is the Hessian of the loss. The flatness of a local minimum is calculated as , which is, notably, ill-defined for neural networks333Balasubramanian, (1997) includes all terms in the Laplace expansion as a type of complexity measure.. Indeed a concluding remark in Zhang et al., (2018) points out that “a more nuanced metric is needed to characterise flat minima with singular Hessian matrices." Le, (2018), likewise, state in their introduction that “to compute the (model) evidence, we must carefully account for this degeneracy", but then argues that degeneracy is not a major limitation to applying (23). This is only partially true. For a very benign type of degeneracy, (23) is indeed valid. However, under general conditions, the correct asymptotic expansion of the local free energy is provided in (8). It might be said that while Zhang et al., (2018) and Le, (2018) make an effort to account for degeneracies in the DNN loss landscape, they only take a small step up the degeneracy ladder while we take a full leap.
Similarity to PAC-Bayes. We have just described how the theoretical LLC is the sought-after notion of model complexity coming from earlier works who adopt the energy-entropy competition perspective. Interestingly, the actual LLC estimator also has connections to another familiar notion of model complexity. Among the diverse cast of complexity measures, see e.g., Jiang et al., (2019) for a comprehensive overview of over forty complexity measures in modern deep learning, the LLC estimator bears the most resemblance to PAC-Bayes inspired flatness/sharpness measures (Neyshabur et al.,, 2017). Indeed, it may be immediately obvious that, other than the scaling of , can be viewed as a PAC-Bayes flatness measure which utilises a very specific posterior distribution localised to . Recall the canonical PAC-Bayes flatness measure is based on
| (24) |
where is a general empirical loss function (which in our case is the sample negative log likelihood) and the “posterior" distribution is often taken to be Gaussian, i.e., . A simple derivation shows us that the quantity in (24), if we use a Gaussian around , reduces approximately to where is the Hessian of the loss, i.e., . However, for singular models, the posterior distribution around , e.g., (10), is decidedly not Gaussian. This calls into question the standard choice of the Gaussian posterior in (24).
Learning capacity. Finally, we briefly discuss concurrent work that measures a quantity related to the learning coefficient. In Chen et al., 2023a , a measure called the learning capacity is proposed to estimate the complexity of a hypothesis class. The learning capacity can be viewed as a finite- version of the learning coefficient; the latter only appears in the limit. Chen et al., 2023a is largely interested in the learning capacity as a function of training size . They discover the learning capacity saturates at very small and large with a sharp transition in between.
Applications. Recently, the LLC estimation method we introduce here has been used to empirically detect “phase transitions" in toy ReLU networks Chen et al., 2023a , and the development of in-context learning in transformers Hoogland et al., (2024).
Appendix F Model complexity vs model-independent complexity
In this paper, we have described the LLC as a measure of “model complexity." It is worth clarifying what we mean here — or rather, what we do not mean. This clarification is in part a response to Skalse, (2023).
We distinguish measures of “model complexity," such as those traditionally found in statistical learning theory, from measures of “model-independent complexity," such as those found in algorithmic information theory. Measures of model complexity, like the parameter count, describe the expressivity or degrees of freedom available to a particular model. Measures of model-independent complexity, like Kolmogorov complexity, describe the complexity inherent to the task itself.
In particular, we emphasize that — a priori — the LLC is a measure of model complexity, not model-independent complexity. It can be seen as the amount of information required to nudge a model towards and away from other parameters. Parameters with higher LLC are more complex for that particular model to implement.
Alternatively, the model is inductively biased444The role of the LLC in inductive biases is only rigorously established for Bayesian learning, but we suspect it also applies for learning with SGD. towards parameters with lower LLC — but a different model could have different inductive biases, and thus different LLC for the same task. This is why it is not sensible to conclude that a bias towards low LLC, would, on its own, explain observed “simplicity bias" in neural networks Valle-Perez et al., (2018) — this is tautological, as Skalse, (2023) noted.
To highlight this distinction, we construct a statistical model where these two notions of complexity diverge. Let be a Kolmogorov-simple function, like the identity function. Let be a Kolmogorov-complex function, like a random lookup table. Then consider the following regression model with a single parameter :
For this model, has a learning coefficient of , whereas has a learning coefficient of . Therefore, despite being more Kolmogorov-simple, it is more complex for to implement — the model is biased towards instead of , and so requires relatively more information to learn.
Yet, this example feels contrived: in realistic deep learning settings, the parameters do not merely interpolate between handpicked possible algorithms, but themselves define an internal algorithm based on their values. That is, it seems intuitively like the parameters play a role closer to “source code" than “tuning constants."
Thus, while in general LLC is not a model-independent complexity measure, it seems distinctly possible that for neural networks (perhaps even models in some broader “universality class"), the LLC could be model-independent in some way. This would theoretically establish the inductive biases of neural networks. We believe this to be an intriguing direction for future work.
Appendix G SGLD-based LLC estimator: minibatch version pseudocode
Input:
-
initialization point:
-
scale:
-
step size:
-
number of iterations: SGLD_iters
-
batch size:
-
dataset of size :
-
averaged log-likelihood function for and arbitrary subset of data:
Output:
Appendix H Recommendations for accurate LLC estimation and troubleshooting
In this section, we collect several recommendations for estimating the LLC accurately in practice. Note that these recommendations are largely based on our experience with LLC estimation for DLN (see Section 5.1) as it is the only realistic model (it being wide and deep) where the theoretical learning coefficient is available.
H.1 Step size
From experience, the most important hyperparameter to the performance and accuracy of the
method is the step size . If the step size is too low, the sampler may not equilibriate, leading to
underestimation. If the step size is too high, the sampler can become numerically unstable,
causing overestimation or even “blowing up" to NaN values.
Manual tuning of the step size is possible. However we strongly recommend a particular diagnostic based on the acceptance criterion for Metropolis-adjusted Langevin dynamics (MALA). This is used to correct numerical errors in traditional MCMC, but here we use it only to detect them.
In traditional (full-gradient) MCMC, numerical errors caused by the step size are completely corrected by a secondary step in the algorithm, the acceptance check or Metropolis correction, which accepts or rejects steps with some probability roughly555Technically, the acceptance probability is based on maintaining detailed balance, not necessarily numerical error, as can be seen in the case of e.g. Metropolis-Hastings. But this is a fine intuition for gradient-based algorithms like MALA or HMC. based on the likelihood of numerical error. The proportion of steps accepted additionally becomes an important diagnostic as to the health of the algorithm: a low acceptance ratio indicates that the acceptance check is having to compensate for high levels of numerical error.
The acceptance probability between step and proposed step is calculated as:
where is the probability density at (in our case, ), and is the probability of our sampler transitioning from to .
In the case of MALA, and so we must explicitly calculate this term. For MALA, it is:
We choose to use MALA’s formula because we are using SGLD, and both MALA and SGLD propose steps using Langevin dynamics. MALA’s formula is the correct one to use when attempting to apply Metropolis correction to Langevin dynamics.
For various reasons, directly implementing such an acceptance check for stochastic-gradient MCMC (while possible) is typically either ineffective or inefficient. Instead we use the acceptance probability merely as a diagnostic.
We recommend tuning the step size such that the average acceptance probability is in the range of 0.9-0.95. Below this range, increase step size to avoid numerical error. Above this range, consider decreasing step size for computational efficiency (to save on the number of steps required). For efficiency, we recommend calculating the acceptance probability for only a fraction of steps — say, one out of every twenty.
Note that since we are not actually using an acceptance check, these acceptance “probabilities" are not really probabilities, but merely diagnostic values.
H.2 Step count and burn-in
The step count for sampling should be chosen such that the sampler has time to equilibriate or “burn in”. Insufficient step count may lead to underestimating the LLC. Excessive step count will not degrade accuracy, but is unnecessarily time-consuming.
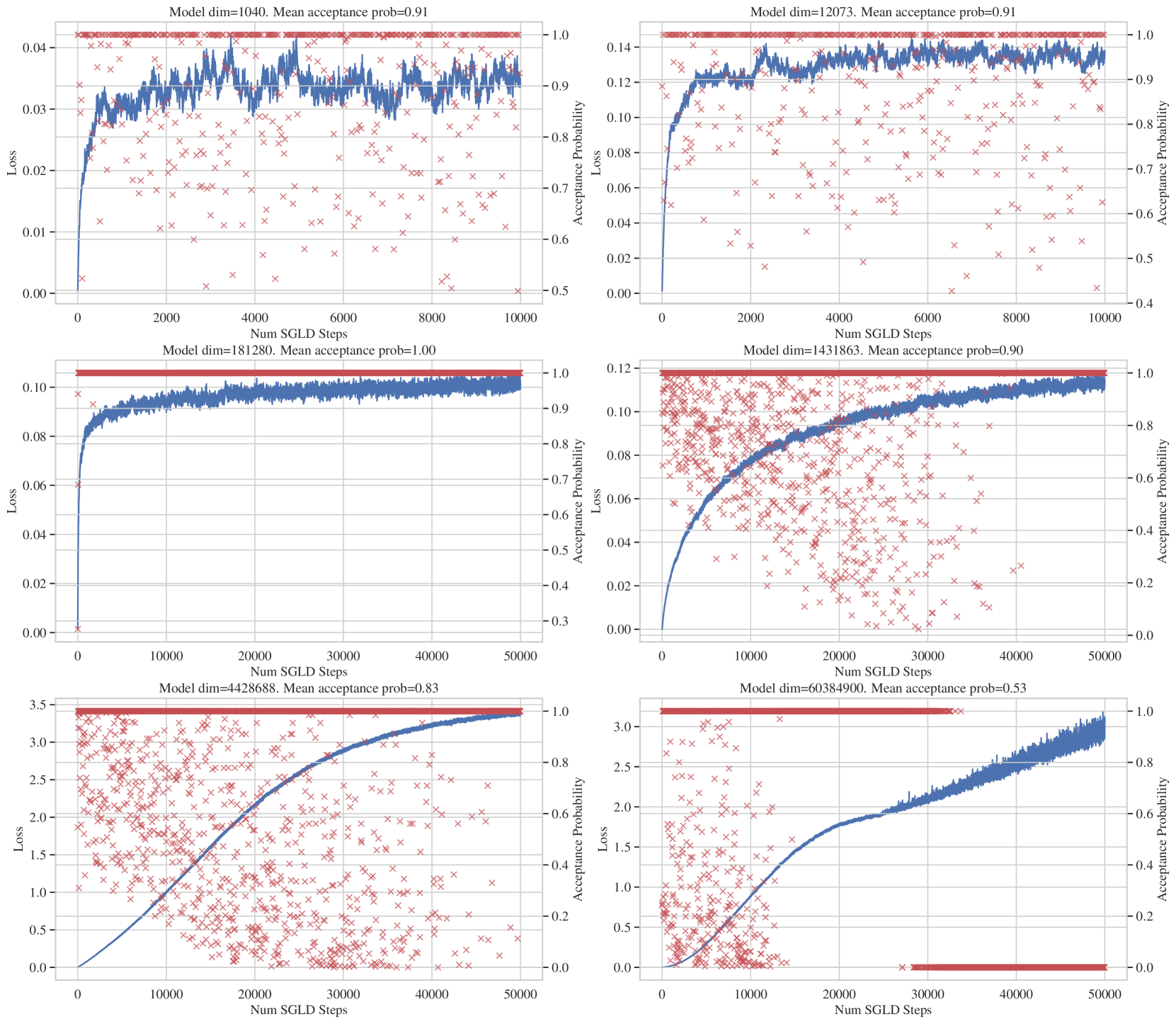
We recommend increasing the number of steps until the loss, , stops increasing after some period of time. This can be done with manual inspection of the loss trace. See Figure H.1 for some examples of loss trace and MALA acceptance probability over SGLD trajectories for DLN model at different scale.
It is worth noting that the loss trace should truly be flat — a slow upwards slope can still be indicative of significant underestimation.
We also recommend that samples during this burn-in period are discarded. That is, loss values should only be tallied once they have flattened out. This avoids underestimation.
H.3 Other issues and troubleshooting
We note some miscellaneous other issues and some troubleshooting recommendations:
-
Negative LLC estimates: This can happen when fails to be near a local minimum of . However even when is a local minimum, we still might get negative LLC estimates if we are not careful. This can happen when the SGLD trajectory wanders to an area with lower loss than the initialization, causing the numerator in (12) to be negative. This could be alleviated by smaller step size or shorter chain length. This, however, risks under-exploration. This can also be alleviated by having larger restoring force . This risks the issue discussed below.
-
Large : An overly concentrated localizing prior ( too large) can overwhelm the gradient signal coming from the log-likelihood. This can result in samples that are different from the posterior, destroying SGLD’s sensitivity to the local geometry.
To sum up, in pathological cases like having SGLD trajectory falling to lower loss region or blowing up beyond machine floating number limits, we recommend keeping small (1.0 to 10.0), gradually lowering the step-size while lengthening the sampling chain so that the loss trace still equilibrates.
Appendix I Learning coefficient of DLN (Aoyagi,, 2024)
A DLN is a feedforward neural network without nonlinear activation. Specifically, a biasless DLN with hidden layers, layer sizes and input dimension is given by:
| (25) |
where is the input vector and the model parameter consist of the weight matrices of shape for . Given a DLN, , (c.f. Equation 25) with hidden layers, layer sizes and input dimension , the associated regression model with additive Gaussian noise is given by
| (26) |
where is some distribution on the input , is the parameter consisting of the weight matrices of shape for and is the variance of the additive Gaussian noise. Let be the density of the true data generating process and be an optimal parameter that minimizes the KL-divergence between and .
Here we shall pause and emphasize that this result gives us the (global) learning coefficient, which is conceptually distinct from the LLC. They are related: the learning coefficient is the minimum of the LLCs of the global minima of the population loss. In our experiments, we will be measuring the LLC at a randomly chosen global minimum of the population loss. While we don’t expect LLCs to differ much among global minima for DLN, we do not know that for certain and it is of independent interest that the estimated LLC can tell us about the learning coefficient.
Theorem 1 (DLN learning coefficient, Aoyagi,, 2024).
Let be the rank of the linear transformation implemented by the true DLN, and set , for . There exist a subset of indices, with cardinality that satisfy the following conditions:
Assuming that the DLN truth-model pair satisfies the relatively finite variance condition (Appendix A.1), their learning coefficient is then given by
As we mention in the introduction, trained neural networks are less complex than they seem. It is natural to expect that this, if true, is reflected in deep networks having more degenerate (good parameters has higher volume) loss landscape. With the theorem above, we are given a window into the volume scaling behaviour in the case of DLNs, allowing us to investigate an aspect of this hypothesis.
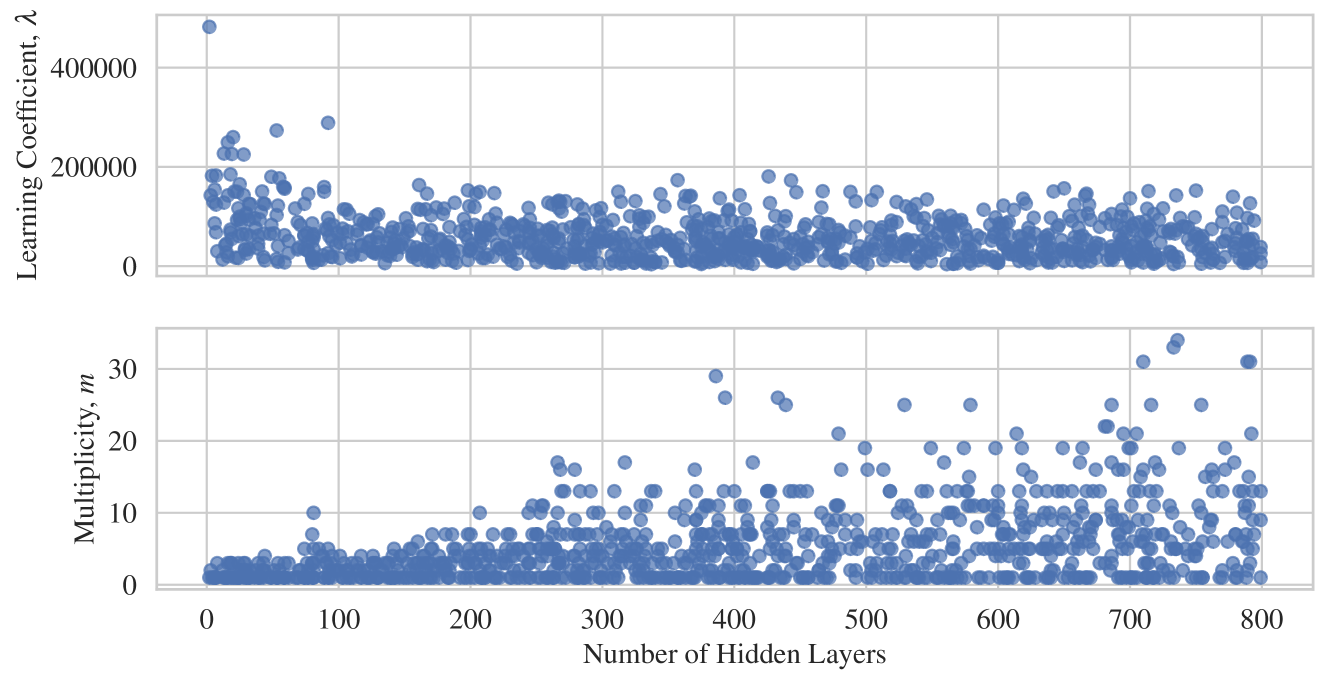
Figure I.1 shows the the true learning coefficient, , and the multiplicity, , of many randomly drawn DLNs with different numbers of hidden layers. Observe that decreases with network depth.
This plot is generated by creating networks with 2-800 hidden layers, with width randomly drawn from 100-2000 including the input dimension. The overall rank of the DLN is randomly drawn from the range of zero to the maximum allowed rank, which is the minimum of the layer widths. See also Figure 1 in Aoyagi, (2024) for more theoretical examples of this phenomenon.
Appendix J Experiment: DLN
We compare the estimated against theoretical (with being a randomly generated true parameter), by randomly generating many DLNs with different architectures and model sizes that span several orders of magnitude (OOM). Each DLN is constructed randomly, as follows. Draw an integer as the number of hidden layers, where denotes the discrete uniform distribution on the finite set . Then, draw layer size for each where denotes the input dimension. The weight matrix for layer is then a matrix with each matrix element independently sampled from (random initialization). To obtain a more realistic true parameter, with probability , each matrix is modified to have a random rank of . For each DLN generated, a corresponding synthetic training dataset of size is generated to be used in SGLD sampling.
The configuration values are chosen differently for separate set of experiments with model size targeting DLN size of different order of magnitude. See Table 1 for the values used in the experiments. SGLD hyperparameters , , and number of steps are chosen to suit each set of experiments according to our recommendations outlined in Appendix H. The exact hyperparameter values are given in the following section.
We emphasize that hyperparameters must be tuned independently for different model sizes. In particular, the required step size for numerical stability tends to decrease for larger models, forcing a compensatory increase in the step count. See Table 1 for an example of this tuning with scale.
Future work using e.g. -parameterization Yang et al., (2022) may be able to alleviate this issue.
J.1 Hyperparameters and further details
As described in the prior section, the experiments shown in Figure 4 consist of randomly constructed DLNs. For each target order of magnitude of DLN parameter count, we randomly sample the number of layers and their widths from a different range. We also use a different set of SGLD hyperparameter chosen according to the recommendation made in Section H. Configuration values that varies across OOM are shown in Table 1 and other configurations are as follow
-
Batch size used in SGLD is 500.
-
The amount of burn-in steps used for SGLD samples is set to 90% of total SGLD chain length, i.e. only the last 10% of SGLD samples are used in estimating the LLC.
-
The parameter is set to .
-
For each DLN, with a chosen true parameter , a synthetic dataset, is generated by randomly sampling each element of the input vector uniformly from the interval and set the output as , which effectively means we are setting a very small noise variance .
-
For LLC estimation done at a trained parameter instead of the true parameter (shown in right plot in Figure 4), the network is first trained using SGD with learning rate 0.01 and momentum 0.9 for 50000 steps.
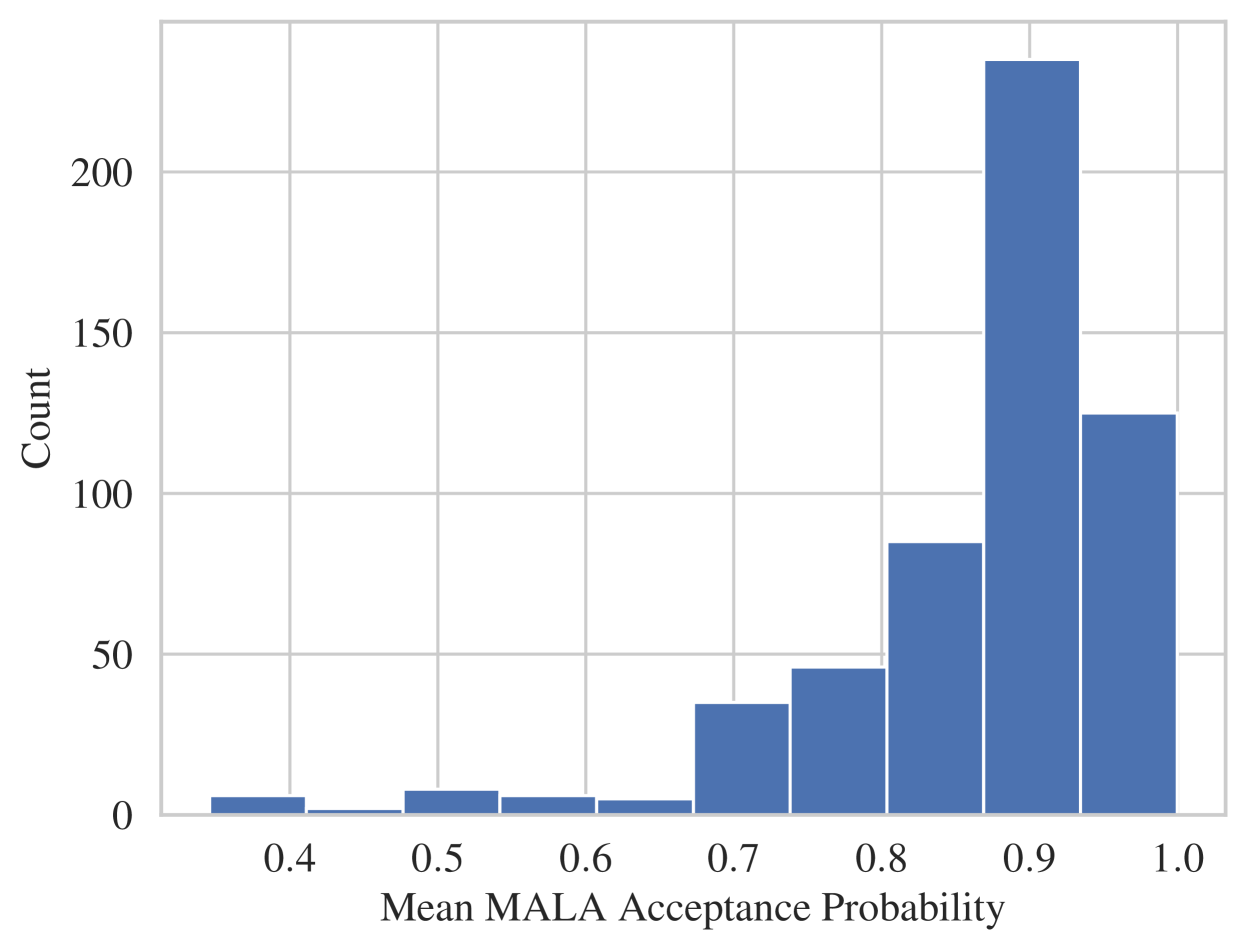
For each target OOM, a number of different experiments are run with different random seeds. The number of such experiment is determined by our compute resources and is reported in Table 1 with some experiment failing due to SGLD chains “blowing up” (See discussion in Appendix H) for the SGLD hyperparameters used. Figure J.3 shows that there is a left tail to the mean MALA acceptance rate distribution that hint at instability in SGLD chains encountered in some estimation run.
| OOM | Num layers, - | Widths, - | Num SGLD steps | Num experiments | ||
|---|---|---|---|---|---|---|
| 1k | 2-5 | 5-50 | 10k | 99 | ||
| 10k | 2-10 | 5-100 | 10k | 100 | ||
| 100k | 2-10 | 50-500 | 50k | 100 | ||
| 1M | 5-20 | 100-1000 | 50k | 99 | ||
| 10M | 2-20 | 500-2000 | 50k | 93 | ||
| 100M | 2-40 | 500-3000 | 50k | 54 |
J.2 Additional plots for DLN experiments
-
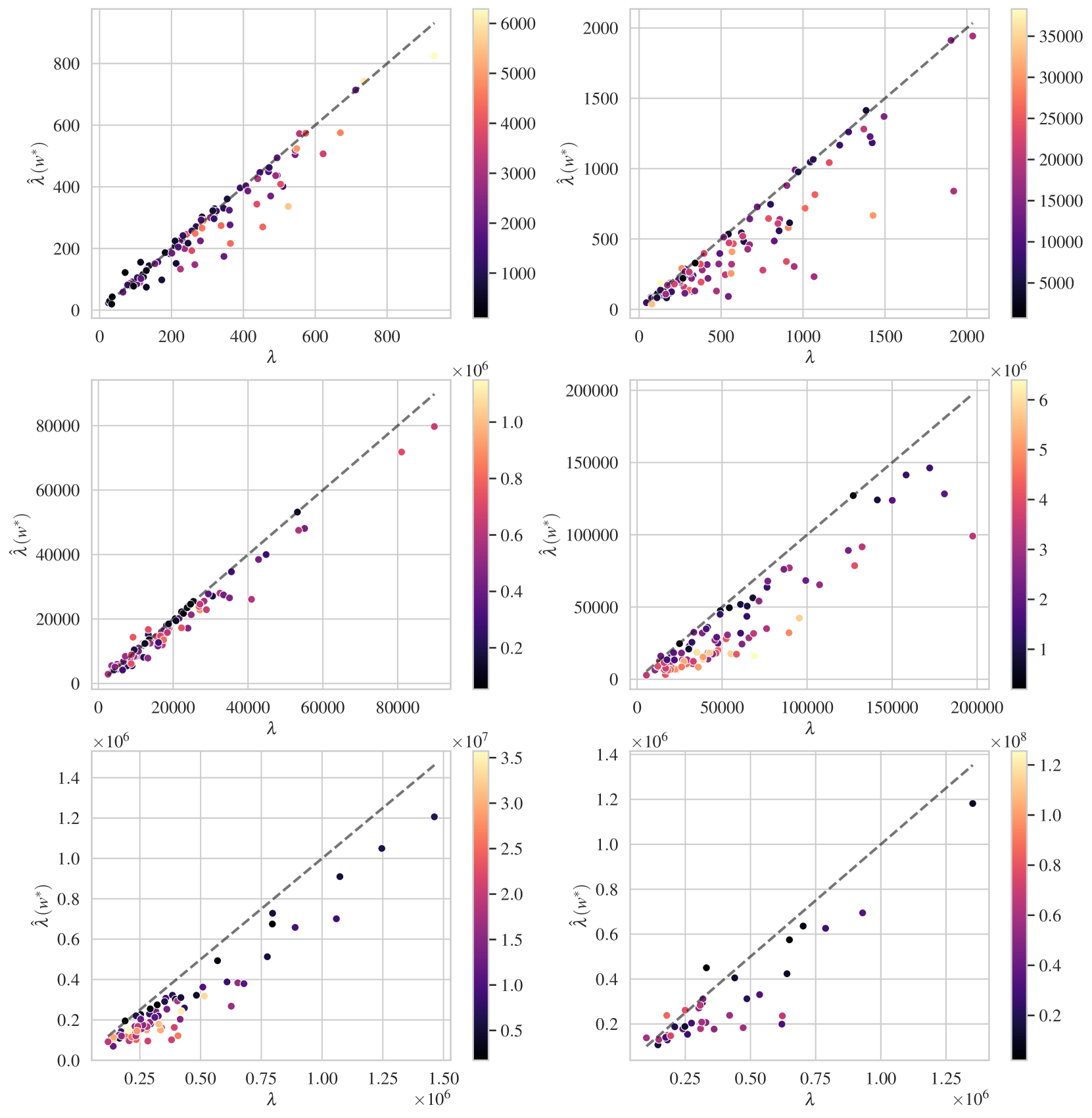
Figure J.2 shows the relative error across multiple orders of magnitude of DLN model size.
Appendix K Experiment: LLC for ResNet
This section provides details for the experiments where we aimed to investigate how LLC vary over neural network training with different training configuration. These experiments parallel those performed in Dherin et al., (2022) who propose thegeometric complexity measure.
We train ResNet18 (He et al.,, 2016) on the CIFAR10 dataset (Krizhevsky,, 2009) using SGD with cross-entropy loss. We vary SGD hyperparameters such as learning rate, batch size, momentum and -regularization rate and track the resulting LLC estimates over evenly spaced checkpoints of SGD iterations.
For the LLC estimates to be comparable, we need to ensure that the SGLD hyperparameters used in the LLC algorithm is the same. To this end, for every set of experiments where we vary a single optimizer hyperparameter, we first perform a calibration run to select SGLD hyperparameters according to the recommendation out lined in Appendix H. Once selected, this set of SGLD hyperparameter is then used for all LLC estimation within the set of experiments. That include the LLC estimation for every checkpoint of every ResNet18 training run for different optimizer configuration. Also following the same recommendation, we also burn away 90% of the sample trajectory and only use last 10% of samples. We also note that, since the SGLD hyperparameters are not tuned for all experiments within a single set, there are possibilities of negative LLC estimates or divergent SGLD chains. See Appendix H.3 for discussion on such cases and how to troubleshoot them. We manually remove these cases. They are rare enough that they do not change the LLC curves, just widen the error bars (confidence intervals) due to having less repeated experiments.
Each experiment is repeated with 5 different random seeds. While the model architecture and
dataset (including the train-test split) is fixed, other factors like the network
initialization, training trajectories and SGLD samples are randomized. In each plot, the error
bars show the 95% confidence intervals over 5 repeated experiments of the statistics plotted.
The error bars were calculated using the inbuilt error bar function to Python Seaborn library (Waskom,, 2021) plotting function, seaborn.lineplot(..., errorbar=("ci", 95), ...).
K.1 Details for main text Figures 1
For experiments that vary the learning rate in Figure 1 (top), for each learning rate value in we run SGD without momentum with a fixed batch size of 512 for 30000 iterations. LLC estimations were performed every 1000 iterations with SGLD hyperparameters as follow: step size , chain length of 3000 iterations, batch size of 2048 and .
For experiments that vary the batch size in Figure 1 (middle), for each batch size value in we run SGD without momentum with a fixed learning rate of 0.01 for 100000 iterations. LLC estimations were performed every 2500 iterations with SGLD hyperparameters as follow: step size , chain length of 2500 iterations, batch size of 2048 and .
For experiments that vary the SGD momentum in Figure 1 (bottom), for each momentum value in we run SGD with momentum with a fixed learning rate of 0.05 and a fixed batch size of 512 for 20000 iterations. LLC estimations were performed every 1000 iterations with SGLD hyperparameters as follow: step size , chain length of 3000 iterations, batch size of 2048 and .
K.2 Additional ResNet18 + CIFAR10 LLC experiments
Experiments using SGD with momentum
We repeat the experiments varying learning rate and batch size shown in Figure 1 (top and middle) in the main text, but this time we train ResNet18 on CIFAR10 using SGD with momentum instead. The results are shown in Figure K.1 and the experimental details are as follow:
-
For experiments that varies the learning rate (top), for each learning rate value in we run SGD with momentum of 0.9 with a fixed batch size of 512 for 30000 iterations. LLC estimations were performed every 1000 iterations with SGLD hyperparameters as follow: step size , chain length of 3000 iterations, batch size of 2048 and .
-
For experiments that varies the batch size (bottom), for each batch size value in we run SGD with momentum of 0.9 with a fixed learning rate of 0.01 for 100000 iterations. LLC estimations were performed every 2500 iterations with SGLD hyperparameters as follow: step size , chain length of 2500 iterations, batch size of 2048 and .
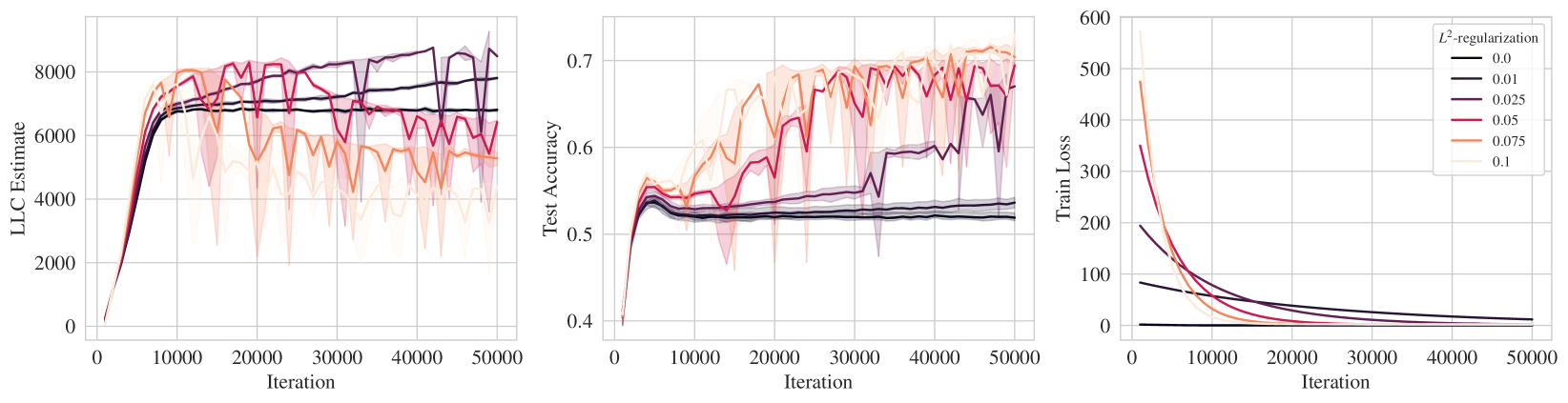
Explicit -regularization
We also run analogous experiments using explicit -regularization. We trained ResNet18 on CIFAR10 dataset using SGD both with and without momentum using the usual cross-entropy loss but with an added -regularization term, where denote the network weight vector and is the regularization rate hyperparameter that we vary in this set of experiments. Similar to other experiments in this section, we track LLC estimates over evenly spaced training checkpoints. However, it is worth noting that the loss function used for SGLD sampling as part of the LLC estimation is the original cross-entropy loss function without the added -regularization term.
The results are shown in Figure K.2 and the details are as follow:
-
For the experiment with momentum (Figure K.2 top), for each regularization rate , we run SGD with momentum of 0.9 with a fixed learning rate of 0.0005 and batch size of 512 for 15000 iterations. LLC estimations were performed every 500 iterations with SGLD hyperparameters as follow: step size , chain length of 2000 iterations, batch size of 2048 and .
-
For the experiment without momentum (Figure K.2 bottom), for each regularization rate , we run SGD without momentum with a fixed learning rate of 0.001 and batch size of 512 for 50000 iterations. LLC estimations were performed every 1000 iterations with SGLD hyperparameters as follow: step size , chain length of 2000 iterations, batch size of 2048 and .
Appendix L Additional Experiment: LLC for language model
The purpose of this experiment is simply to verify that the LLC can be consistently estimated for a transformer trained on language data. In Figure L.1, we show the LLC estimates for at the end of training over a few training runs. We see the LLC estimates are a small fraction of the 3.3m total parameters. We also notice that the value of the LLC estimates are remarkably stable over multiple training runs. See Appendix L for experimental details.
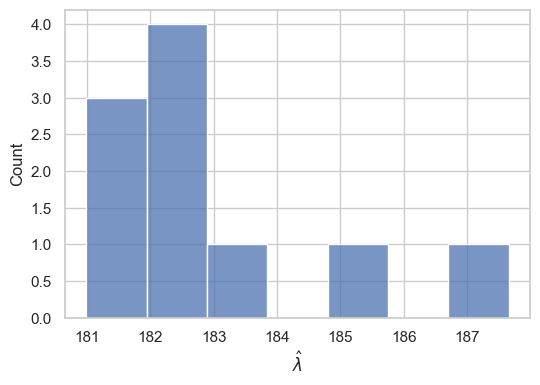
We trained a two-layer attention-only (no MLP layers) transformer architecture on a resampled subset of the Pile dataset Gao et al., (2020); Xie et al., (2023) with a context length of 1024, a residual stream dimension of , and 8 attention heads per layer. The architecture also uses a learnable Shortformer embedding Press et al., (2021) and includes layer norm layers. Additionally, we truncated the full GPT-2 tokenizer, which has a vocabulary of around 50,000 tokens, down to the first 5,000 tokens in the vocabulary to reduce the size of the model. The resulting model has a total parameter count of . We instantiated these models using an implementation provided by TransformerLens Nanda and Bloom, (2022).
We trained 10 different seeds over a single epoch of 50,000 steps with a minibatch size of 100, resulting in about 5 billion tokens used during training for each model. We used the AdamW optimizer with a weight decay value of and a learning rate of with no scheduler.
We run SGLD-based LLC estimation once at the end of training for each seed at a temperature of . We set and . We take samples over 20 SGLD chains with 200 draws per chain using a validation set.
Appendix M Additional Experiment: MALA versus SGLD
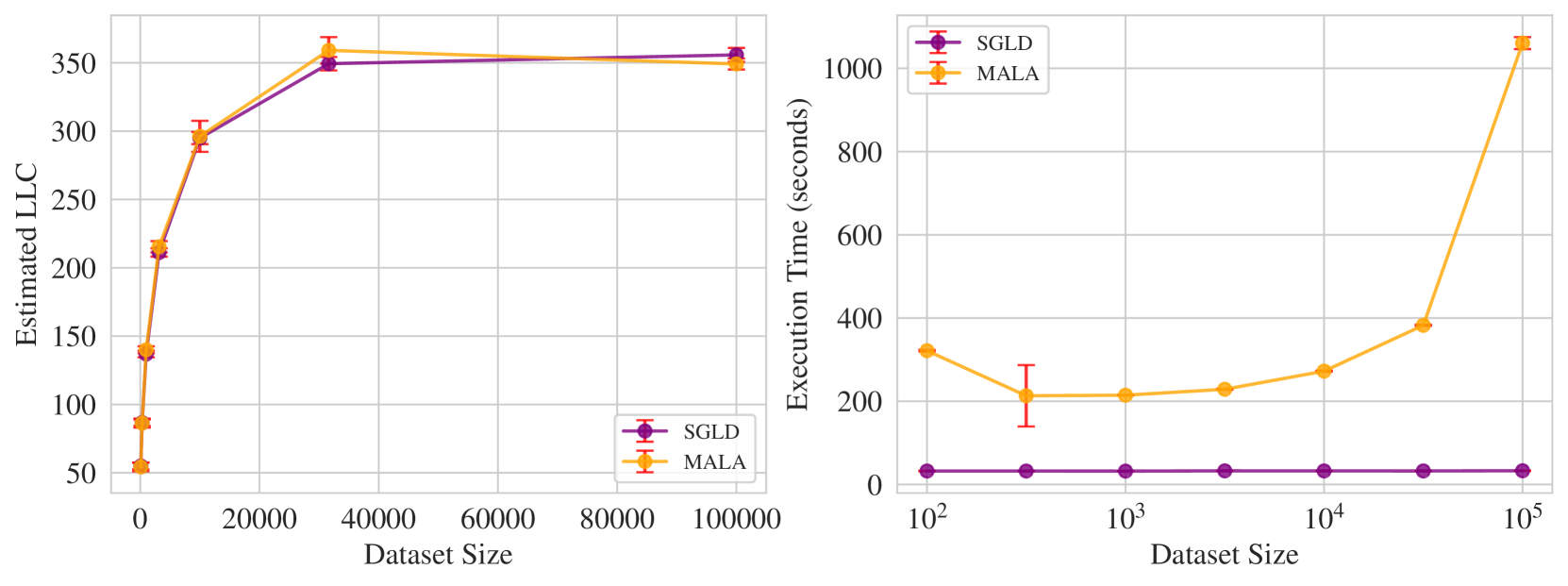
Here we verify empirically that our SGLD-based LLC estimator (Algorithm 1) does not suffer from using minibatch loss for both SGLD sampling and LLC calculation. Specifically, we compare to LLC estimation via Equation 12 and the Metropolis-adjusted Langevin Algorithm (MALA), a standard gradient-based MCMC algorithm Roberts and Rosenthal, (1998). Notice that this comparison rather stacks the odds against the minibatch-version SGLD-based LLC estimator in Algorithm 1 so that it is all the more surprising we see such good results below.
We test with a two-hidden-layer ReLU network with ten inputs, ten outputs, and twenty neurons per hidden layer. Denote the inputs by , the parameters by , and the output of this network . The data are generated to create a “realizable" data generating process, with “true parameter" : inputs are generated from a uniform distribution, and labels are (noiselessly) generated based on the true network, so that .
Hyperparameters and experimental details are as follows. We sweep dataset size from 100 to 100000, and compare our LLC estimator and the MALA-based one. For all dataset sizes, SGLD batch size was set to 32 and , and MALA and SGLD shared the same true parameter (set at random according to a normal distribution). Both MALA and SGLD used a step size of 1e-5 and the asymptotically optimal inverse temperature . Experiments were run on CPU.
Appendix N Additional Experiment: SGD versus eSGD
We fit a two hidden-layer feedforward ReLU network with 1.9m parameters to MNIST using two stochastic optimizers: SGD and entropy-SGD (Chaudhari et al.,, 2019). We choose entropy-SGD because its objective is to minimize over , so we expect that the local minima found by entropy-SGD will have lower .
Figure N.1 shows the LLC estimates for at the end of training, optimized by either entropy-SGD or standard SGD. Notice the LLC estimates, for both stochastic optimizers, are on the order of 1000, much lower than the 1.9m number of parameters in the ReLU network.
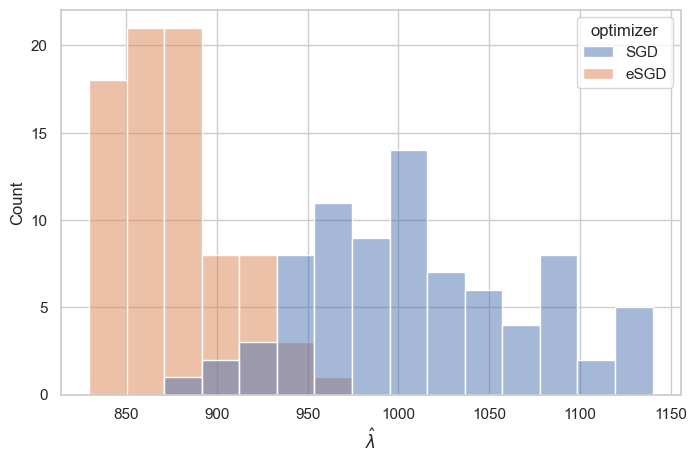
Figure N.1 confirms our expectation that entropy-SGD finds local minima with lower LLC, i.e., entropy-SGD is attracted to more degenerate (simpler) critical points than SGD. Interestingly Figure N.1 also reveals that the LLC estimate has remarkably low variance over the randomness of the stochastic optimizer. Finally it is noteworthy that the LLC estimate of a learned NN model for both stochastic optimizers is, on average, a tiny percentage of the total number of weights in the NN model: .
In this experiment, we trained a feedforward ReLU network on the MNIST dataset Deng, (2012). The dataset consists of training samples and testing samples. The network is designed with 2 hidden layers having sizes , and it contains a total of parameters.
For training, we employed two different optimizers, SGD and entropy-SGD, minimizing cross-entropy loss. Both optimizers are set to have learning rate of , momentum parameter at and batch size of . SGD is trained with Nesterov look-ahead gradient estimator. The number of samples used by entropy-SGD for local free energy estimation is set to . The network is trained for epochs. The number of epochs is chosen so that the classification error rate on the training set falls below .
The hyperparameters used for SGLD are as follows: is set to , chain length to and the minibatch size 512, and . We repeat each SGLD chain times to compute the variance of estimated quantities and also as a diagnostic tool, a proxy for estimation stability.
Appendix O Additional Experiment: scaling invariance
In Appendix C, we show theoretically that the theoretical LLC is invariant to local diffeomorphism. Here we empirically verify that our LLC estimator (with preconditioning) is capable of satisfying this property in a specific easy-to-test case (though we do not test it in general).
The function implemented by a feedforward ReLU networks is invariant to a type of reparameterization known as rescaling symmetry. Invariance of other measures to this symmetry is not trivial or automatic, and other geometric measures like Hessian-based basin broadness have been undermined by their failure to stay invariant to these symmetries Dinh et al., (2017).
For simplicity, suppose we have a two-layer ReLU network, with weights and biases . Then rescaling symmetry is captured by the following fact, for some arbitrary scalar :
That is, we may choose new parameters without affecting the input-output behavior of the network in any way. This symmetry generalizes to any two adjacent layers in ReLU networks of arbitrary depth.
Given that these symmetries do not affect the function implemented by the network, and are present globally throughout all of parameter space, it seems like these degrees of freedom are “superfluous", and should ideally not affect our tools. Importantly, this is the case for the LLC.
We verify empirically that this property also appears to hold for our LLC estimator, when proper preconditioning is used.
O.1 Preconditioned SGLD
We must slightly modify our SGLD sampler to perform this experiment tractably. This is because applying rescaling symmetry makes the loss landscape significantly anisotropic, forcing prohibitively small step sizes with the original algorithm.
Thus we add preconditioning to the SGLD sampler from Section 4.4, with the only modification being a fixed preconditioning matrix :
| (27) |
In the experiment to follow, this preconditioning matrix is hardcoded for convenience, but if this algorithm is to be used in practice, the preconditioning matrix must be learned adaptively using standard methods for adaptive preconditioning (Haario et al.,, 1999).
O.2 Experiment
We take a small feedforward ReLU network, and rescale two adjacent layers in the network by in the fashion described above. We vary the value of across eight orders of magnitude and measure the estimated LLC using Eq 27 for SGLD sampling and Eq 12 for calculating LLC from samples.666Note that this means that we are not using Algorithm 1 here, both because of preconditioned SGLD and because we are calculating LLC using full-batch loss instead of mini-batch loss.
Crucially, we must use preconditioning here so as to avoid prohibitively small step size requirements. In this case, the preconditioning matrix is set manually, to be a diagonal matrix with entries for parameters corresponding to and , entries for , and entries otherwise.777In practical situations, the preconditioning matrix cannot be set manually, and must be learned adaptively. Standard methods for adaptive preconditioning exist in the MCMC literature Haario et al., (2001, 1999).
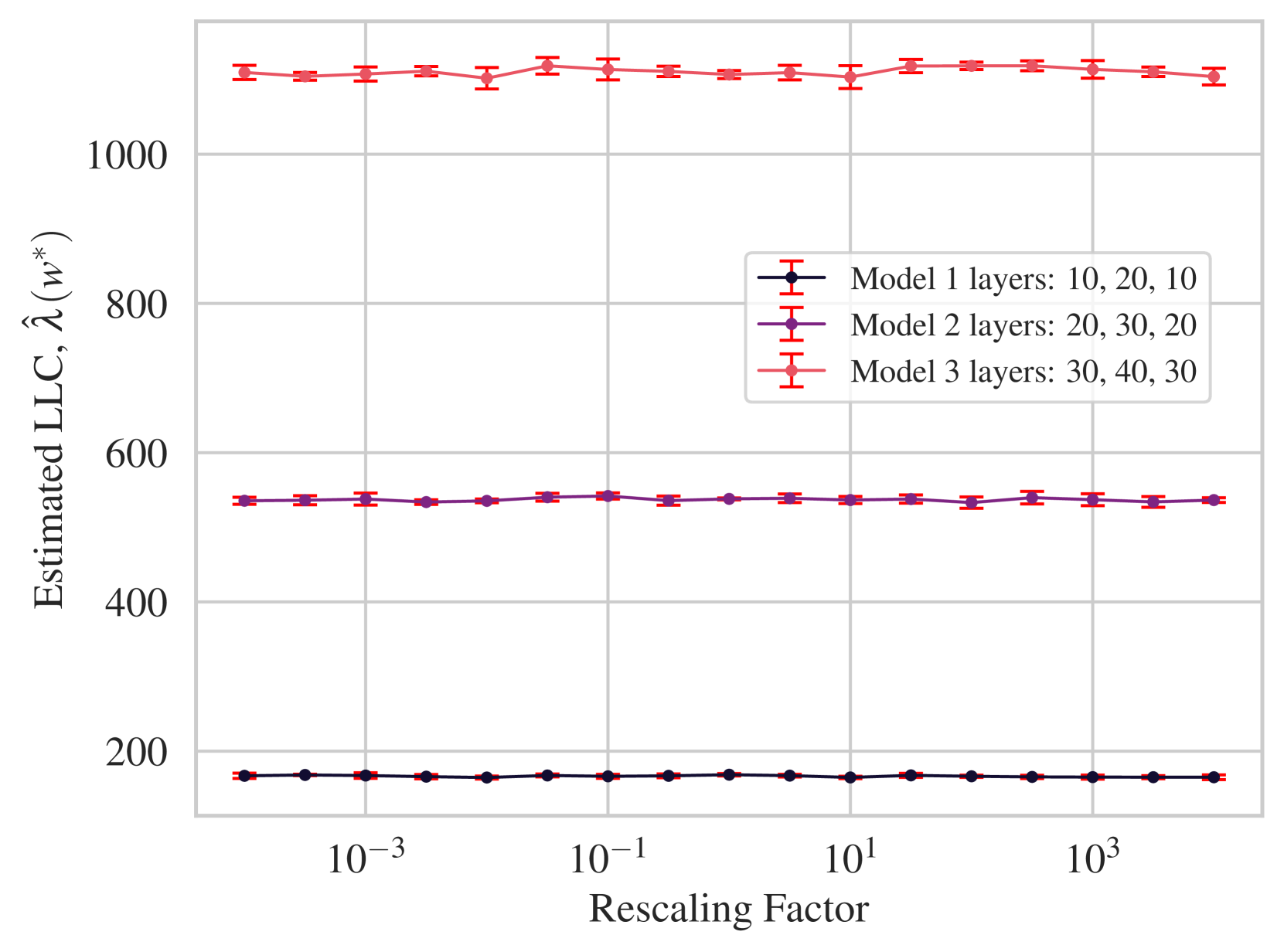
The results can be found in Figure O.1. We conclude that LLC estimation appears invariant to ReLU network rescaling symmetries.
Appendix P Compute resources disclosure
Specific details about each type of experiment we carried out are listed below. There addition compute resources required for finding suitable SGLD hyperparameters for LLC estimation, but they did not constitute significant difference to overall resource requirement.
ResNet18 + CIFAR10 experiments.
Each experiment, i.e. training a ResNet18 for the reported number of iteration and performing LLC estimation for the stated number of checkpoints, is run on a node with either a single V100 or A100 NVIDIA GPU depending on availability hosted on internal HPC cluster with 2 CPU cores and 16GB memory allocated. No significant storage required. Each experiment took between a few minutes to 3 hours depending on the configuration (mean: 87.6 minutes, median: 76.7 minutes).
Estimated total compute is 287 GPU hours spread across 208 experiments.
DLN experiments.
Each experiment, either estimating LLC at the true parameter or at a trained SGD parameter (thus require training), is run on a single A100 NVIDIA GPU node hosted on internal HPC cluster with 2 CPU cores and no more than 8GB memory allocated. No significant storage required. Each experiment took less than 15 minutes.
Estimated total compute is 150 GPU hours: 600 experiments (including failed ones) each around 15 GPU minutes.
MNIST experiments.
Each repetition of training a feedforward ReLU network using SGD or eSGD optimizer on MNIST data and estimating the LLC at the end of training is run on a single A100 NVIDIA GPU node hosted on internal HPC cluster with 8 CPU cores and no more than 16GB memory allocated. No significant storage required. Each experiment took less than 10 minutes.
Estimated total compute is 27 GPU hours: 2 sets of 80 repetitions, 10 GPU minutes each.
Language model experiments.
Training the language model and estimating its LLC at the last checkpoint took around 30 minutes on Google Colab on a single A100 NVIDIA GPU with 84GB memory and 1 CPU allocated. The storage space used for the training data is around 27GB.
Estimated total compute is 5 GPU hours: 10 repetitions of 30 GPU minutes each.
Cite as
@inproceedings{lau2025local,
author = {Edmund Lau and Zach Furman and George Wang and Daniel Murfet and Susan Wei},
title = {The Local Learning Coefficient: A Singularity-Aware Complexity Measure},
booktitle = {Proceedings of the 28th International Conference on Artificial Intelligence and Statistics},
year = {2025},
editor = {Li, Yingzhen and Mandt, Stephan and Agrawal, Shipra and Khan, Emtiyaz},
volume = {258},
series = {Proceedings of Machine Learning Research},
pages = {244--252},
month = {03--05 May},
publisher = {PMLR},
url = {https://proceedings.mlr.press/v258/lau25a.html},
pdf = {https://raw.githubusercontent.com/mlresearch/v258/main/assets/lau25a/lau25a.pdf},
abstract = {Deep neural networks (DNN) are singular statistical models which exhibit complex degeneracies. In this work, we illustrate how a quantity known as the learning coefficient introduced in singular learning theory quantifies precisely the degree of degeneracy in deep neural networks. Importantly, we will demonstrate that degeneracy in DNN cannot be accounted for by simply counting the number of 'flat' directions.}
}