Automated Conversion Notice
Warning: This paper was automatically converted from LaTeX. While we strive for accuracy, some formatting or mathematical expressions may not render perfectly. Please refer to the original ArXiv version for the authoritative document.
1 Introduction
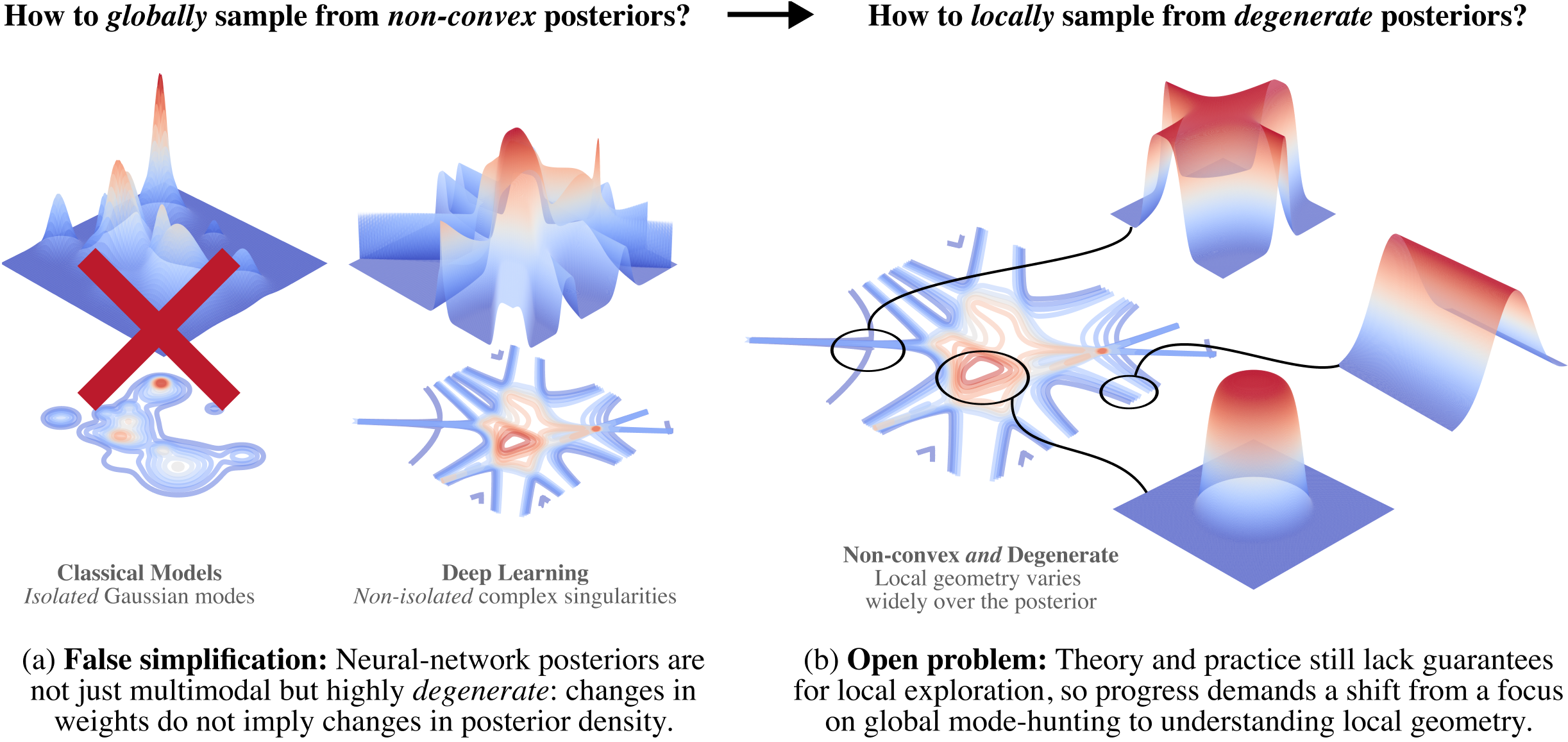
Neural networks have highly complex loss landscapes which are non-convex and have non-unique degenerate minima. When a neural network is used as the basis for a Bayesian statistical model, the complex geometry of the loss landscape makes sampling from the Bayesian posterior using Markov chain Monte Carlo (MCMC) algorithms difficult. Much of the research in this area has focused on whether MCMC algorithms can adequately explore the global geometry of the loss landscape by visiting sufficiently many minima. Comparatively little attention has been paid to whether MCMC algorithms adequately explore the local geometry near minima. Our focus is on Stochastic Gradient MCMC (SGMCMC) algorithms, such as Stochastic Gradient Langevin Dynamics (SGLD; Welling and Teh 2011), applied to large models like neural networks. For these models, the local geometry near critical points is highly complex and degenerate, so local sampling is a non-trivial problem.
In this paper we argue for a shift in focus from global to local posterior sampling for complex models like neural networks. Our main contributions are:
-
We identify open theoretical problems regarding the convergence of SGMCMC algorithms for posteriors with degenerate loss landscapes. We survey existing theoretical guarantees for the global convergence of SGMCMC algorithms, noting their common incompatibility with the degenerate loss landscapes characteristic of these models (e.g., deep linear networks). Additionally, we highlight some important negative results which suggest that global convergence may in fact not occur. Despite this, empirical results show that SGMCMC are able to extract non-trivial local information from the posterior; a phenomena which currently lacks theoretical explanation.
-
We introduce a novel, scalable benchmark for evaluating the local sampling performance of SGMCMC algorithms. Recognizing the challenge of obtaining theoretical convergence guarantees in degenerate loss landscapes, this benchmark assesses a sampler’s ability to capture known local geometric invariants related to volume scaling. Specifically, it leverages deep linear networks (DLNs), where a key invariant controlling volume scaling — the local learning coefficient (LLC; Lau et al., 2024) — can be computed analytically. This provides a ground-truth for local posterior geometry.
-
We evaluate common SGMCMC algorithms and find RMSProp-preconditioned SGLD (Li et al., 2016) to be the most effective at capturing local posterior features, scaling successfully up to models with O(100M) parameters. This offers practical guidance for researchers and practitioners. Importantly, our benchmark shows that although we lack theoretical guarantees about global sampling, SGMCMC samplers are able to extract non-trivial local information about the posterior distribution.
2 Background
In Section 2.1 we discuss existing theoretical results about the convergence of SGLD and related sampling algorithms. We highlight some important negative results from the literature, which suggest that global convergence of algorithms like SGLD are unlikely to occur in loss landscapes with degeneracy, and show that existing global convergence guarantees for SGLD rely on assumptions that likely do not hold for neural networks. In Section 2.2 we discuss applications and related work.
2.1 Problems with global sampling
We consider the problem of sampling from an absolutely continuous probability distribution on . In Bayesian statistics we often consider the tempered posterior distribution
| (2.1) |
where is a statistical model, the prior, a dataset drawn independently from some distribution , is the empirical negative log-likelihood, and is a fixed parameter called the inverse temperature. For any distribution, we can consider the overdamped Langevin diffusion; the stochastic differential equation
| (2.2) |
where is standard Brownian motion. Under fairly mild assumptions on (see Roberts and Tweedie, 1996, Theorem 2.1) (2.2) has well-behaved solutions and is its stationary distribution. The idea of using the forward Euler-Maruyama discretisation of (2.2) to sample from was first proposed by Parisi (1981) in what is now known as the Unadjusted Langevin Algorithm (ULA; also known as the Metropolis Langevin Algorithm), where for we take
| (2.3) |
where is the step size and are a sequence of iid standard normal random vectors in . Stochastic Gradient Langevin Dynamics (SGLD; Welling and Teh 2011) is obtained by replacing in (2.3) with a stochastic estimate , where are independent random variables. When is given by (2.1), usually is a mini-batch estimate of the log-likelihood gradient where selects a random subset of the dataset .
Degeneracy can cause samplers to diverge.
Issues with ULA when has degenerate critical points were first noted in Roberts and Tweedie (1996, Section 3.2), where they show that ULA will fail to converge to for a certain class of distributions when is a polynomial with degenerate critical points. Mattingly et al. (2002) relates the convergence of forward Euler-Mayuyama discretisations of stochastic differential equations (and hence the convergence of ULA) to a global Lipschitz condition on , giving examples of distributions which do not satisfy the global Lipschitz condition for which ULA diverges at any step size. Hutzenthaler et al. (2011, Theorem 1) shows that if grows any faster than linearly then ULA diverges. This is a strong negative result on the global convergence of ULA, since in models like deep linear networks, the presence of degenerate critical points causes super-linear growth away from these critical points.
The current theory makes strong assumptions about the loss landscape.
Given the above results, it is therefore no surprise that results showing that SGLD is well-behaved in a global sense rely either on global Lipschitz conditions on , or on other conditions which control the growth of this gradient. Asymptotic and non-asymptotic global convergence properties of SGLD are studied in Teh et al. (2015); Vollmer et al. (2015). These results rely on the existence of a Lyaponov function with globally bounded second derivatives which satisfies
| (2.4) |
for some (see Teh et al., 2015, Assumption 4). The bounded second derivatives of impose strong conditions on the growth of and is incompatible with the deep linear network regression model described in Section 3.2. A more general approach to analysing the convergence of diffusion-based SGMCMC algorithms is described in Chen et al. (2015), though in the case of SGLD the necessary conditions for this method imply that (2.4) holds (see Chen et al., 2015, Appendix C).
Other results about the global convergence of SGLD and ULA rely on a global Lipschitz condition on (also called -smoothness), which supposes that there exists a constant such that
| (2.5) |
This is a common assumption when studying SGLD in the context of stochastic optimization (Raginsky et al., 2017; Tzen et al., 2018; Xu et al., 2020; Zou et al., 2021; Zhang et al., 2022) and also in the study of forward Euler-Mayurmara discretisations of diffusion processes including ULA (Kushner, 1987; Borkar and Mitter, 1999; Durmus and Moulines, 2016; Brosse et al., 2018; Dalalyan and Karagulyan, 2019; Cheng et al., 2020). Other results rely on assumptions which preclude the possibility of divergence (Gelfand and Mitter, 1991; Higham et al., 2002).
Conditions which impose strong global conditions on the growth rate of often do not hold when has degenerate critical points. For concreteness, consider the example of an -layer deep linear network learning a regression task (full details are given in Section 3.2). Lemma 2.1 shows that assumptions (2.4) and (2.5) do not hold when , which is exactly the situation when has degenerate critical points.
Lemma 2.1.
The negative log-likelihood function for the deep linear network regression task described in Section 3.2 is a polynomial in of degree with probability one, where is the number of layers of the network.
Proof.
We give a self-contained statement and proof in Appendix B.
All is not lost.
Despite the negative results discussed above and the lack of theoretical guarantees, Lau et al. (2024) shows empirically that SGLD can be used to obtain good local measurements of the geometry of when has the form in (2.1). This forms the basis of our benchmark in Section 3.2, and we show similar results for a variety of SGMCMC samplers in Section 4. In the absence of theoretical guarantees about sampler convergence, we can empirically verify that samplers can recover important geometric invariants of the log-likelihood. We emphasise that this empirical phenomena is unexplained by the global convergence results discussed above, and presents an open theoretical problem.
Some work proposes modifications to ULA or SGLD which aim to address potential convergence issues (Gelfand and Mitter, 1993; Lamba et al., 2006; Hutzenthaler et al., 2012; Sabanis, 2013; Sabanis and Zhang, 2019; Brosse et al., 2019). Finally, Zhang et al. (2018) is notable for its local analysis of SGLD, studying escape from and convergence to local minima in the context of stochastic optimization.
2.2 The need for local sampling
The shift toward local posterior sampling has immediate practical implications in areas such as interpretability and Bayesian deep learning.
Interpretability
SGMCMC algorithms play a central role in approaches to interpretability based on singular learning theory (SLT). SLT (see Watanabe, 2009, 2018) is a mathematical theory of Bayesian learning which properly accounts for degeneracy in the model’s log-likelihood function, and so is the correct Bayesian learning theory for neural networks (see Wei et al., 2022). It provides us with statistically relevant geometric invariants such as the local learning coefficient (LLC; Lau et al., 2024), which has been estimated using SGLD in large neural networks. When tracked over training, changes in the LLC correspond to qualitative changes in the model’s behaviour (Chen et al., 2023; Hoogland et al., 2025; Carroll et al., 2025). This approach has been used in models as large as 100M parameter language models, providing empirically useful results for model interpretability (Wang et al., 2024). SGMCMC algorithms are also required to estimate local quantities other than the LLC (Baker et al., 2025).
Bayesian deep learning
Some approaches to Bayesian deep learning involve first training a neural network using a standard optimization method, and then sampling from the posterior distribution in a neighbourhood of the parameter found via standard training. This is done for reasons such as uncertainty quantifications during prediction. Bayesian deep ensembling involves independently training multiple copies of the network in parallel, with the aim of obtaining several distinct high likelihood solutions. Methods such as MultiSWAG (Wilson and Izmailov, 2020) then incorporate local posterior samples from a neighbourhood of each training solution when making predictions.
3 Methodology
In Section 3.1 we discuss how the local geometry of the expected negative log-likelihood affects the posterior distribution (2.1), focusing on volume scaling of sublevel sets of . In Section 3.2 we describe a specific benchmark for local sampling which involves estimating the local learning coefficient of deep linear networks. Details of experiments are given in Section 3.3.
3.1 Measurements of local posterior geometry
In this section we consider the setting of Section 2.1, in particular the tempered posterior distribution in (2.1) and the geometry of the expected negative log-likelihood function where .
Volume scaling in the loss landscape.
An important geometric quantity of from the perspective of is the volume of sublevel sets
| (3.1) |
where , is a minimum of and is a neighbourhood of . The volume quantifies the number of parameters near which achieve close to minimum loss within , and so is closely related to how the posterior distribution concentrates.111This is notwithstanding the difference between and , which requires a careful technical treatment that goes beyond the scope of this paper; see Watanabe (2009, Chapter 5).
We can consider the rate of volume scaling by taking . When is a non-degenerate critical point, volume scaling is determined by the spectrum of the Hessian at and we have
| (3.2) |
where is the dimension of parameter space. However, when is a degenerate critical point we have and this formula is no longer true; the second-order Taylor expansion of at used to derive (3.2) no longer provides sufficient geometric information understand how volume is changing as . In general we have
| (3.3) |
for some , where is the local learning coefficient (LLC) and is its multiplicity within (see Lau et al., 2024, Section 3, Appendix A). When is non-degenerate and the only critical point in then , and , and (3.2) is obtained from (3.3).
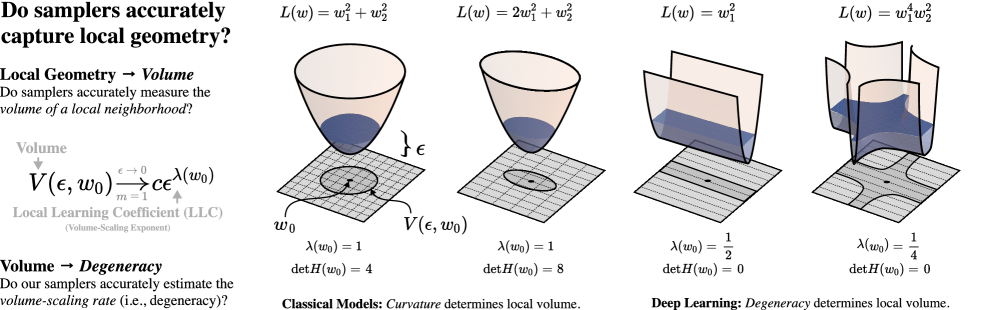
Measuring volume scaling via sampling.
A SGMCMC algorithm which is producing good posterior samples from a neighbourhood of should reflect the correct volume scaling rate in (3.3). In other words, it should produce good estimates of the LLC. The LLC can be estimated by sampling from the posterior distribution (2.1) without direct access to .
Definition 3.1 (Lau et al., 2024, Definition 1).
Let be a local minimum of and let be an open, connected neighbourhood of such that the closure is compact, , and for any which satisfies . The local learning coefficient estimator at is
| (3.4) |
where is an expectation over the tempered posterior (2.1) with prior and support .
The following theorem and Theorem 3.4 in the next section rely on a number of technical conditions, which we give in Definition E.1 in Appendix E:
Theorem 3.2 (Watanabe, 2013, Theorem 4).
Let be a local minimum of and consider the local learning coefficient estimator . Let the inverse temperature in (2.1) be for some . Then, assuming the fundamental conditions of SLT (Definition E.1), we have
-
is an asymptotically unbiased estimator of as .
-
If for some then
Enforcing locality in practice.
In Lau et al. (2024), locality of is enforced by using a Gaussian prior centred at , where is a hyperparameter of the estimator. We use the same prior in our experiments, acknowledging that this deviates from the theory above because it is not compactly supported. The way we use the prior in each sampling algorithm is made explicit in the pseudocode in Section D.3.
3.2 Deep linear network benchmark
As noted in Section 2.1, we lack theoretical convergence guarantees for SGMCMC algorithms in models such as neural networks. In the absence of these theoretical guarantees, we can instead empirically verify that samplers respect certain geometric invariants of the log-likelihood function. The local learning coefficient (LLC) from Section 3.1 is a natural choice.
We do not have ground-truth values for the LLC for most systems; the only known method for computing it exactly (i.e., other than via the estimator in Definition 3.1) involves computing a resolution of singularities (Hironaka, 1964), making the problem intractable in general. However, LLC values have recently been computed for deep linear networks (DLNs; Aoyagi, 2024). DLNs provide a scalable setting where the ground-truth LLC values are known.
Definition 3.3.
A deep linear network (DLN) with layers of sizes is a family of functions parametrised by vectors of matrices where is a matrix. We define where and , .
The learning task takes the form of a regression task using the parametrised family of DLN functions defined in Definition 3.3, with the aim being to learn the function specified by an identified parameter . We fix integers and for the number of layers and layer sizes of a DLN architecture, and let and . We fix a prior on the set of all matrices parametrizing the DLN. Consider an input distribution on and a fixed input dataset drawn independently from . For a parameter , we consider noisy observations of the function’s behaviour , where are independent. The likelihood of observing generated using and the parameter is
| (3.5) |
We fix and consider the task of learning the distribution . Note that while we identify a single true parameter , when there are infinitely many such that . The dataset is where . We define
| (3.6) |
which is, up to an additive constant, the expected negative log-likelihood where . This can be estimated using the dataset as
| (3.7) |
While a DLN with layers expresses exactly the same functions as a DLN with layer, the geometry of its parameter space is significantly more complex. When the loss landscape has degenerate critical points, whereas when all critical points are non-degenerate. Aoyagi (2024) recently computed the LLC for DLNs, and we give this result in Theorem 3.4 below. We also refer readers to Lehalleur and Rimányi (2024).
Theorem 3.4 (Aoyagi, 2024, Theorem 1).
Consider a -layer DLN with layer sizes learning the regression task described above. Let and . There exists a set of indices which satisfies:
where and . Assuming the fundamental conditions of SLT (Definition E.1), the LLC at the identified true parameter is
where , is the ceiling function, and is the set of all 2-combinations of .
3.3 Deep linear network experiments
We generate learning problems in the same way as Lau et al. (2024). We consider four classes of DLN architecture 100K, 1M, 10M and 100M, whose names correspond approximately to the number of parameters of DLNs within that class. Each class is defined by integers , and , , specifying the minimum and maximum number of layers, and minimum and maximum layer size respectively (see Table 1 in Appendix D). A learning problem is generated by randomly generating an architecture within a given class, and then randomly generating a low rank true parameter (a detailed procedure is given in Section D.1). The input distribution is uniform on where is the number of neurons in the input layer.
We estimate the LLC by running a given SGMCMC algorithm for steps starting at . We provide pseudocode for our implementation Section D.3; notably the adaptive elements of AdamSGLD and RMSPropSGLD are based only on the statistics of the loss gradient and not the prior.
This results in a sequence of parameters. For all SGMCMC algorithms we use mini-batch estimates of , where and defines -th batch of the dataset . Rather than using to estimate the LLC, instead assume that where for some number of ‘burn-in’ steps . Inspired by Definition 3.1, we then estimate the LLC at as
| (3.8) |
To improve this estimate, one could run independent sampling chains to obtain estimates however in this case we take , preferring instead to run more experiments with different architectures. We give the hyperparameters used in LLC estimation in Table 2 in Appendix D.
4 Results
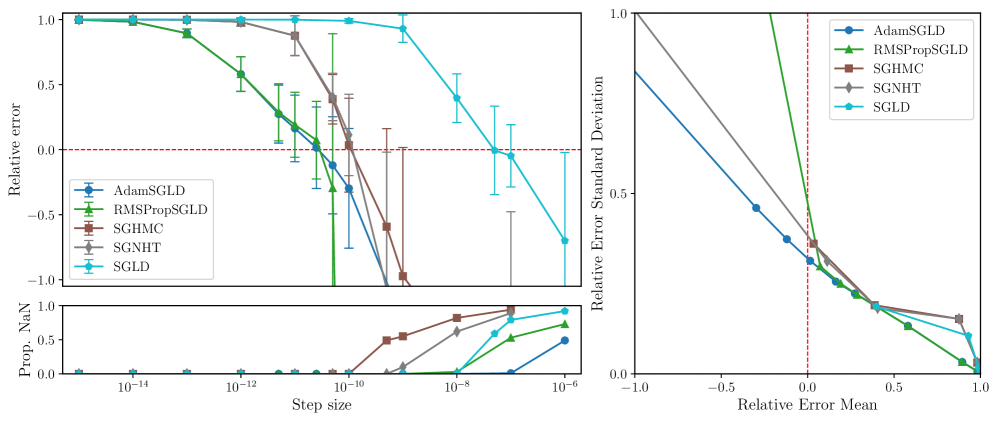
To assess how well they capture the local posterior geometry, we apply the benchmark described in Section 3.2 to the following samplers: SGLD (Welling and Teh, 2011), SGLD with RMSProp preconditioning (RMSPropSGLD; Li et al. 2016), an “Adam-like” adaptive SGLD (AdamSGLD; Kim et al. 2020), SGHMC (Chen et al., 2014) and SGNHT (Ding et al., 2014). We give pseudocode for our implementation these samplers in Section D.3. We are interested not only in the absolute performance of a given sampler, but also in how sensitive its estimates are to the chosen step size of the sampler. To assess the performance of a sampler at a given step size, we primarily consider the relative error of an LLC estimate with true value .
RMSPropSGLD and AdamSGLD are less sensitive to step-size.
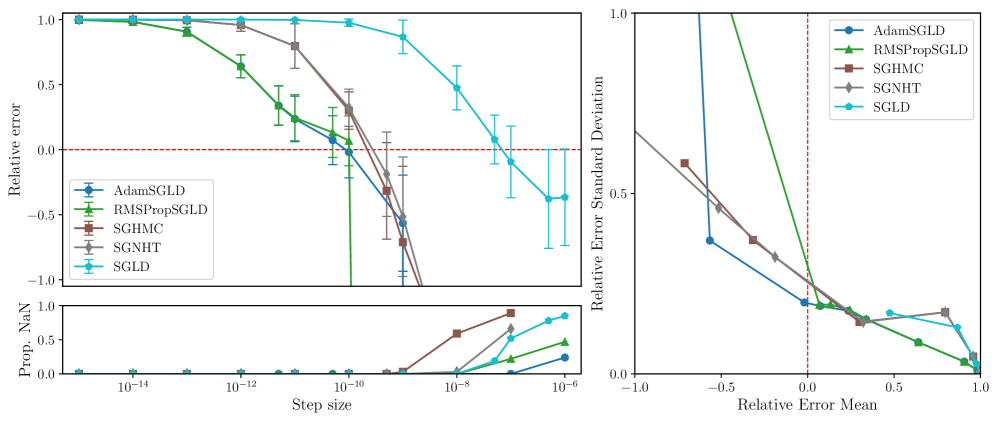
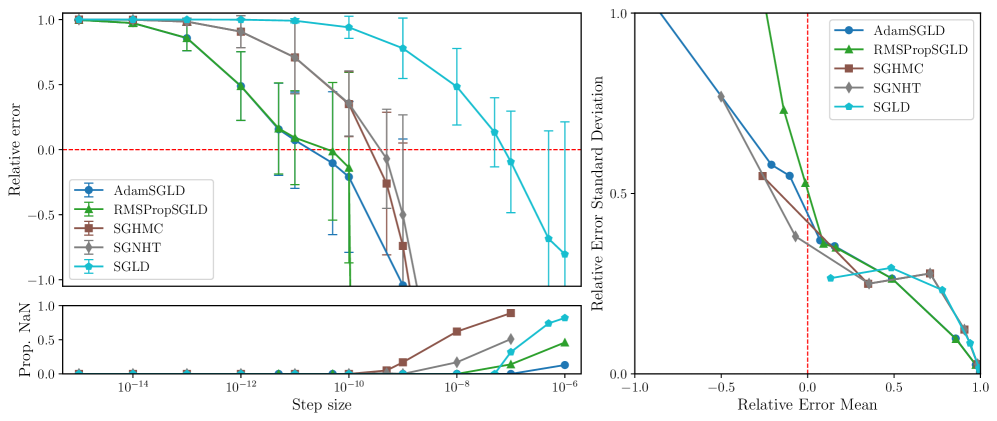
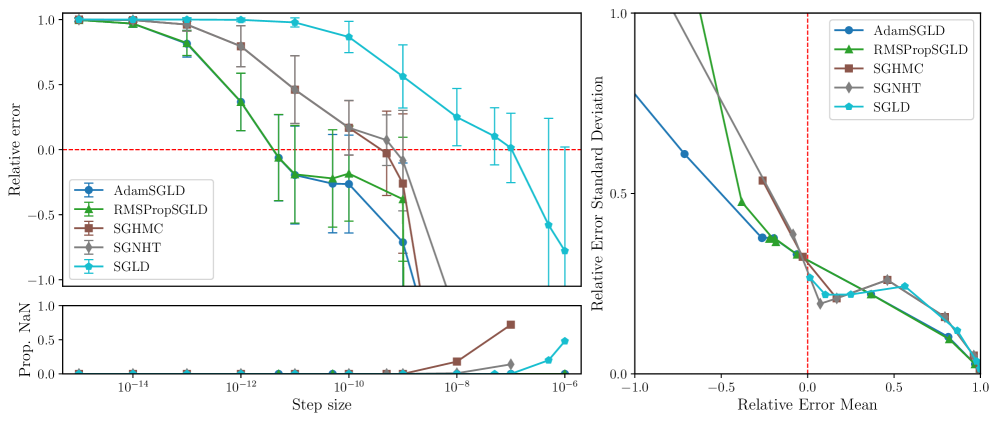
Figures 3, 5, 6 and 7 display the mean relative error (averaged over different networks generated from the model class) versus the step size of each sampler. While all samplers seem to be able to achieve empirically unbiased LLC estimates (relative error = 0) for some step size, RMSPropSGLD and AdamSGLD have a wider range of step size values which produce accurate results. For SGLD, at the step size values where the relative error is close to zero, a significant fraction of the LLC estimates are also diverging. In experiments on language models (Figure 4), RMSPropSGLD is also stable across a wider range of step sizes . This results in more consistent LLC estimates compared to SGLD.
RMSPropSGLD and AdamSGLD achieve a superior mean-variance tradeoff.
In Figures 3, 5, 6 and 7 we plot the mean of the relative error versus the standard deviation of the relative error for each sampler at different step sizes. We see that RMSPropSGLD and AdamSGLD obtain a superior combination of good mean performance and lower variance compared to the other samplers.
RMSPropSGLD and AdamSGLD are better at preserving order.
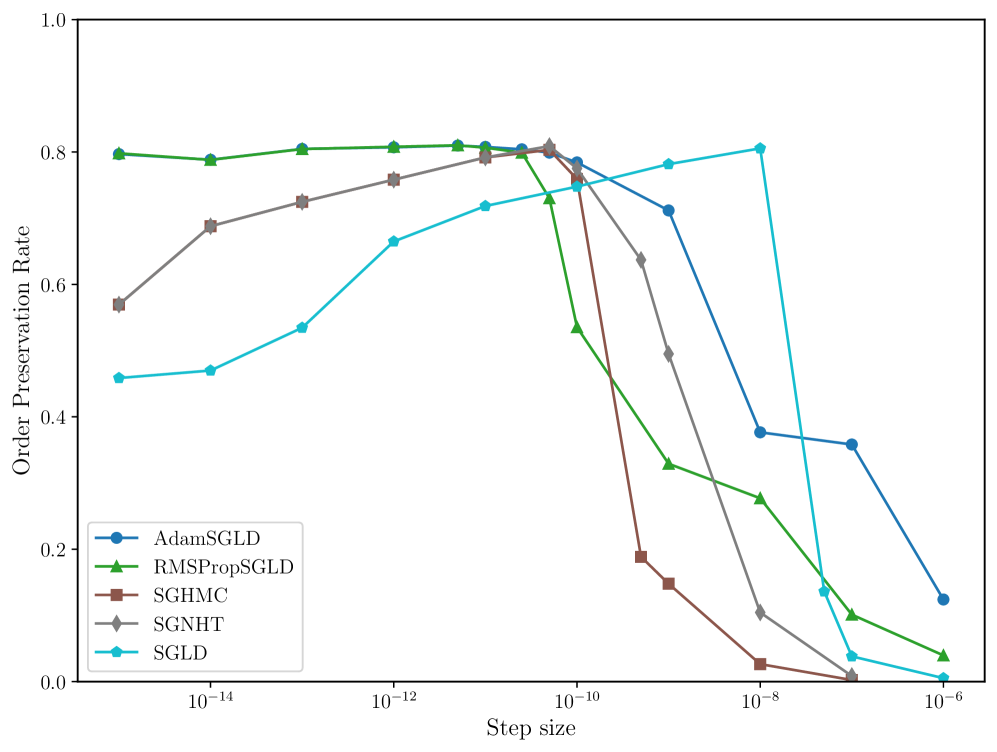
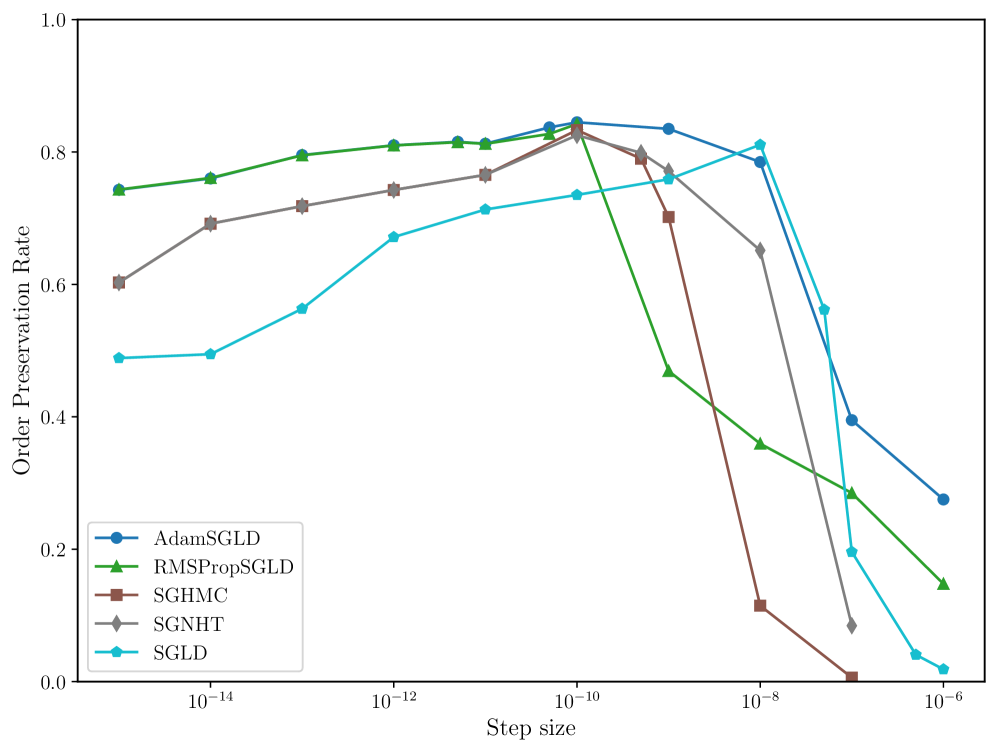
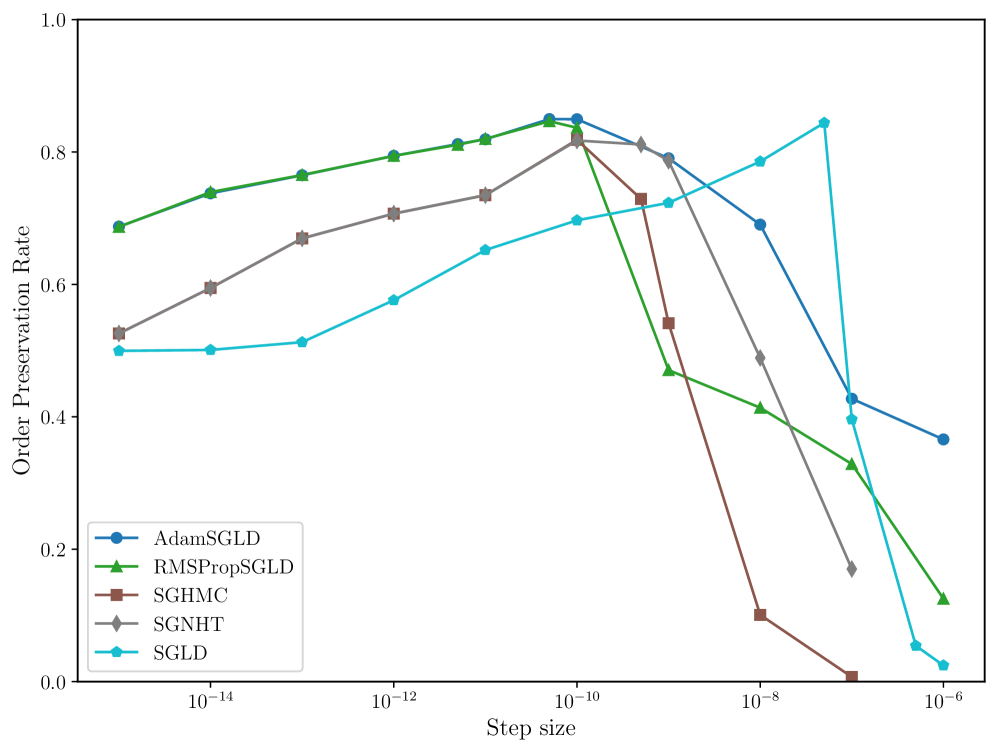
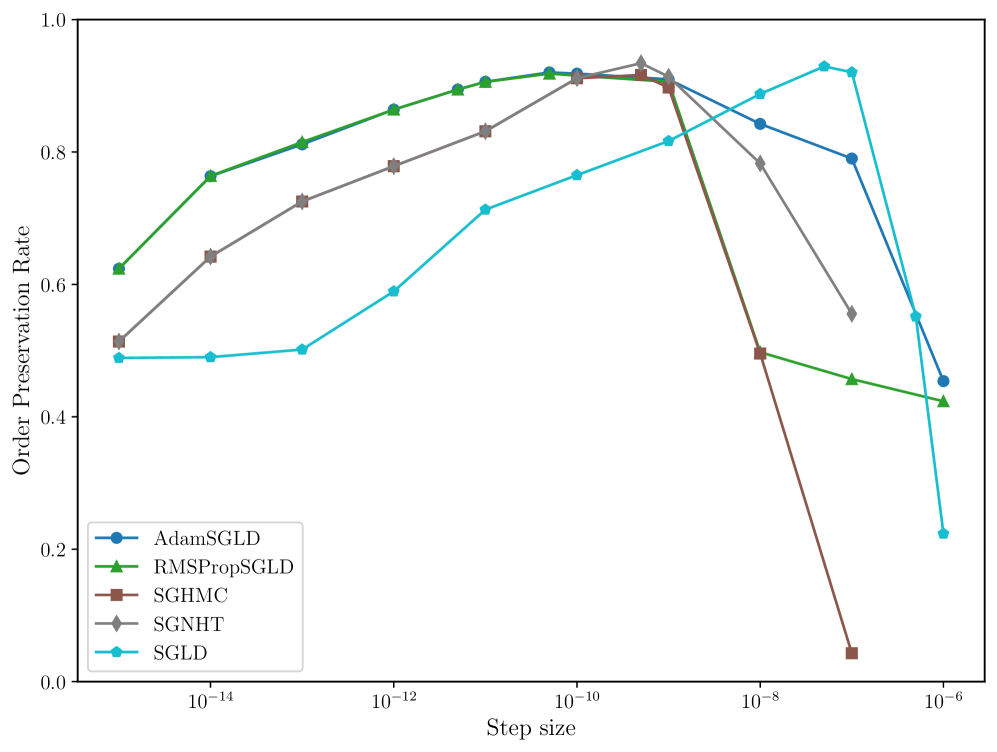
In many applications of LLC estimation, observing relative changes (e.g. over training) in the LLC is more important than determining absolute values (Chen et al., 2023; Hoogland et al., 2025; Wang et al., 2024). In these cases, the order of a sampler’s estimates should reflect the order of the true LLCs. We compute the order preservation rate of each sampler, which we define as the proportion of all pairs of estimates for which the order of the true LLCs matches the estimates. We plot this quantity versus the step size in Figure 8 in Appendix C. Again, RMSPropSGLD and AdamSGLD achieve superior performance to the other samplers with a higher order preservation rate across a wider range of step sizes.
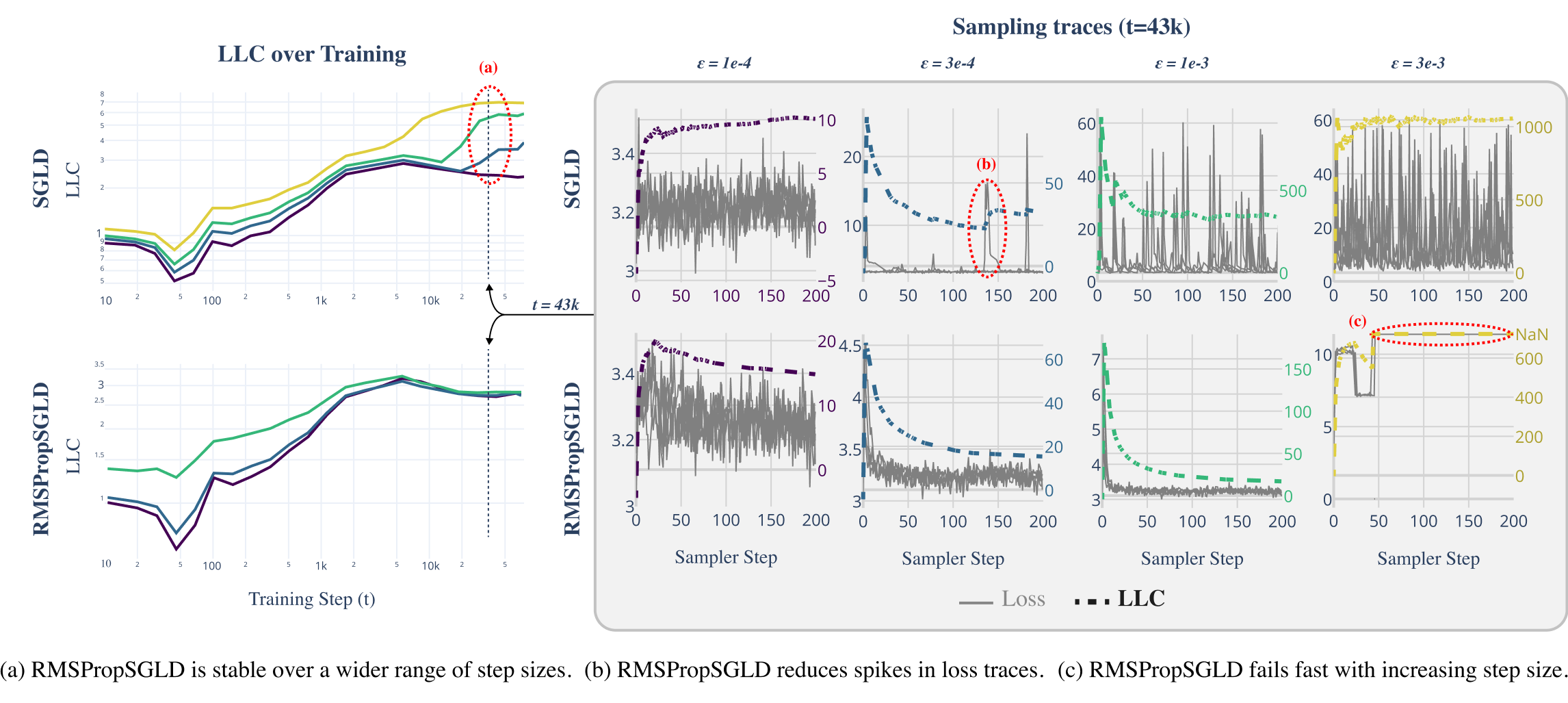
RMSPropSGLD step size is easier to tune.
Above a certain step size RMSPropSGLD experiences rapid performance degradation, with LLC estimates which are orders of magnitude larger than the maximum theoretical value of and large spikes in the loss trace of the sampler. In contrast, AdamSGLD experiences a more gradual performance degradation and its loss traces do not obviously suggest the step size is set to high. We see this catastrophic drop-off in performance as an advantage of RMSPropSGLD, as it provides a clear signal that hyperparameters are incorrectly tuned in the absence of ground-truth LLC values. This clear signal is not present for AdamSGLD.
5 Discussion
In this paper we introduced a scalable benchmark for evaluating the local sampling performance of SGMCMC algorithms. This benchmark is based on how well samplers estimate the local learning coefficient (LLC) for deep linear networks (DLNs). Since the LLC is the local volume-scaling rate for the log-likelihood function, this directly assesses how well samplers explore the local posterior.
Towards future empirical benchmarks.
The stochastic optimization literature has accumulated numerous benchmarks for assessing (optimization) performance on non-convex landscapes (e.g., Rastrigin, Ackley, and Griewank functions; Plevris and Solorzano 2022). However, these benchmarks focus primarily on multimodality and often ignore degeneracy. Our current work takes DLNs as an initial step towards developing a more representative, degeneracy-aware benchmark. A key limitation is that DLNs represent only one class of degenerate models and may not capture all forms of degeneracy encountered in general (see Lehalleur and Rimányi, 2024). Developing a wider set of degeneracy-aware benchmarks therefore remains an important direction for future research.
Towards future theoretical guarantees.
In Section 2.1, we establish that global convergence guarantees for sampling algorithms like SGLD rely on assumptions which provably do not hold for certain model classes (e.g. deep linear networks) with degenerate loss landscapes, and are unlikely to be compatible with degeneracy in general. Shifting from global to local convergence guarantees, which properly account for degeneracy, provides one promising way forward.
This shift may have broader implications beyond sampling. Many current convergence guarantees for stochastic optimizers make similar assumptions that may fail for degenerate landscapes (e.g., global Lipschitz or Polyak-Łojasiewicz conditions; Rebjock and Boumal 2024). Generally, the role of degeneracy in shaping the dynamics of sampling and optimization methods is not well understood.
Open problem: A theoretical explanation for the empirical success of local SGMCMC.
In this paper, we observed empirically that SGMCMC algorithms can successfully estimate the LLC despite the lack of theoretical convergence guarantees. The strong assumptions employed by the convergence results discussed in Section 2.1 arise, in some sense, because the goal is to prove global convergence to a posterior with support . It possible is that convergence results similar to those in Section 2.1 may be proved for compact parameter spaces, however this does not explain the success of local sampling we observe because our experiments are not in a compactly supported setting. This also places our empirical results outside of the setting of SLT (in particular Theorem 3.2 and Theorem 3.4). We see understanding precisely what determines the “effective support” of SGMCMC sampling chains in practice as a central issue in explaining why these samplers work in practice.
Appendix
This appendix contains supplementary details, proofs, and experimental results supporting the main text. Specifically, we include:
-
Appendix A provides examples of global and local degeneracies that are characteristic of modern deep neural network architectures.
-
Appendix B provides a proof of Lemma 2.1, which shows that the negative log-likelihood of deep linear networks is a polynomial of degree .
-
Appendix C presents additional experimental results, focusing on the relative error, variance, and order preservation rates of various samplers across different deep linear network architectures.
-
Appendix D describes additional methodological details, including procedures for randomly generating deep linear network tasks, explicit hyperparameter settings for LLC estimation, and pseudocode for the implemented SGMCMC algorithms.
-
Appendix E summarizes the fundamental technical conditions required by singular learning theory (SLT), outlining the mathematical assumptions underlying our theoretical discussions.
Appendix A Examples of Degeneracy
Degenerate critical points in the loss landscape of neural networks can arise from symmetries in the parametrisation: continuous (or discrete) families of parameter settings that induce identical model outputs or leave the training loss unchanged. We distinguish global (or “generic”) symmetries, which hold throughout parameter space, from local and data-dependent degeneracies that arise only in particular regions in parameter space or only for particular data distributions. In this section we provide several examples (these are far from exhaustive).
A.1 Global degeneracies
Matrix–sandwich symmetry in deep linear networks.
For a DLN with composite weight one can insert any invertible matrix between any neighbouring layers, e.g., without changing the implemented function. This produces a –orbit of equivalent parameters.
ReLU scaling symmetries.
Permutation and sign symmetries.
Exchanging hidden units (or simultaneously flipping signs of incoming and outgoing weights) are examples of discrete changes that leave network outputs unchanged [Carroll, 2021].
Batch- and layer-normalization scaling symmetries.
BN and LN outputs do not change when their inputs pass through the same affine map [Laarhoven, 2017].
A.2 Local and data-dependent degeneracies
Low-rank DLNs.
When the end-to-end matrix is rank-deficient, any transformation restricted to the null space can be absorbed by the factors .
Elimination singularities.
If incoming weights to a given layer are zero, the associated outgoing weights are free to take any value. The reverse also holds: if outgoing weights are zero, this frees incoming weights to take any value. Residual or skip connections can help to bypass these degeneracies [Orhan and Pitkow, 2018].
Dead (inactive) ReLUs.
If a bias is large enough that a ReLU never activates or if the data distribution is such that the pretraining activations never exceed the bias, then the outgoing weights become free parameters; they can be set to arbitrary values without affecting loss because they are always multiplied by a zero activation. Incoming weights also become free parameters (up until the point that they change the preactivation distribution enough to activate the ReLU).
Always-active ReLUs.
Conversely, ReLUs that are always on behave linearly. In this regime, the incoming and outgoing weight matrices act as a DLN with the associated matrix-sandwich and low-rank degeneracies discussed above.
Overlap singularities.
If two neurons share the same incoming weights, then the outgoing weights become non-identifiable: in this regime, only the sum matters to the model’s functional behaviour [Orhan and Pitkow, 2018].
Appendix B Proof of Lemma 2.1
In this section we prove Lemma 2.1, which shows that the global convergence results for SGLD discussed in Section 2.1 do not apply to the regression problem for deep linear networks described in Section 3.2.
Consider an -layer deep linear network with layer sizes . Recall from Definition 3.3 that this is a family of functions parametrised by matrices where is and and . By definition we have
We consider the regression task described in Section 3. Let be an absolutely continuous input distribution on and be an input dataset drawn from independently from . For an identified parameter we consider the task of learning the function . That is, we consider the statistical model
from (3.5), where the true distribution is . As in (3.6) and (3.7) we consider
and
which are, up to additive constants (irrelevant when computing gradients), the expected and empirical negative log-likelihood respectively. When sampling from the tempered posterior distribution (2.1) using a Langevin diffusion based sampler like SGLD, is used to compute sampler steps along with the prior and noise terms (see Section 2.1).
For convenience in the following proof, and in-line with the experimental method in Section 3.3, we consider a prior which is an isotropic Gaussian distribution on
| (B.1) |
where and is any fixed parameter. By we mean to take the sum of the square of all matrix entries, treating the parameter in this expression as a vector with entries.
Lemma B.1 (restating Lemma 2.1).
Consider the above situation of an -layer deep linear network learning the described regression task. If is absolutely continuous then with probability one is a degree polynomial in the matrix entries .
Proof.
We treat each parameter of the model as a different polynomial variable; that is, for each we have where are distinct polynomial variables. As before let . For a matrix with polynomial entries we denote by the maximum degree of its entries. Hence we have that since each entry of is a sum of monomials of the form . Denote the entries of by , which is a polynomial of degree in the variables . The entries of are constants, and we denote them by .
We treat each parameter of the model as a different polynomial variable; that is, for each we have where are distinct polynomial variables. As before let . For a matrix with polynomial entries we denote by the maximum degree of its entries. Hence we have that since each entry of is a sum of monomials of the form . Denote the entries of by , which is a polynomial of degree in the variables . The entries of are constants, and we denote them by .
We now consider the degree of the likelihood function as a polynomial in the variables . Let denote the input dimension of the deep linear network and the output dimension. First note that square of the -th coordinate of is
where is the -th coordinate of . Hence we have
The polynomial has degree . The only way can have degree smaller than is if the random coefficients result in cancellation between the terms of different . We now show that this does not happen with probability one. Consider a function given by
where is any non-empty subset of and . The set has Lebesgue measure zero, and hence has measure zero with respect to the joint distribution of the dataset considered as a distribution on , since is assumed to be absolutely continuous. It follows that cancellation of the degree monomials in the above expression for cannot occur with probability greater than zero, and thus with probability one.
Recall from Section 2.1 that proofs about the global convergence of SGLD assume that there exists a function with bounded second derivatives which satisfies
See Teh et al. [2015, Assumption 4]. In the setting of deep linear networks we have . Since the second derivatives of are bounded and is a degree polynomial, this condition can only hold when . This corresponds precisely to the case when all critical points of are non-degenerate. Likewise, the global Lipschitz condition
can also only be satisfied when .
Remark B.2.
In detailed treatments of singular models such as Watanabe [2009] it is often more convenient to analyse the distribution
| (B.2) |
in-place of the tempered posterior distribution (2.1). The geometry of determines much of the learning behaviour of singular statistical models. In SGMCMC algorithms, a stochastic estimate of the gradient of the log-posterior could equally be considered an estimate of , where is as in (B.2). In the case of deep linear networks, a result similar to Lemma B.1 can be shown using (B.2) in-place of the usual posterior distribution. In this case we have
where . From the proof of Lemma B.1 we have that
where we now write for the -th coordinate of . If each coordinate of is independent and identically distributed (as in the experiments in Section 3.3) then and for . It follows that has degree , since all monomial terms with degree in the above expression for appear with non-negative coefficients, and at least some are non-zero.
Appendix C Additional results
In this section we give additional results from the experiments described in Section 3.3. In Figures 5, 6 and 7 we present the relative error in the estimated local learning coefficient for the deep linear network model classes 10M, 1M and 100K (the results for the 100M model class is given in Figure 3 in the main text).
In Figure 8 we present the order preservation rate of each sampling algorithm, for each deep linear network model class. This assesses how good a sampling algorithm is at preserving the ordering of local learning coefficient estimates. These results are discussed in more detail in Section 4 in the main text.
Appendix D Additional methodology details
In this sectional methodology details, supplemental to Section 3.3. In Section D.1 we describe the procedure for generating deep linear networks, mentioned in Section 3.3. In Section D.3 we give pseudocode for the samplers we benchmark: SGLD (Algorithm 1), AdamSGLD (Algorithm 2), RMSPropSGLD (Algorithm 3), SGHMC (Algorithm 4) and SGNHT (Algorithm 5). In Section D.4 we give details of the large language model experiments presented in Figure 4.
D.1 Deep linear network generation
With the notation introduced in Section 3.3, a deep linear network is generated as follows. The values of , , and for each model class are given in Table 1.
-
Choose a number of layers uniformly from .
-
Choose layer sizes uniformly from , for .
-
Generate a fixed parameter where is a matrix generated according to the Xavier-normal distribution: each entry is drawn independently from where .
-
To obtain lower rank true parameters we modify as follows. For each layer we choose whether or not to reduce the rank of with probability . If we choose to do so, we choose a new rank uniformly from and set some number of rows or columns of to zero to force it to be at most rank .
The above process results in a deep linear network with layers and layer sizes , along with an identified true parameter . We take the input distribution to be the uniform distribution on where , and the output noise distribution is where and .
| 100K | 1M | 10M | 100M | |
|---|---|---|---|---|
| Minimum number of layers | 2 | 2 | 2 | 2 |
| Maximum number of layers | 10 | 20 | 20 | 40 |
| Minimum layer size | 50 | 100 | 500 | 500 |
| Maximum layer size | 500 | 1000 | 2000 | 3000 |
| Number of sampling steps | |
| Number of burn-in steps | |
| Dataset size | |
| Batch size | |
| Localisation parameter | |
| Inverse-temperature parameter | |
| Number of learning problems |
D.2 Deep linear network compute details
The DLN experiments were run on a cluster using NVIDIA H100 GPUs. A batch of 100 independent experiments took approximately 7 GPU hours for the 100M model class, 5 GPU hours for the 10M model class, 3.5 GPU hours for the 1M model class, and 0.9 GPU hours for the 100K model class. The total compute used for the DLN experiments was approximately 1000 GPU hours.
D.3 Samplers
D.4 Large language model experiments
To complement our analysis of deep linear networks, we also examined the performance of sampling algorithms for LLC estimation on a four-layer attention-only transformer trained on the DSIR-filtered Pile [Gao et al., 2020, Xie et al., 2023].
D.4.1 Model Architecture
We trained a four-layer attention-only transformer with the following specifications:
The model was implemented using TransformerLens [Nanda and Bloom, 2022] and trained using AdamW with a learning rate of 0.001 and weight decay of 0.05 for 75,000 steps with a batch size of 32. Training took approximately 1 hour on a TPUv4.
D.4.2 LLC Estimation
We applied both standard SGLD and RMSProp-preconditioned SGLD to estimate the Local
Learning Coefficient (LLC) of individual attention heads (“weight-refined LLCs,” Wang et al. 2024) at various checkpoints during training. As with the deep linear network experiments, we
tested both algorithms across a range of step sizes . LLC estimation was implemented using devinterp [van Wingerden et al., 2024]. Each LLC over training time trajectory in Figure 4 took approximately 15 minutes on a TPUv4, for a total of roughly 2 hours.
D.4.3 Results and Analysis
Figure 4 shows LLC estimates for the second head in the third layer. Here, RMSProp-preconditioned SGLD demonstrates several advantages over standard SGLD:
-
Step size stability: RMSProp-SGLD produces more consistent LLC-over-time curves across a wider range of step sizes, enabling more reliable parameter estimation.
-
Loss trace stability: The loss traces for RMSProp-SGLD show significantly fewer spikes compared to standard SGLD, resulting in more stable posterior sampling.
-
Failure detection: When the step size becomes too large for stable sampling, RMSProp-SGLD fails catastrophically with NaN values, providing a clear signal that hyperparameters need adjustment. In contrast, standard SGLD might produce plausible but inaccurate results without obvious warning signs.
These results align with our findings in deep linear networks and suggest that the advantages of RMSProp-preconditioned SGLD generalize across model architectures.
Appendix E Technical conditions for singular learning theory
In this section we state the technical conditions for singular learning theory (SLT). These are required to state Theorem 3.2 and Theorem 3.4. The conditions are discussed in Lau et al. [2024, Appendix A] and Watanabe [2018].
Definition E.1 (Watanabe, 2009, 2013, 2018, see).
Consider a true distribution , model and prior . Let be the support of and be the set of global minima of restricted to . The fundamental conditions of SLT are as follows:
-
For all the support of is equal to the support of .
-
The prior’s support is compact with non-empty interior, and can be written as the intersection of finitely many analytic inequalities.
-
The prior can be written as where is analytic and is smooth.
-
For all we have almost everywhere.
-
Given , the function satisfies:
-
For each fixed , is in for .
-
is an analytic function of which can be analytically extended to a complex analytic function on an open subset of .
-
There exists such that for all we have
-
Conditions 4 and 5c are together called the relatively finite variance condition.
Cite as
@article{hitchcock2025from,
author = {Rohan Hitchcock and Jesse Hoogland},
title = {From Global to Local: A Scalable Benchmark for Local Posterior Sampling},
year = {2025},
url = {https://arxiv.org/abs/2507.21449},
eprint = {2507.21449},
archivePrefix = {arXiv},
abstract = {Degeneracy is an inherent feature of the loss landscape of neural networks, but it is not well understood how stochastic gradient MCMC (SGMCMC) algorithms interact with this degeneracy. In particular, current global convergence guarantees for common SGMCMC algorithms rely on assumptions which are likely incompatible with degenerate loss landscapes. In this paper, we argue that this gap requires a shift in focus from global to local posterior sampling, and, as a first step, we introduce a novel scalable benchmark for evaluating the local sampling performance of SGMCMC algorithms. We evaluate a number of common algorithms, and find that RMSProp-preconditioned SGLD is most effective at faithfully representing the local geometry of the posterior distribution. Although we lack theoretical guarantees about global sampler convergence, our empirical results show that we are able to extract non-trivial local information in models with up to O(100M) parameters.}
}