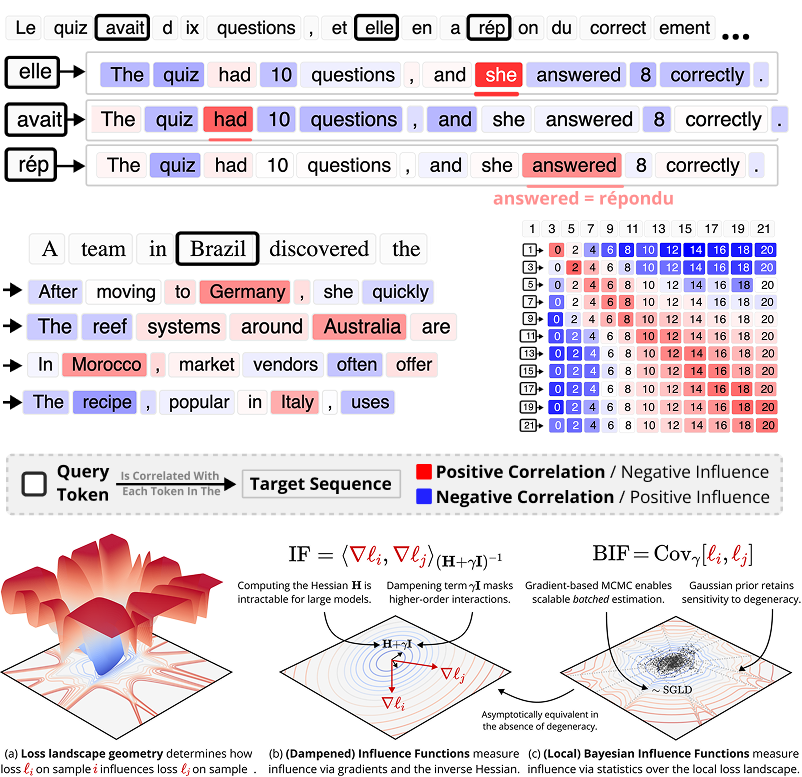
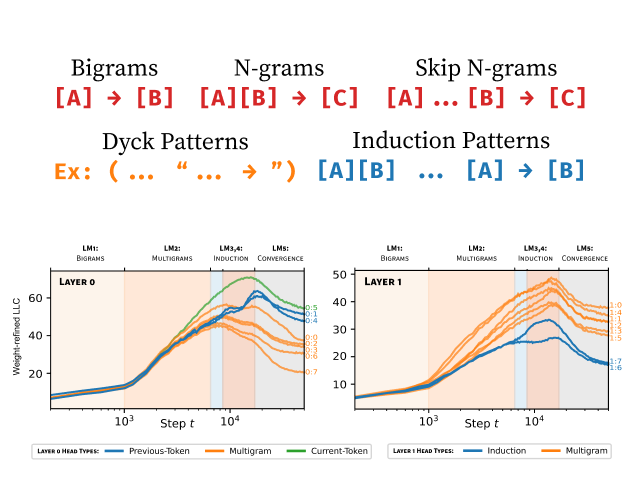
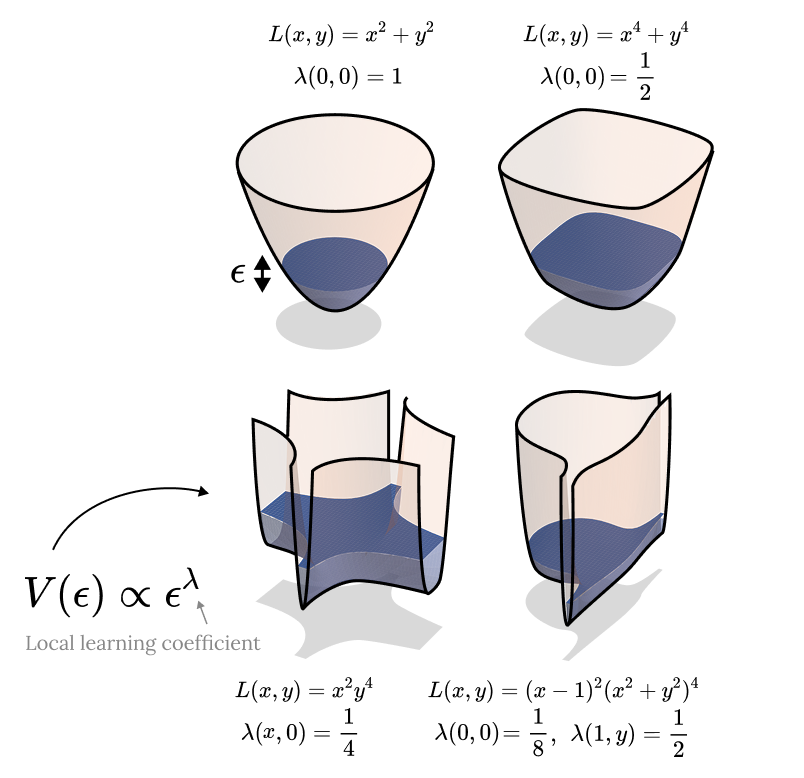
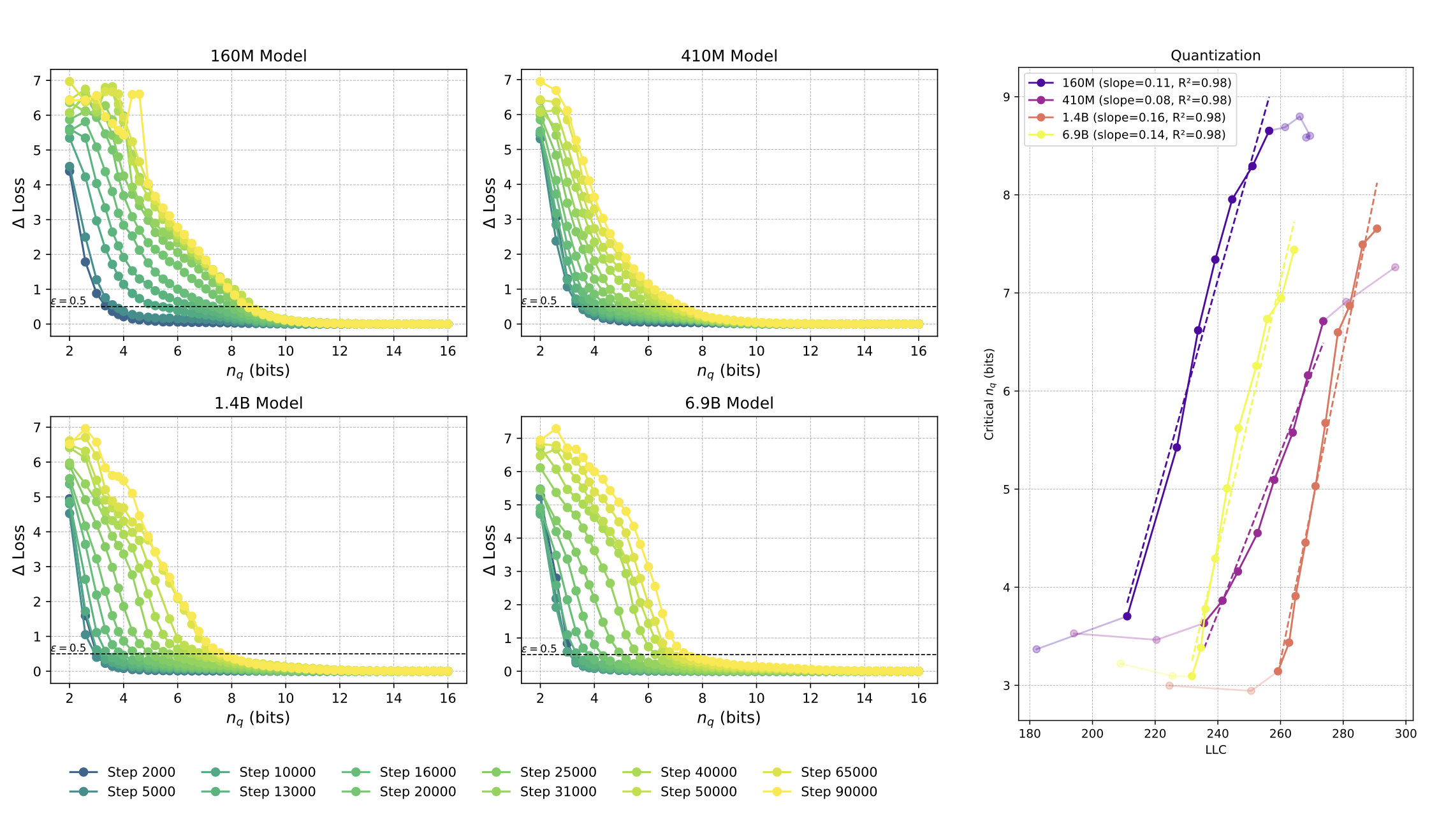
Spectroscopy at Scale: Finding Interpretable Structure in Pythia-1.4B
Murfet et al.
Susceptibilities as an interpretability technique at 1B+ scale: show and tell from Pythia-1.4B.
Timaeus is merging into Resolution. Read the announcement
We use singular learning theory to study how training data shapes model behavior.
We use this understanding to develop new tools for AI safety. Read more.
Murfet et al.
Wang and Murfet
Mechanistic interpretability aims to understand how neural networks generalize beyond their training data by reverse-eng…
Gordon et al.
Spectroscopy infers the internal structure of physical systems by measuring their response to perturbations.
Elliott et al.
Urdshals et al.
Lee et al.
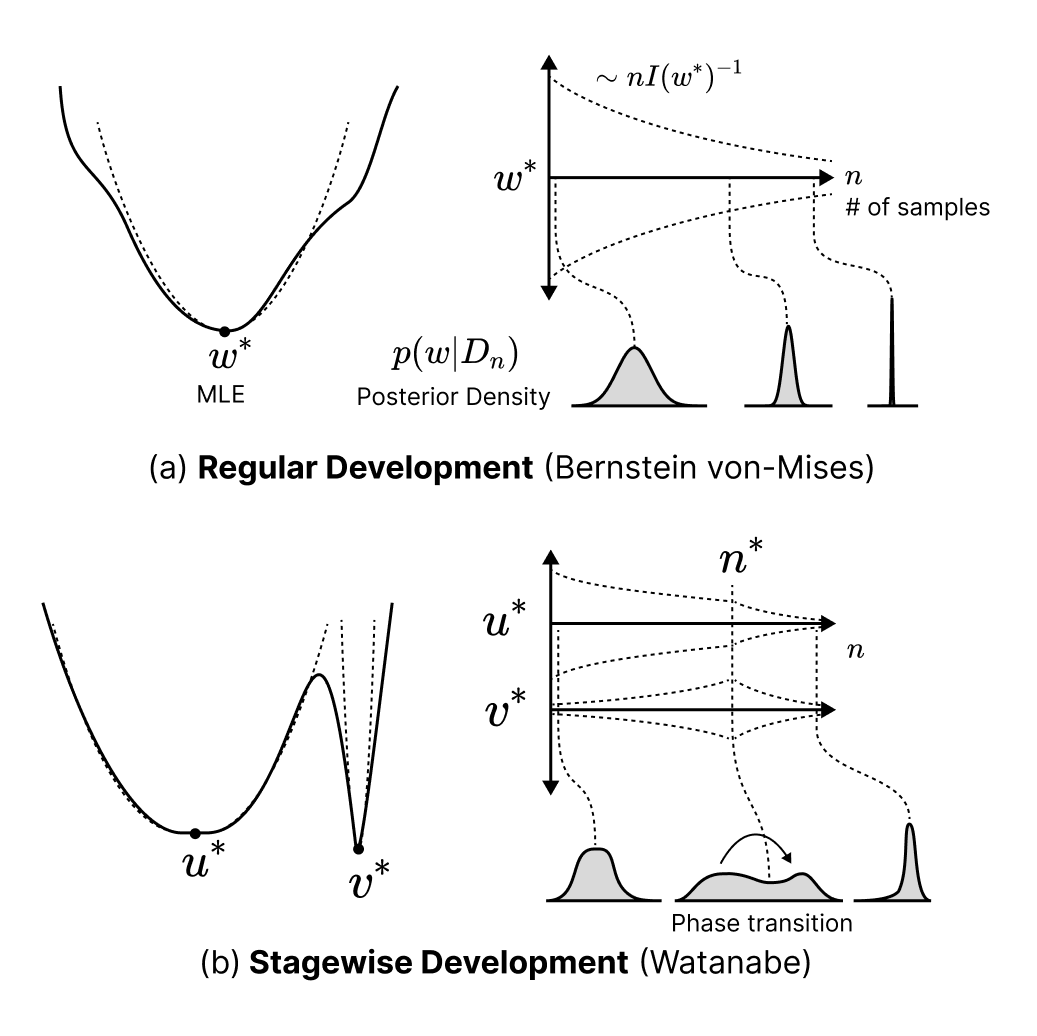
Adam et al.
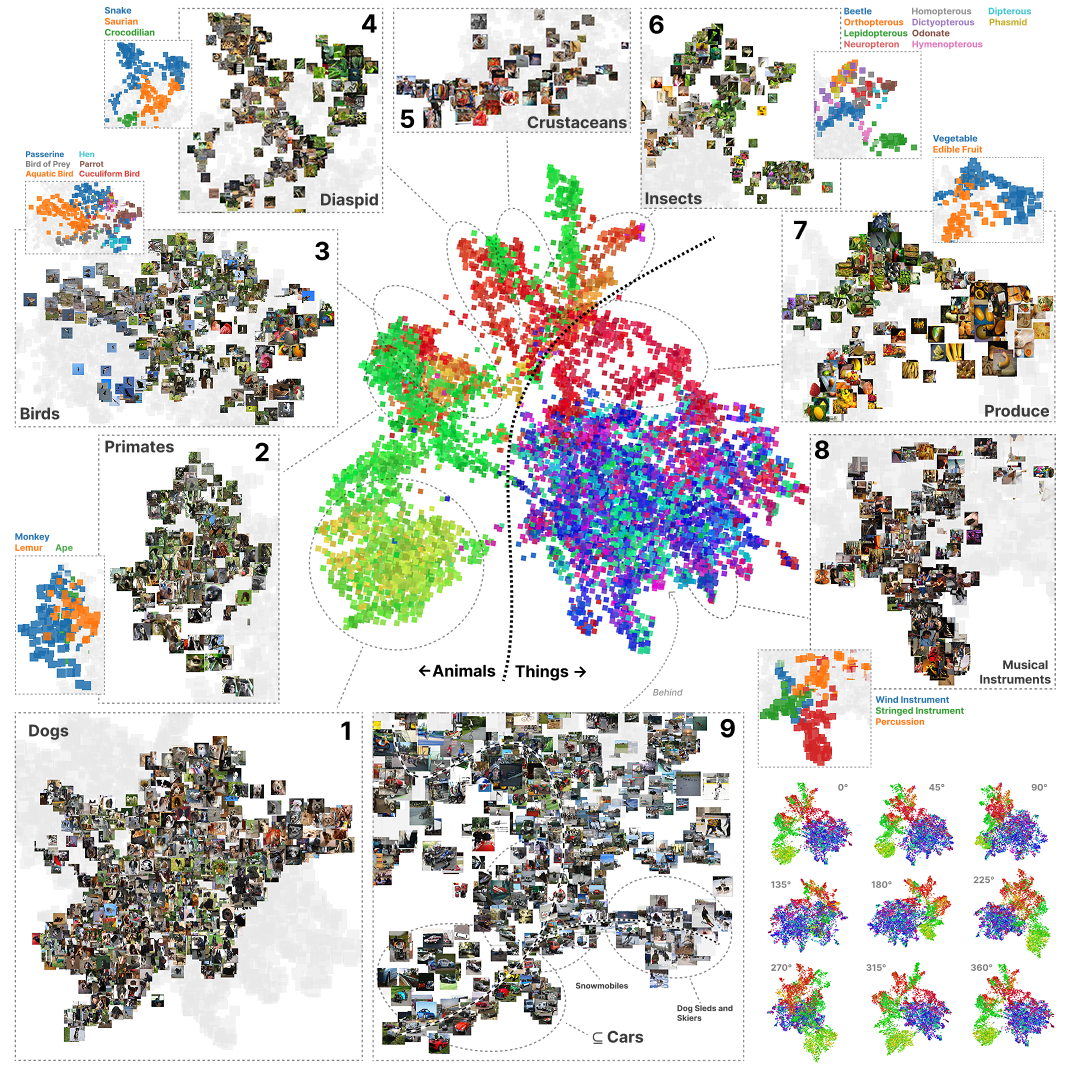
Baker et al.
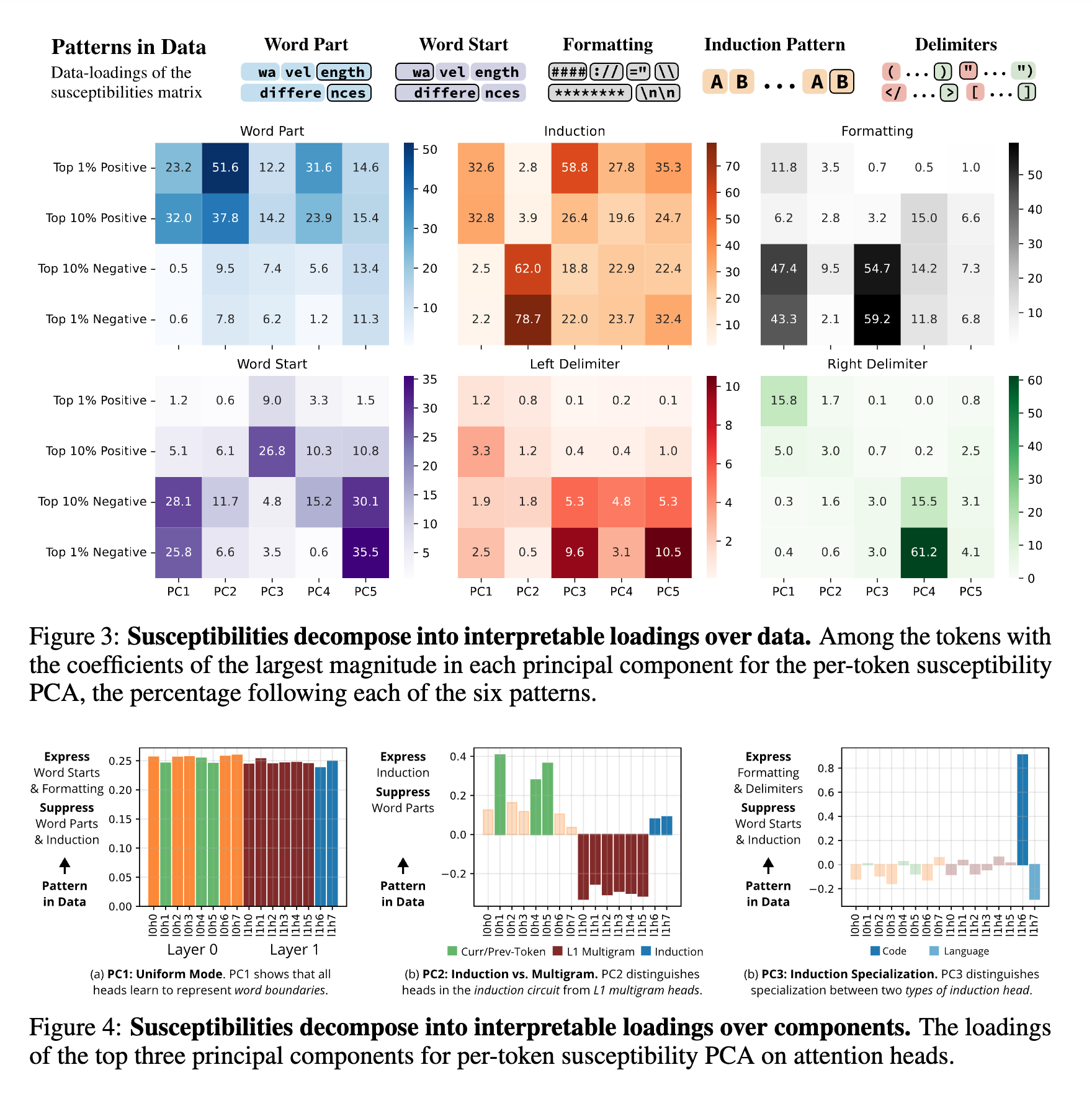
Chen and Murfet
We develop a geometric account of sequence modelling that links patterns in the data to measurable properties of the los…
Murfet and Troiani
We develop a correspondence between the structure of Turing machines and the structure of singularities of real analytic…
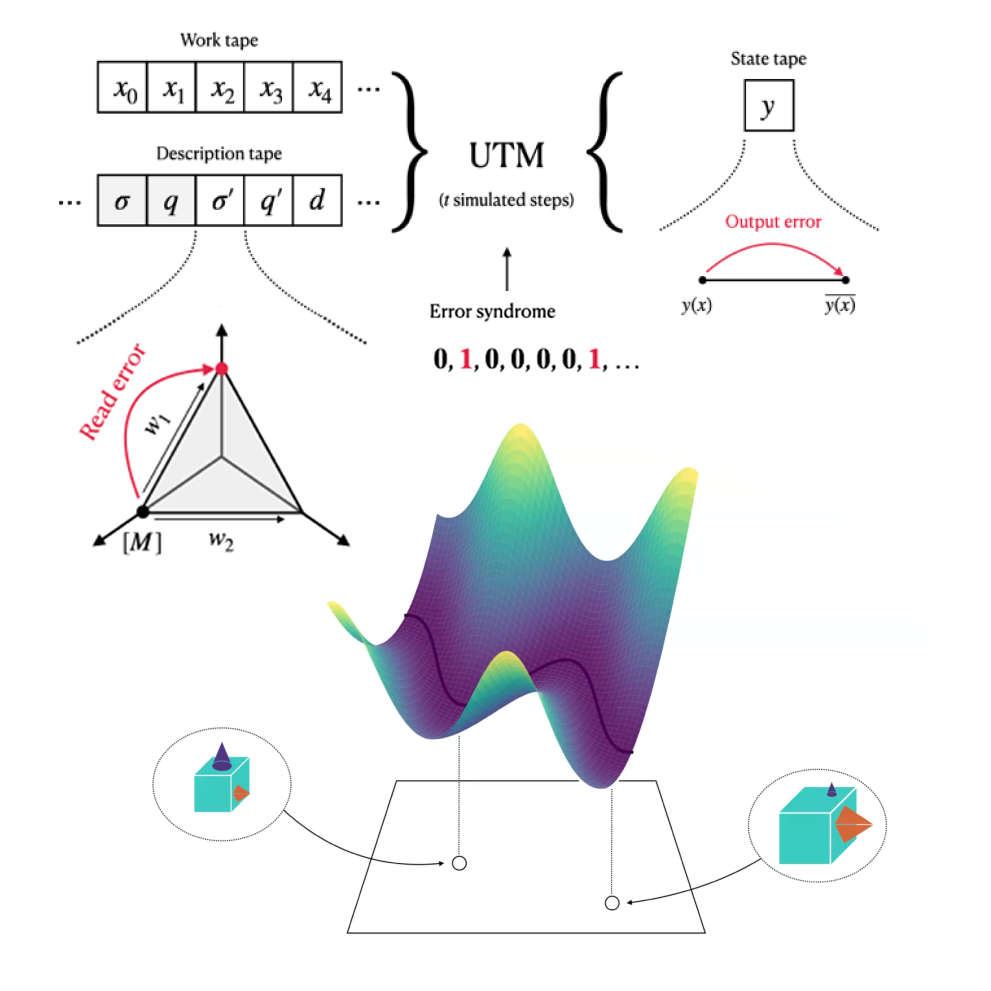
Urdshals and Urdshals · ICML SMUNN Workshop
We study how a one-layer attention-only transformer develops relevant structures while learning to sort lists of numbers.
Carroll et al.
Modern deep neural networks display striking examples of rich internal computational structure.
Murfet et al.