Abstract
We introduce the loss kernel, an interpretability method for measuring similarity between data points according to a trained neural network. The kernel is the covariance matrix of per-sample losses computed under a distribution of low-loss-preserving parameter perturbations. We first validate our method on a synthetic multitask problem, showing it separates inputs by task as predicted by theory. We then apply this kernel to Inception-v1 to visualize the structure of ImageNet, and we show that the kernel's structure aligns with the WordNet semantic hierarchy. This establishes the loss kernel as a practical tool for interpretability and data attribution.
Warning: This page was automatically generated from a LaTeX source file using LLMs. This may contain errors and is still under review. For certainty see the arXiv version.
Introduction
A central goal in AI interpretability and data attribution is interpreting and mapping the global structure of the data distribution as seen by a trained neural network [@carter2019activation; @lehalleur2025you; @olah2015visualizing]. One approach is to start local, by quantifying a suitable measure of similarity between pairs of individual samples—that is, by defining a kernel. “Interpreting” the global structure of the data distribution then becomes a problem of analyzing the geometric structure in this kernel (e.g., via clustering techniques), and “mapping” becomes a problem of visualizing points in this kernel space (e.g., via dimensionality reduction techniques).
This kernel-based approach has been used successfully with similarity measures derived from activations or representations. For example, it is possible to define a kernel via cosine similarity between the hidden vectors of sparse autoencoders (SAEs). Applying UMAP to this kernel provides a way to visualize the space of features in language models [@bricken2023monosemanticity; @templeton2024scaling] and image models [@Gorton2024]. This kernel has also been used for analysis, such as to determine the (nearly) hierarchical relations between features [@bricken2023monosemanticity].
In this paper, we take a different approach derived from the geometric structure of the loss landscape. Neural networks are singular models, meaning many different parameter vectors encode identical functions and achieve the same loss. Rather than studying individual weight settings, singular learning theory (SLT; @watanabe2009algebraic), which studies these singular models, suggests analyzing the entire set of low-loss solutions. This perspective motivates us to define the loss kernel, a measure of functional similarity based on shared sensitivity to parameter perturbations restricted to this low-loss set of solutions. Formally, the loss kernel, , is given by the covariance matrix of per-sample losses, , under perturbations drawn from a suitable probe distribution. A high covariance value indicates that the inputs and share sensitivity to the same parameter perturbations, which provides evidence for two samples being functionally coupled inside a given model.
Geometry of the loss kernel for Inception-v1 on ImageNet. A UMAP of pairwise distances induced by the normalized loss kernel for Inception-v1 on ImageNet-1k; each point is one image, colored continuously by position in the ImageNet hierarchy. Similar colors indicate inputs are semantically similar. 1–9 Insets: example neighborhoods with thumbnails showing coherent regions for dogs (1), primates (2), birds (3), diaspids (4), crustaceans (5), insects (6), produce (7), musical instruments (8), and vehicles/cars (9). Bottom right: Orbit views of the same 3-D embedding. B The full correlation kernel matrix (10k10k) next to the ground truth distance matrix derived from the ImageNet hierarchy shows similar block structures in both.
We demonstrate the loss kernel as a practical interpretability technique by combining it with established kernel-based techniques to study two settings. First, in a controlled experiment using a synthetic multitask arithmetic problem, we confirm that the kernel successfully separates inputs corresponding to functionally independent subtasks, as predicted by theory. Second, we apply the loss kernel to an Inception-v1 model to create a visual map (Figure 1) of the ImageNet dataset on which it was trained [@szegedy_going_2014; @deng2009imagenet]. We then quantitatively validate that the structure of this kernel reveals a coherent semantic organization that is consistent with the WordNet class taxonomy [@princeton2010wordnet].
Contributions. Our contributions are thus:
- We introduce the loss kernel as a measure of functional coupling, motivating it from the geometric perspective of singular learning theory and defining it through a principled, local probe distribution. (Section 2)
- We validate the loss kernel in a controlled setting, confirming that the loss kernel is able to successfully separate subtasks in a synthetic multitask experiment, as predicted theoretically. (Section 3)
- We apply the loss kernel to Inception-v1 on ImageNet, demonstrating its utility as a large-scale interpretability and visualization tool. We show that its structure reveals a coherent semantic organization consistent with the WordNet class taxonomy. (Section 4)
The Loss Kernel
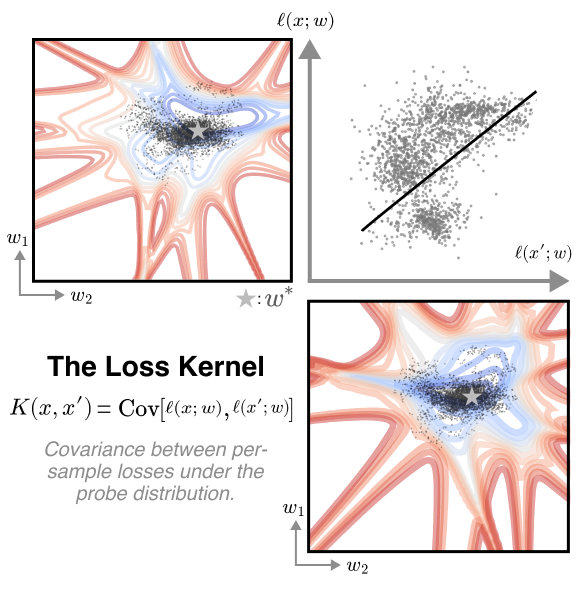
The loss kernel. The loss kernel is the covariance of per-sample losses for two inputs and , computed over a probe distribution of model weights (gray points) sampled near a trained solution . These two losses respond differently to different weights (top left, bottom right), reflecting which parts of the model are important for those inputs. A positive correlation in these losses (scatter plot, top right) signifies that the two inputs share sensitivity to the same weight perturbations, which we interpret as evidence that the model is treating the inputs and similarly.
In this section, we define the loss kernel, a metric that quantifies whether two inputs are processed similarly by a trained neural network. First (Subsection 2.1), we motivate our focus on the geometry of the loss landscape, specifically the set of low-loss points that contains a given trained model . Second (Subsection 2.2), we develop a practical probe distribution using a localized Gibbs posterior, which allows us to sample from this low-loss region. Finally (Subsection 2.3), using this distribution, we formally define the loss kernel as the covariance of per-sample losses under our probe distribution.
Interpretability and Degeneracy
The typical process of training a neural network yields a single parameter vector , optimized via an algorithm like SGD against an objective function of the form
where is the loss on -th data sample for the parameter vector , with a dataset of size .
The field of interpretability seeks to understand the structure of the trained model represented by . It is typically implicitly presumed that one can understand the structure in the trained model using the parameters , either directly by inspecting, for example, weight magnitudes [@kovaleva_bert_2021], or indirectly by examining the computation process of the model at through, for example, activations [@bricken2023monosemanticity; @wang_interpretability_2022; @carter2019activation] and gradients [@ancona_towards_2018; @sundararajan_axiomatic_2017].
A challenge to interpreting weights directly is that neural networks are singular: many different parameters implement the same function or achieve the same loss. This degeneracy means that properties specific to may reflect arbitrary details of the learned implementation that are irrelevant to downstream behavior. For example, ReLU-scaling symmetries mean the absolute magnitude of individual weights or gradients is not always meaningful on its own, which undermines interpretability methods that rely on it.
Singular learning theory. Watanabe’s (@watanabe2009algebraic) singular learning theory (SLT) provides a mathematical framework for studying models that exhibit such degeneracies. A key idea from SLT is to study the geometry of the set of minima of the loss function as a whole rather than individual weight settings. Consider the set of parameters which are “almost equivalent” to , according to the training loss : 1
The asymptotic volume-scaling behavior of (the population version of) is directly linked, through SLT, to the complexity, description length, and generalization error of the model at [@quantifdegen; @urdshals_compressibility_2025]. Our work builds on this premise to develop a principled technique for measuring whether two inputs are processed in similar ways by a given trained neural network.
Constructing a Practical Probe
While is theoretically natural, it is difficult to integrate over this set because it is so high-dimensional. Moreover, we need a way to localize this set to a specific set of model weights obtained via stochastic optimization. We make two modifications to overcome these challenges and develop a practical low-loss probe:
From hard to soft constraints. First, we replace the sharp boundary of with a smooth Gibbs factor, . This concentrates sampling in low-loss regions, where the inverse temperature plays a role analogous to . This makes the distribution amenable to gradient-based MCMC sampling and is formally justified by the relationship between integrals over low-loss sets and expectations under the Gibbs distribution (see Appendix A.3).
From global to local. Second, we focus on the neighborhood containing the specific model found by a given run of stochastic optimization. The global loss landscape may contain many regions of low loss, but we wish to interpret the particular solution our training procedure has found. We therefore re-weight the Gibbs distribution with a Gaussian kernel centered at .
This yields the final probe distribution over the training set :
From a Bayesian perspective, this is equivalent to a tempered Bayesian posterior with Gaussian prior.
The Loss Kernel
The loss kernel. The loss kernel, , is the covariance matrix of per-sample losses under our probe distribution:
A high value of indicates that inputs and are functionally coupled, sharing sensitivity to the same parameter perturbations. The kernel is symmetric positive semi-definite as it is a covariance kernel. For analysis and visualization, we often use its normalized form:
with if or , which measures the correlation between per-sample losses. also has the advantage of being invariant under affine changes of the loss function, unlike itself.
Interpretation. The loss kernel can be seen as a generalized version of the negated (local) Bayesian Influence Function [@singfluence1], which itself generalizes the influence function from classical statistics, see Appendix A.2. The diagonal of this kernel, , is the per-sample loss variance. Up to a multiplicative constant, the sum of over the training set, , is an empirical estimator for the singular fluctuation, a key quantity in SLT that governs the model’s (Gibbs) generalization error, see Appendix A.1.
Practical estimation. Expectations over the probe distribution are intractable to compute analytically. We therefore approximate them using Monte Carlo methods. Specifically, we generate a set of samples from a Stochastic Gradient Langevin Dynamics (SGLD; @welling2011bayesian) chain (or multiple parallel chains) initialized at the trained model’s parameters, . We then use these samples to compute standard unbiased plug-in estimators for the loss kernel and its normalized version . We provide further details and departures from SGLD in Appendix B.
Validation on a Synthetic Task
Before using the loss kernel to explore structure in natural data, we first verify that it behaves as expected in a controlled scenario. Theoretically, we expect that for tasks solved by independent mechanisms—where the loss factorizes into a sum of sublosses depending on disjoint sets of weights—the cross-task loss covariance is zero (Appendix A.4). We test this prediction on a transformer trained on a multitask modular arithmetic problem designed to encourage such independent mechanisms.
Multitask arithmetic. For our controlled scenario, we analyze a two-layer transformer on a multitask modular arithmetic (“grokking”) problem, extending the single-task setup of @power2022grokking. Our model is trained to perfect accuracy on two independent tasks: modular addition and modular division, both modulo 97. To encourage the development of distinct computational pathways, each operation uses a separate input vocabulary.
Reducing dimensionality. We visualize the kernel by applying standard dimensionality reduction techniques to a set of reference points in the kernel space. We use UMAP, which obtains a low-dimensional embedding optimized to preserve nearest-neighbor relationships [@mcinnes2018umap].
UMAP operates on a distance matrix, where a point must have distance with itself and positive distance with all other points. We transform the normalized loss kernel, or correlation, into a distance by setting the distance between any two samples and to . Applying UMAP to these pairwise distances produces the embedding depicted in Figure 2, where proximity in the visualization indicates a strong functional coupling between samples as measured by the kernel. 2
Interpreting the kernel. After computing the loss kernel over all pairs over 10,000 inputs drawn equally from both tasks, we find its structure reflects the task-level separation between addition and division. As seen in the UMAP visualization in Figure 2, the kernel separates into two distinct clusters corresponding precisely to the addition and division samples (and a third smaller cluster for the trivial modular division case where the dividend is zero). Examining the underlying covariance values confirms this observation: cross-task covariances are narrowly distributed around zero, while within-task covariances are substantially larger.
Though we lack a sufficient mechanistic understanding to establish whether this model’s internal implementations of modular addition and division satisfy the criteria in Appendix A.4, observing vanishing correlation between tasks is consistent with the behavior theoretically predicted for functionally disjoint mechanisms. This establishes the kernel’s utility in a setting with partially known ground-truth structure.
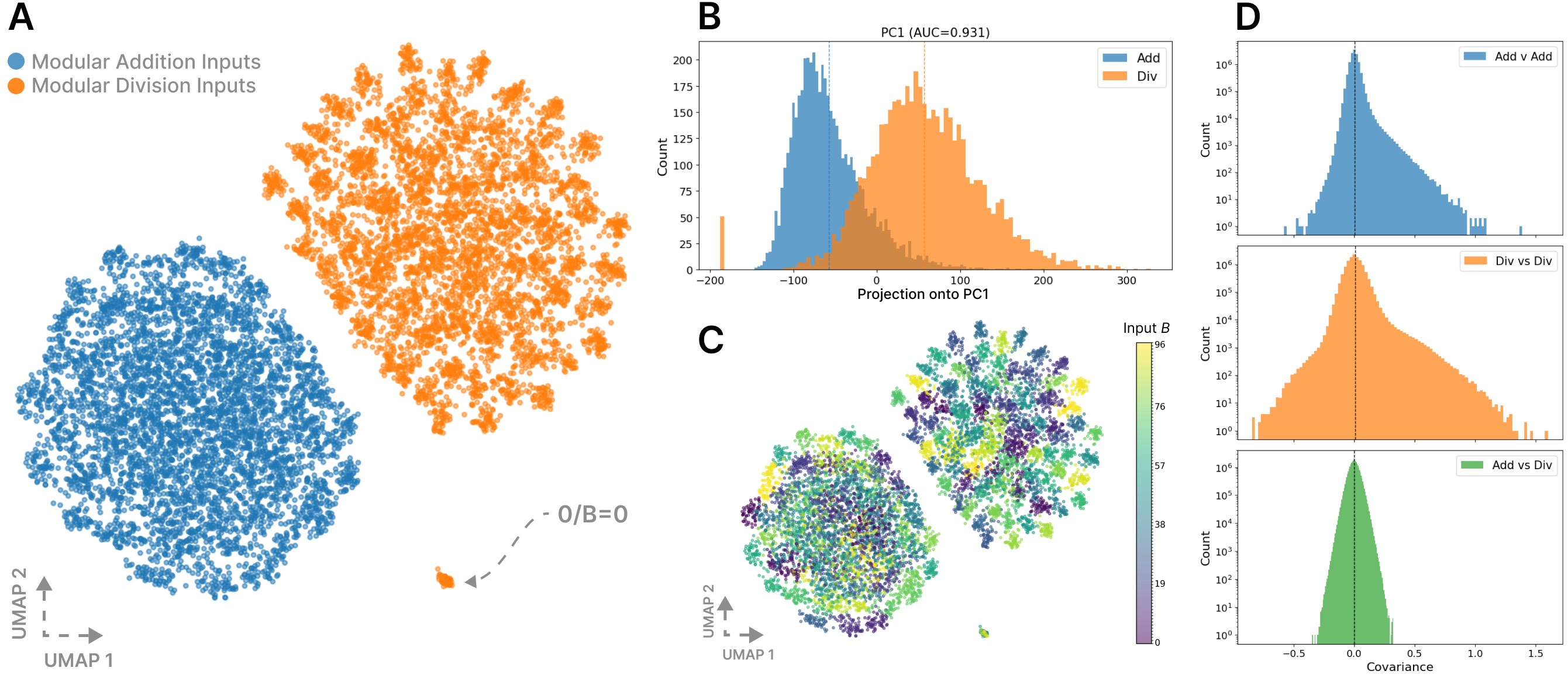
Geometry of the loss kernel for a multitask modular-arithmetic model (). (A) UMAP of pairwise distances derived from the loss kernel (. Two well-separated clusters correspond to modular addition (blue) and modular division (orange). A small satellite cluster corresponds to the trivial modular division case , for which . (B) Distribution of projections onto the first principal component of the normalized per-sample expected loss vectors, . A single axis suffices to separate tasks (ROC–AUC ). (C) Same UMAP as in (A), colored by the value of input . (D) Log-scaled covariance distributions for Addition vs. Addition, Division vs. Division, and Addition vs. Division pairs. Within-task covariances are heavy-tailed and skewed, whereas cross-task covariances are narrowly concentrated and approximately normal.

Top-correlated examples under the loss kernel reveal interpretable patterns. For each reference image (leftmost column), we show the top five most-correlated inputs under the loss correlation kernel . We observe clustering by texture (e.g., fluffy fur coat and fluffy animals), shape (e.g., circular objects and line angle), color and category (e.g., people playing sports, electronics on a white background, dark vs. light brown dogs), and spatial layout (e.g., cluttered rooms). Additional visualizations are provided in Appendix D.3, and further computed correlation results are available at https://github.com/singfluence-anon/sf_imagenet_corrs
Application to ImageNet
Having established theoretically and empirically that the loss kernel can identify ground-truth functional separation in a controlled setting, we now deploy it as an exploratory tool on a large-scale, real-world task. We consider an Inception-v1 model [@szegedy_going_2014] trained on ImageNet data [@deng2009imagenet], where the true functional organization is not fully known. Our goal is to investigate qualitatively whether we can use the kernel as a visualization tool and quantitatively whether structure in the kernel corresponds to meaningful semantic and hierarchical structure in the data.
Visualizing the loss kernel. For 10,000 random validation examples, we compute the loss correlation matrix and examine top-correlated inputs. We find that nearest neighbors are interpretable, often sharing patterns of color, texture, shape, or content. Figure 3 provides qualitative examples of these relationships, showing the top and bottom correlated examples for a selection of inputs. Additional randomly chosen examples are available in Appendix D.3.
Hierarchical structure in ImageNet. The ImageNet dataset [@deng2009imagenet] is not a flat collection of classes; its labels are drawn from and organized according to the WordNet hierarchy, a large lexical database of English where nouns, verbs, adjectives, and adverbs are grouped into sets of synonyms (synsets), each expressing a distinct concept [@princeton2010wordnet]. Each node in the ImageNet hierarchy represents a category (e.g., “animals”, “mammals”, “devices”, “plants”), and each leaf node corresponds to a specific class, which the model was trained to predict (e.g., “wire-haired fox terrier , “goldfish”, “castle”). This taxonomy provides a natural (though only partial) source of ground truth for establishing similarity between ImageNet inputs, based on the similarity between their output labels according to the WordNet hierarchy.
To visualize this ground-truth structure overlaid on the loss kernel, we color each sample in Figure 1 (A) by the position of that sample’s label in the ImageNet hierarchy. The version of ImageNet we use in these experiments is organized into 1,000 classes; by sorting these classes via their position in the hierarchy we assign similar hues to inputs of nearby categories.
Hierarchical structure in the loss kernel. The UMAP visualization in Figure 1 reveals a clear high-level organization that mirrors the primary branches of the WordNet hierarchy. A prominent split separates “animals” from “things,” with a transitional region occupied by “produce” (Inset 7). Within these broad domains, the kernel captures finer taxonomic distinctions. For example, the “animal” kingdom subdivides into coherent superclasses. A large cluster representing “domesticated animals”, particularly “dogs” (Inset 1), transitions into other mammals like “primates” (Inset 2), and then to “birds” (Inset 3). Nearby, we observe distinct groupings for “diapsids” (Inset 4), “crustaceans” (Inset 5), and “insects” (Inset 6). This hierarchical organization persists at deeper levels of specificity, as shown by the more detailed insets for “musical instruments” (Inset 8). The block structure of the full correlation matrix, when sorted by the WordNet hierarchy (Figure 1 B), provides an additional confirmation of this nested structure, showing strong intra-class correlation that closely mirrors the ground-truth semantic distance matrix derived from WordNet.
The kernel as a developmental tool. At initialization the kernel shows no coherent structure (see Figure 5). As training proceeds, structure begins to emerge. Early checkpoints separate broad regimes (e.g., “animal” vs. “thing”), mid-training checkpoints resolve salient subgroups (e.g., “dogs” forming a distinct cluster), and later checkpoints exhibit finer-grained specialization. The UMAP snapshots in Figure 5 illustrate this coarse-to-fine trajectory, where neighborhoods that are initially mixed become progressively more taxonomically coherent as training converges.
Related Works
Bayesian influence functions and training data attribution. The loss kernel we propose is a generalization of the negative (local) Bayesian Influence Function (BIF; [@singfluence1]), which has its roots in Bayesian sensitivity analysis [@giordano_covariances_2018; @iba2025wkernel]. [@singfluence1] introduced the BIF as a tool for Training Data Attribution (TDA; [@koh_understanding_2020]), a task focused on provenance — identifying which training points are most responsible for a specific model behavior. Our work addresses a different question: one of functional coupling. We generalize the BIF from a unidirectional, single-point attribution measure into a global, symmetric, positive semidefinite kernel that measures the functional relationship between arbitrary pairs of inputs. Furthermore, we are the first to demonstrate its power for large-scale interpretability by applying kernel analysis techniques to this functional map. For more details on the differences, see Appendix A.2.
Data-similarity kernels and metric learning. The general approach of learning a data-similarity kernel is a cornerstone of statistics and machine learning, and our work is situated within this broader context [@hofmann_review_2006; @khatib_comprehensive_2024]. Classical methods like Principal Component Analysis (PCA) can be viewed as defining similarity through the data’s covariance matrix. This was later generalized by Kernel PCA, which uses the kernel trick to learn non-linear similarities in a high-dimensional feature space [@scholkopf_kernel_1997]. A related field, metric learning, is explicitly focused on learning distance or similarity functions that are optimized for specific tasks, often by training models that pull similar data points together while pushing dissimilar ones apart [@kulis_metric_2013]. In modern deep learning, this principle is prominent in representation learning, where models learn to project data into a latent embedding space where simple distance metrics (e.g., cosine similarity) correspond to semantic similarity [@bengio_representation_2014; @mikolov_efficient_2013; @chen_simple_2020].
Representation-based interpretability. Representation-based kernels are not limited to models explicitly trained for their representations. For example, similarity measures like Centered Kernel Alignment (CKA; @kornblith_similarity_2019) make it possible to derive kernels from intermediate activations of LLMs trained on next-token prediction. This falls under the broader field of representation-based interpretability, which includes other techniques such as supervised “probes” that test for specific properties of activations, and unsupervised methods, like activation atlases [@carter2019activation] or sparse autoencoders (SAEs; [@bricken2023monosemanticity]). As described in Section 1, these representation-based interpretability techniques offer other ways to construct kernels.
The loss kernel offers a perspective complementary to these representation-based methods. Where representation-based methods learn similarity based on what data points look like in an embedding space, the loss kernel defines similarity based on how the model treats them across the set of low-loss points. Understanding the relationship between activation-space similarity and weight-space functional coupling is a key open question. An interesting direction for future work is to bridge between these different kernel approaches. For example, Multiple Kernel Learning (MKL; [@gonen_multiple_2011]) techniques could be adapted to learn a meta-kernel that combines information from both representations and weight-space geometry.
Mechanistic and causal interventions. Mechanistic interpretability aims to identify circuits and algorithms via targeted interventions such as activation patching and ablations [@wang_interpretability_2022]. Our SGLD-based probe can be viewed as a complementary, weight-space analogue to these activation-space ablations. That said, our aims are different: we seek to use the loss kernel as an exploratory tool for discovering structure in data, rather than as a confirmatory tool for testing a mechanistic hypothesis.
Developmental interpretability. Developmental interpretability is an approach to interpretability that models the SGD learning process as an idealized Bayesian learning process, then applies SLT to derive theoretical predictions, and finally verifies those predictions empirically on models trained using standard stochastic optimization techniques. This approach has been used successfully to detect and interpret phase transitions in stagewise learning in toy models of superposition [@chen2023dynamical; @elhage2022superposition], transformers trained on algorithmic tasks like list-sorting and in-context regression [@carroll_dynamics_2025; @urdshals2025structure], and small language models [@hoogland2024developmental; @wang2025differentiation; @baker_structural_2025; @wang_embryology_2025].
The loss kernel is part of this broader agenda, particularly through its connection to key SLT quantities like the singular fluctuation (Appendix A.1).
Discussion & Conclusion
We introduced a new technique, the loss kernel, for mapping and interpreting learned functional relationships between samples in a trained neural network. The kernel is defined as the covariance matrix of per-sample losses, computed under a distribution of parameter perturbations localized to the set of low-loss points. We first validated this method on a synthetic multitask problem, demonstrating that the kernel separates inputs by their underlying task, consistent with theoretical predictions for functionally independent mechanisms. Applied to an Inception-v1 model trained on ImageNet, we show that the loss kernel can be used to visualize the structure of the data distribution and that this structure reflects the WordNet semantic hierarchy. These findings highlight the loss kernel as a useful practical tool for interpretability.
Limitations. The SGLD sampling procedure can be computationally intensive, although it is a one-time, post-hoc cost (for instance, the kernel used in the ImageNet results, Section 4, took three hours to compute on four A100 GPUs). Moreover, the results depend on the hyperparameters of the local posterior, particularly the localization strength (see Appendix D.2). We also emphasize that our method is intentionally local, designed to interpret the specific solution found by training, not the entire global loss landscape. Finally, the kernel reveals functional correlation, not causation; it is a tool for discovering related behaviors and generating hypotheses for more targeted mechanistic investigations.
Future directions. This work opens several promising avenues for future research. A primary theoretical direction is to deepen the connections to singular learning theory, and to extend this methodology beyond pairwise statistics to explore higher-order correlations. We might also hope to formalize the relationship between weight-space coupling, as measured by our kernel, and representation similarity in activation space. On an applied front, the kernel can serve as a discovery tool to guide mechanistic interpretability by identifying functionally-coupled inputs that warrant circuit-level analysis. Its ability to identify functional outliers suggests applications in anomaly and out-of-distribution detection, and the core method can be adapted to other domains like language models using token-level losses. Finally, a key direction is to apply the kernel across training checkpoints to create a developmental view of how a model’s internal functional geometry emerges and solidifies over time.
In summary, the loss kernel offers a window into the way neural networks perceive their input data, helping to understand what data the model treats similarly, and what data the model treats differently.
Reproducibility Statement
To ensure our work is reproducible, we provide detailed descriptions of our methodology throughout the paper and its appendices. The core SGLD-based estimation procedure for the loss kernel is formally presented in Section 2.3, Appendix B. All experiments were conducted on a public dataset (ImageNet; [@deng2009imagenet]) and a standard model architecture (Inception-v1; [@szegedy_going_2014]), or on a synthetic, fully described multitask arithmetic problem (Section 3, Appendix C). A complete summary of the SGLD hyperparameters used for each experiment is available in Table B.1 in Appendix B.1, with further implementation details and sensitivity analyses for the ImageNet setting discussed in Appendix D.2. The setup for our main ImageNet analysis, including the quantitative evaluation against the WordNet hierarchy, is detailed in Appendix D.
LLM Usage Statement
We used Large Language Models (LLMs) to help produce this paper. We used them to edit our writing by fixing errors and improving phrasing. We also used them to brainstorm the paper’s structure and get feedback on our arguments. For our experiments, LLMs helped us write code and create figures. They also assisted us in strengthening the math and proofs. The authors checked all AI-generated suggestions and are fully responsible for the content of this paper.
Appendix
- Appendix A: Theory Extra: Provides additional detail on the theoretical foundations for the paper’s methodology.
- Appendix A.1: Singular Learning Theory: Introduces the core concepts of SLT for singular models like neural networks, connects the loss kernel to two key quantities from SLT (the empirical variance and singular fluctuation), and sketches what a population version of the loss kernel would look like.
- Appendix A.2: Training Data Attribution: Introduces influence functions from training data attribution and compares the loss kernel against a type of influence function known as the (local) Bayesian Influence Function (BIF).
- Appendix A.3: From Sublevel Sets to Gibbs Distribution: Establishes the formal relationship between expectations under the Gibbs distribution and integrals over low-loss sets, justifying the use of our probe distribution as a tractable probe of the low-loss parameter set.
- Appendix A.4: Decoupling of Disjoint Mechanisms: Formalizes conditions under which the loss covariance between data points from independent subtasks is zero.
- Appendix B: Stochastic-Gradient MCMC Estimator: Provides additional details on the SGMCMC-based estimator we use to estimate the loss kernel.
- Appendix C: Synthetic Task Extra: Provides additional methodology and results for the synthetic multi-task arithmetic setting.
- Appendix D: ImageNet Extra: Provides additional methodology, hyperparameter values and ablations, and additional results for the ImageNet setting.
Theory Extra
Singular Learning Theory
Singular learning theory (SLT) is concerned with the theory of machine learning models which are singular: very roughly, models for which their parameterization map is not one-to-one. Neural networks of virtually any architecture are examples of singular models. Singular models break many of the assumptions of traditional statistical learning theory [@watanabe2009algebraic; @watanabe2018mathematical]. From an interpretability perspective, they have rich geometrical structure (e.g. in their loss landscape), which often reflects information about their internal structure [@murfet2025programs] and their training data [@lehalleur2025you].
Setup
Classically, the setting of singular learning theory is parametric Bayesian learning. We review the setup here briefly. See [@watanabe2009algebraic; @watanabe2018mathematical] for a more in-depth treatment.
We begin with a parameter space (assumed compact) and a sample space . A parametric statistical model assigns a probability to samples for a given parameter . In singular learning theory, we typically assume that is analytic or at the very least piecewise-analytic, which holds for most statistical models including the vast majority of neural networks.
To quantify sensitivity of to infinitesimal parameter perturbations, we define the Fisher information matrix:
A model is regular at a parameter if the Fisher information matrix is positive-definite at , and singular at otherwise. We often say that a model (without specifying any parameter ) is regular if it is regular for all , and singular otherwise.
Note that the notion of a singular model is a purely geometric property: we have yet to discuss learning or Bayesian learning. We proceed to discuss that now. We aim to learn a data distribution over , which we have access to only indirectly via IID samples from . Our performance on this task is quantified by the negative log-likelihood or training loss, .
In a Bayesian setting, we have a prior distribution , and a (tempered) posterior distribution obtained via Bayes rule:
where is a normalizing constant and is a hyperparameter known as the inverse temperature. When this is the ordinary Bayesian posterior. Note that one sometimes chooses to be supported only in a neighborhood of a chosen point , in which case we call this a local posterior distribution [@quantifdegen].
Empirical Variance and the Singular Fluctuation
Define the Bayesian training error as the empirical Kullback–Leibler divergence from the posterior predictive distribution to the true distribution:
Define the Bayesian generalization error as the population Kullback–Leibler divergence from the posterior predictive distribution to the true distribution:
The expected asymptotic difference between these quantities is given by the singular fluctuation:
The singular fluctuation is a birational invariant appearing in many generalization formulas within SLT, including the difference between the Bayes and Gibbs generalization errors, or the difference between the Gibbs training error and Bayes generalization error.
Connection to the Loss Kernel
The loss kernel can be seen as a generalization of the empirical variance, the empirical estimator of the singular fluctuation. The empirical variance is defined as:
which estimates the singular fluctuation via
If we treat the negative log-likelihood as a per-sample loss, , and recall that the probe distribution coincides with the Bayesian posterior, this can be seen as the trace of the loss kernel evaluated on the training dataset :
From this perspective, the loss kernel can be seen as a per-sample generalization of the empirical variance, which further allows taking the covariance of two different samples, including possibly samples outside the training dataset .
Towards a Population Loss Kernel
The loss kernel introduced in the main text is an empirical object, computed from a finite training dataset of size . This section sketches the link between the empirical tool and what a population version might look like in the limit as , which is the natural setting of singular learning theory. We expect this to be an interesting direction for future theoretical work.
From Empirical to Population Loss. The loss kernel probes the geometry of the empirical loss landscape, . In the asymptotic limit, the law of large numbers implies that this converges to a function known as the population loss, . If the per-sample loss is the negative log-likelihood , it converges to the cross entropy (equivalently, KL divergence, up to a constant) from the true distribution to the model’s distribution :
Let . The geometry of the set as is intimately connected to the singularity theory of the function . The geometry in and is rich, often reflecting interpretable computational structure, which we might hope to use for interpretability [@murfet2025programs].
Posterior Concentration. The set has statistical meaning as well as geometric meaning. As the sample size goes to infinity, the posterior concentrates around for increasingly small . The intuition behind this is simple (the posterior increasingly concentrates around better and better hypotheses as it gets more data), and we describe part of this connection in Appendix A.3. However, we note that actually proving convergence is highly nontrivial for singular models and that @watanabe2009algebraic spends multiple chapters proving similar results. From the perspective of Bayesian statistics, this convergence means that the asymptotic geometry of controls statistical quantities like the generalization error [@watanabe2009algebraic]. For our purposes, it means that we can use the (local) posterior (the probe distribution, as we call it in the main text), whose properties can be estimated empirically using SGLD, to study the asymptotic properties of .
From Empirical Observables to Population Geometry. We have said that one can use the local posterior (empirical) to probe the local asymptotic properties of (theoretical). To ground our discussion, we give a concrete example of how one does so for a different tool, the local learning coefficient (LLC; [@quantifdegen]). Let be a closed ball about . The local learning coefficient can be defined as the unique such that asymptotically as :
for some constant and positive integer . This is the population quantity. It may be estimated in practice with a local posterior expectation value:
This type of relationship is precisely what we conjecture to hold for some suitably-defined “population” version of the loss kernel.
A Population Loss Kernel. In this paper, we do not define a population version of the loss kernel, but we expect this to be the start of a promising direction for future work. It seems conceivable that one could define such an object, and prove that it converges to the empirical loss kernel under some limit. From this perspective, the loss kernel as we have defined it in the main text would merely be an empirical estimator of the population loss kernel. By analogy to quantities like the LLC, we might expect the population version to have desirable theoretical properties, such as reparameterization invariance (see Appendix C of [@quantifdegen]). Most speculatively, one might even hope that such a population loss kernel could connect to information like “computational structure” reflected in the population geometry [@murfet2025programs].
Training Data Attribution
The loss kernel is a natural generalization of a class of techniques known as influence functions, which are used for training data attribution (TDA; [@cheng_training_2025]). This section clarifies the relationship between these objects.
Classical Influence Functions
Classical influence functions (IFs) measure how a model’s parameters and, consequently, any observable quantity, would change if a single training point were infinitesimally up-weighted [@cook_detection_1977; @influence-functions]. To formalize this, consider a training set and a tempered empirical average loss . Let be the parameter vector that minimizes this average loss. The influence of a training point on an observable (e.g., the loss on a test point) is defined as the sensitivity of the observable evaluated at this new minimum to a change in the weight :
Applying the chain rule and the implicit function theorem, one arrives at the well-known formula involving the Hessian of the training loss, :
This approach faces significant challenges with modern neural networks, where the Hessian is typically singular (non-invertible) and computationally intractable to compute.
Bayesian Influence Functions
The Bayesian Influence Function (BIF) offers a principled, Hessian-free alternative [@giordano_covariances_2018; @iba2025wkernel]. Instead of tracking a single point estimate , the BIF measures the sensitivity of the expectation of an observable under a tempered posterior distribution :
A standard result from statistical physics shows that this derivative is equal to the negative covariance over the untempered () posterior:
As proposed in [@singfluence1], this method can be adapted to analyze standard, non-Bayesian models by defining a local posterior that is constrained to the neighborhood of the trained parameters when combined with scalable SGMCMC-based estimators. This “local BIF” provides a practical tool for TDA that is well-defined even for singular models.
Connection to the Loss Kernel
The loss kernel differs from the BIF in three primary ways:
First, the BIF is unidirectional, measuring the influence of training points on (held-out) query points. This is because TDA focuses on provenance—tracing a behavior back to individual training samples. The loss kernel, in contrast, drops this distinction and directionality; it is the full symmetric, positive semidefinite kernel where entries measure functional coupling between arbitrary inputs—whether the model has encountered those samples during training or not.
Second, while influence functions focus on individual interactions between (groups of) samples, the loss kernel, as a kernel, shifts the focus to global functional organization. By applying techniques from kernel methods (e.g., UMAP), we use the loss kernel as a primary tool for interpreting the global structure of the data manifold “as seen by the model.” This comes with a caveat: it is possible to promote classical influence functions to a symmetric kernel and thereby to pull in these same kernel-derived methods. But in the classical paradigm, this operation lacks the same justification as we’re able to provide for the loss kernel in Section 2, Appendix A.1.
Finally, the loss kernel has deep theoretical grounding in singular learning theory (SLT) (see Appendix A.1). The diagonal of the loss kernel, , represents the per-sample loss variance, and its trace over the training set is an empirical variance, which is an estimator of the singular fluctuation, a key quantity that governs the model’s generalization error. We describe this connection in more detail in Appendix A.1.2.
From Sublevel Sets to Gibbs Distribution
This appendix establishes the formal relationship between expectations under the Gibbs distribution and integrals over the low-loss sets of an analytic loss function . We demonstrate that these quantities are related by the Laplace transform, which justifies our use of a statistical expectation about the probe distribution as a tractable tool for probing the geometry of the loss landscape.
We consider two related quantities for analyzing an observable . The first is the integral of over the -low-loss set , which defines a function of :
The second is the expectation of under the Gibbs distribution , which defines a function of the inverse temperature :
where is a normalizing constant and is the parameter space.
The following proposition details the precise relationship between and .
Proposition A.1 The Gibbs expectation is the Laplace transform of the low-loss integral , up to a known factor:
where denotes the Laplace transform with respect to .
Proof. By definition, the Gibbs expectation is given by
Using the coarea formula, we may rewrite the integral over as an iterated integral over the level sets of the loss function:
Recognizing that , the expression becomes the Laplace transform of the derivative of :
The derivative property of the Laplace transform states that . This yields:
The term is an integral over the set of global minima. If is analytic, has Lebesgue measure zero, which implies . The proposition follows.
Proposition A.1 provides the theoretical basis for our methodology. The invertibility of the Laplace transform implies that the family of Gibbs expectations contains the same information as the family of low-loss-set integrals. We opt for the statistical quantity for practical reasons: is amenable to gradient-based MCMC methods, making it computationally tractable for high-dimensional models. Furthermore, it provides a summary of the observable’s behavior over all loss levels, weighted naturally by the Gibbs factor, thereby obviating the need to select an arbitrary threshold . The Gibbs expectation is thus a practical and well-founded object for analyzing the properties of the low-loss subset.
Decoupling of Disjoint Mechanisms
This section provides justification for the prediction in Section 3 that a model that has learned disjoint mechanisms for independent tasks should have zero loss covariance between samples from different tasks, under the condition that the mechanisms involve non-overlapping weights.
Proposition A.2 Let a model’s parameters be partitioned into two disjoint sets, . Let the training data be partitioned into two disjoint sets and , corresponding to two independent subtasks. Assume the model has learned disjoint mechanisms, such that for any data point , its loss is a function only of , and for any , its loss is a function only of . Then, under the probe distribution, the loss covariance between and is zero:
Proof. Under the stated assumptions, the total loss on the dataset is additively separable:
The probe distribution is given by:
The spherical Gaussian localization term also factorizes over the disjoint parameter sets:
Substituting the separable loss and the factorized Gaussian into the probe distribution definition, we find that the probe distribution itself factorizes:
where and are the probe distributions for each sub-problem. This factorization implies that and are independent random variables under the joint posterior .
The covariance between the losses and is defined as:
Since is a function only of , and is a function only of , and and are independent, the expectation of their product is the product of their expectations:
Therefore, the covariance is zero:
This holds for any and .
While this sketch is illustrative, we note that it may be somewhat unrealistic to believe that deep learning models implement distinct mechanisms in disjoint sets of weights. See for instance the phenomenon of polysemanticity [@elhage2022superposition]. It may require a change of coordinates before mechanisms cleanly factorize. From a singular learning theory perspective, the correct remedy here is likely found at the level of population quantities, which are often invariant to arbitrary (diffeomorphic) coordinate change (see for example Appendix C of [@quantifdegen]). We discuss the possibility of a population loss kernel with such a property in Appendix A.1.3, but we largely leave that to future work.
Stochastic-Gradient MCMC Estimator
Evaluating the loss kernel requires Monte-Carlo samples from the probe distribution . Following [@quantifdegen], we use Stochastic Gradient Langevin Dynamics (SGLD; [@welling2011bayesian]).
Update rule. With stochastic mini-batch of size and step size , SGLD performs
The first term is the stochastic gradient of the loss; the second is the gradient of the Gaussian localization potential ; the injected Gaussian noise ensures asymptotic convergence to as .
Parallel chains and burn-in. To improve mixing we run independent chains, each initialized at . After discarding a burn-in of iterations, we retain draws per chain. For every retained weight we record the vectors .
Estimators. The unbiased plug-in estimators for and are:
where is the estimated average loss:
Batched evaluation. At each retained iteration , a full forward pass is performed over the entire dataset of interest to compute and store the loss vector . In contrast, the SGLD update in Equation B.1 only requires a single backward pass on a small, random minibatch .
Contrast this with the local Bayesian Influence Function (BIF; [@singfluence1]), which requires computing forward passes over two separate “attribution” and “query” datasets. We compute forward passes only over a single set, yielding an covariance kernel. This is effectively the same as treating every sample as both an “attribution” and a “query” point to measure the functional coupling between all pairs of inputs.
Avoiding spurious correlations. We observe that a high correlation between inputs of the same label often is spurious. At some SGLD hyperparameters, noise injected in the unembedding weights causes inputs of the same label to always slightly increase or decrease in loss together. This can dominate the observed correlations. Similar issues apply to per-sample gradient and activation based methods, where often the unembedding weights aren’t used in computation for the same reason. For example, we find that we can perfectly recover input labels by running SGLD for 10 steps on an untrained model. UMAP works via a fuzzy nearest neighbors lookup, and so to deconfound our UMAPs we delete edges between same label inputs during the neighbor finding step. This means two inputs of the same label will never be neighbors just because they share a label.
Hyperparameters Overview
Table B.1 summarizes the hyperparameter settings for the correlation kernel experiments. We sample with SGLD: is the batch size, is the number of chains, the number of draws per chain, is the number of burn-in steps, is the learning rate, is the inverse temperature, and is the localization strength.
Section | Model | Dataset | |||||||
|---|---|---|---|---|---|---|---|---|---|
Section 3 | 2 Layer Transformer | Modular Addition and Modular Division mod 97. | 512 | 30 | 800 | 200 | 500 | 30,000 | |
Section 4 | Inception-v1 | ImageNet | 256 | 15 | 500 | 100 | 20 | 4,000 | |
Section D.3 | Inception-v1 | ImageNet with 1,000 random samples mislabeled. | 256 | 8 | 1000 | 100 | 20 | 4,000 | |
Appendix D.2 | Inception-v1 | ImageNet | 256 | 5 | 1200 | 2000 | 20 | Varied |
Synthetic Task Extra
This section provides additional details for the synthetic multitask experiment presented in Section 3.
Model architecture. We use a two-layer transformer with the same architecture as that used in the original grokking experiments by [@power2022grokking]. We refer the reader to their work for specific architectural details. We make one modification which is to double the vocabulary, so that each task uses an independent set of tokens.
Tasks and dataset. The model was trained on a multitask problem comprising modular addition and modular division, both over the prime modulus . Inputs for both tasks are sequences of the form a, b, result. The use of non-overlapping vocabularies is sufficient to for the model to distinguish which operation must be performed.
Training and evaluation data were generated by sampling integers uniformly at random. For modular division , we compute , where is the modular multiplicative inverse of . We exclude cases where .
Training. The model was trained on both tasks simultaneously using the Adam optimizer until it achieved 100% accuracy on the training set.
Loss kernel estimation. After training, we estimated the loss kernel to analyze the learned functional structure. We used SGLD to draw samples from the local posterior distribution, localized around the final trained weights . We collected a total of 30,000 posterior weight samples after an initial burn-in period of 200 steps for each chain. The loss kernel was then computed over an evaluation set of 10,000 randomly selected inputs, evenly split between the modular addition and modular division tasks. The specific SGLD hyperparameters, including learning rate , inverse temperature , and localization strength , are provided in the main hyperparameter summary (Table B.1).
ImageNet Extra
Inception-v1
We apply our method to Inception-v1 [@szegedy_going_2014]. Each Inception-v1 experiment evaluates posterior correlations over 10,000 ImageNet validation samples, while sampling over the full ImageNet [@deng2009imagenet] training dataset. To reduce memory overhead, we downscale all images to 256x256 resolution. Full hyperparameters are included in Table B.1. We find that the quality of correlations depends significantly on total draws used: see Appendix D.2 for extended discussion.
Quantifying Hierarchical Structure
To move beyond visual inspection, we quantitatively assess how well the kernel’s structure aligns with the WordNet hierarchy.
Taxonomic lift construction. For each validation image with WordNet label at depth , we take its top- neighbors under the correlation kernel (we use ). For any candidate ancestor depth , define
where means “ is an ancestor of label ” in the ImageNet–WordNet hierarchy (equivalently, ). We condition on query depth to avoid confounding from the uneven leaf-depth distribution. Curves in Figure D.1 report versus the depth of the shared ancestor (i.e., tree distance from the root), with one curve per query depth .
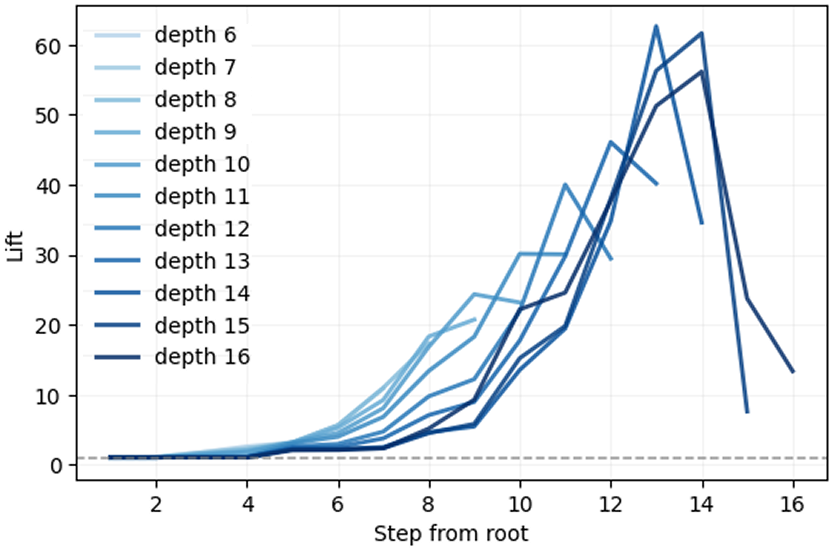
Taxonomic lift vs. hierarchy depth. Lines depicts the weighted probability (lift) that the nearest neighbors of an input with a label nodes deep in the WordNet hierarchy will share a parent node at depth . The —axis is the WordNet tree distance (edges) from the root to the shared ancestor. We report lift as the ratio of this probability to the dataset base rate at depth. See Appendix D.1 for details.
Estimation details. We evaluate on validation images and average the probability over queries with depth . We exclude identical-label pairs when constructing neighbors to avoid trivial lifts; The decrease towards the end of lines for larger is because nodes deep in the hierarchy often have few children.
Interpretation. Lift indicates that kernel-nearest neighbors are more likely than chance to share a taxonomy node at depth . We observe: (i) lift increases with query depth (deeper, more specific classes show stronger taxonomic cohesion); (ii) lift peaks at intermediate and tapers near the root (ancestors too coarse) and near leaves (sparsity reduces shared-ancestor opportunities), consistent with the qualitative UMAP and the correlation–distance decay in the main text.
Hyperparameter Dependence
Convergence of the estimator.
Centered Kernel Alignment (CKA) is a similarity measure between two kernel (or Gram) matrices. Given kernels , the CKA is defined as
where and denote the centered versions of and , and is the Frobenius inner product. This normalization ensures that , with 1 indicating identical representational structure.
CKA analysis reveals the consistency and similarity of representations across different training runs and sampling procedures. We can use it to compare the kernels we get at different hyperparameters, but also how the kernel evolves as total SGLD step count increases. Figure D.2 A shows how the CKA between the kernel at step of SGLD and the kernel at the final step changes as a function of . Note that is total steps over all chains and that we limit individual chain. We find that higher leads to faster convergence. Similarly, Figure D.2 B shows the CKA between kernels computed using different parameters. At high the CKA between kernels is close to 1, meaning the kernel is robust to specific choice of .
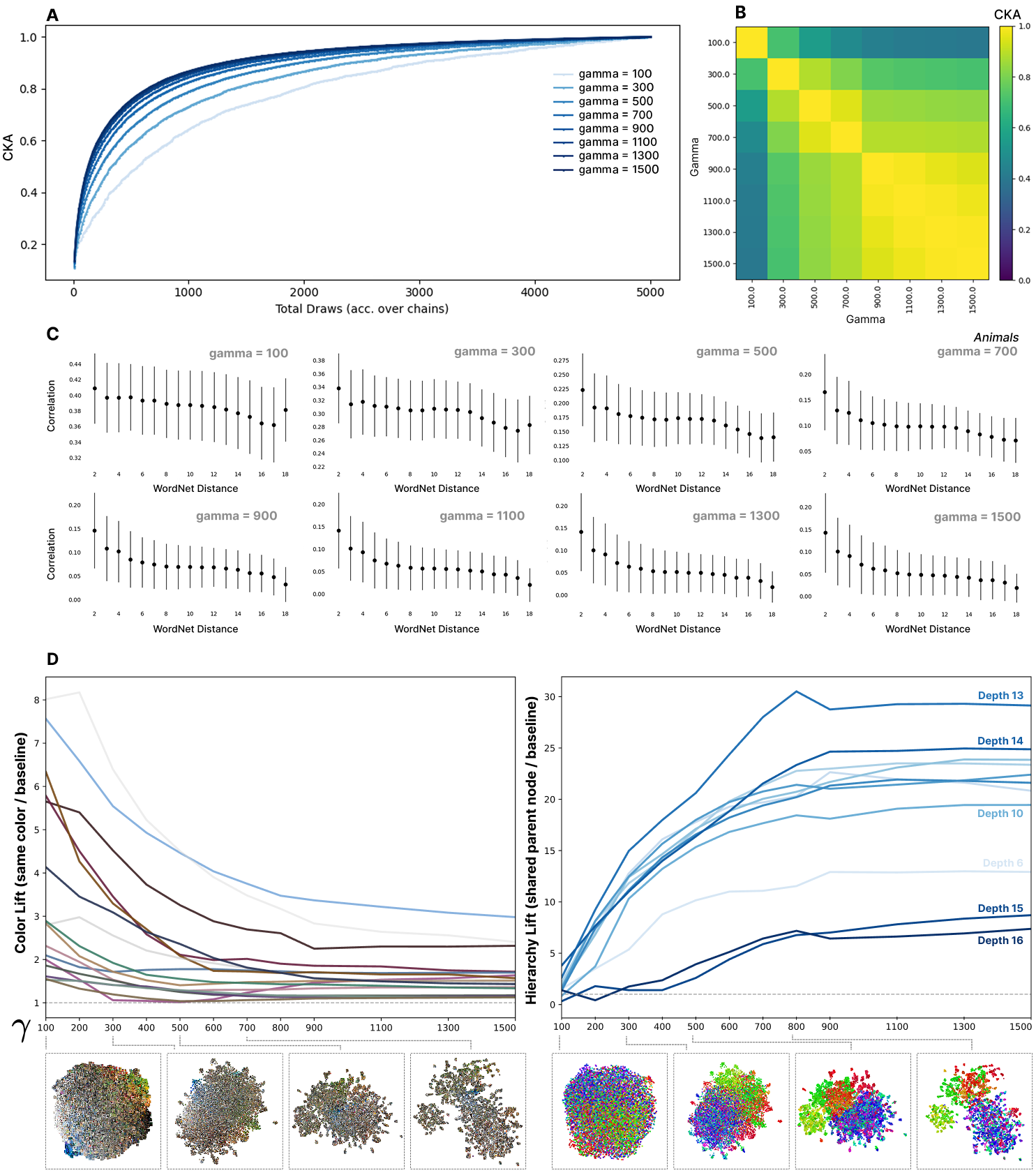
Dependence of the kernel on the SGLD hyperparameter . A: CKA between the kernel at step of SGLD and the final step of SGLD. Shows how the kernel converges as a function of total draws taken. B: CKA between kernels computed using different values. The kernel stabilizes between and . C: Loss kernel correlation vs distance across the WordNet hierarchy for animal inputs. As increases inputs closer in the hierarchy become relatively more correlated than inputs further away in the hierarchy, showing that gamma controls how reflected the hierarchy is in the kernel. D: Lift (neighbor match rate divided by base rate) for color (left) and ImageNet–WordNet node (right) as varies. Low emphasizes low-level cues (high color-lift); increasing suppresses color-lift while strongly increasing hierarchical coherence. UMAPs beneath each curve illustrate the same trend qualitatively.
The effect of . Recall that the hyperparameter controls how tightly the probe distribution is concentrated around in parameter space. Empirically, Figure D.2 D quantifies this trade-off with a simple lift metric (the weighted probability that a sample’s nearest neighbors under the loss kernel share an attribute, divided by that attribute’s base rate). At low , neighbors are disproportionately matched by low-level cues such as color (high color-lift); as increases, color-lift falls while hierarchical coherence (neighbors sharing nearby nodes in WordNet) rises sharply. We detail how we group inputs by color in Appendix D.4 – we use the groupings to compute the same way we compute per-node lift in Appendix D.1.
UMAP snapshots beneath each curve show the same transition qualitatively: low yields broad, texture/color-organized neighborhoods, while high foregrounds semantically tight groupings aligned with the taxonomy. Specific per-experiment hyperparameter settings are detailed in the below section.
Detecting Memorization
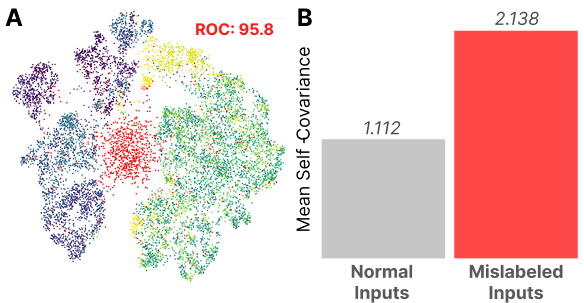
A: A UMAP visualization of the loss kernel for an Inception-v1 model trained until convergence on ImageNet with samples mislabeled. Mislabeled inputs (red) form a distinct cluster. We report an ROC of 95.8 for detecting mislabeled points using per-sample loss variances . B: The mean self-covariance, or singular fluctuation, of normal (1.112) and mislabeled (2.138) inputs.
We test whether the loss kernel is sensitive to changes in the functional constraints imposed on the model by making a targeted change to the model’s training data distribution. We randomly mislabel a subset of the training data, forcing the model to memorize in order to achieve a low loss.
Memorization imposes a strict functional constraint on our model. A very precise weight setting is required to achieve high performance – put simply, the set of parameters that achieve low loss on the mislabeled set forms a much narrower region (a sharper basin) than the region that preserves low loss when the mapping can be supported by shared features.
As detailed in Appendix A.1, the trace of our kernel is an estimator for the singular fluctuation, a quantity that appears in the asymptotic formula for the Gibbs generalization error. The kernel itself can be seen as measuring the first-order change in a related quantity known as the Bayes generalization error, with respect to the importance of each data point. While these notions of generalization are not immediately related to the type of memorization we study empirically, this provides some intuitive support to the idea that memorized examples will show up with a large self-correlation .
The loss kernel over Development.
To visualize how functional geometry emerges during learning, we compute the loss-correlation kernel at fixed training checkpoints and embed the induced distances with the same UMAP hyperparameters across time (and with same-label edges removed; see Appendix B).
Figure D.4 shows a coarse-to-fine trajectory. Bar a handful of curious outliers, at initialization the kernel is essentially structureless. We leave study of these outliers to future work. By step 710, a weak global anisotropy appears that roughly separates animate from inanimate classes. By step 1388, coherent clusters begin to form (e.g., Dogs). At step 3290, many subgroups sharpen and separate, and by step 5298 the geometry stabilizes into well-defined, semantically coherent regions that mirror the WordNet hierarchy.
Evolution of the kernel over training. UMAPs of the loss kernel taken at various steps over training, for an Inception-v1 model trained on ImageNet. Between initialization (top left) and step 710 (top middle) the model begins to distinguish between animals and things – A gradient of differentiation is established. At step 1388 (top right) significant structure is apparent, with Dogs forming an early cluster. Step 3290 (bottom right) sees many subgroups forming distinct clusters. By step 5298 (bottom left) the kernel is fully formed.

Average color–neighbor probabilities, for low and high . Stacked barchart versions of transition matrices, where a transition can be made from an input to its top (first row) or bottom (second row) 30 correlated inputs. The probability of a transitioning from an image “close to color” on the -axis to an image “close to color” is given by the height of ‘s bar in the stack. The right column shows the transition matrix obtained when using during sampling, while the right shows the results for . For we see significant color striation in both rows, especially in the bottom correlated inputs (e.g., blue inputs have pronounced low correlation with orange inputs). Contrastingly patterns visible in are much more uniform.
Quantifying Color Lift.
We describe our method for computing the average per-color lift as shown in Figure D.2 and Figure D.5. In order to compute the lift we must bucket images into discrete color groups. To do so, for each input image, we compute
where is the number of pixels in image , and , , are the red, green, and blue values of pixel in image . (Equivalently, , where each bar denotes the mean over all pixels in image .) 2) Cluster the set into groups using farthest point sampling (FPS). FPS ensures that cluster centers are spread out over the uneven distribution of RGB means (e.g., many gray/brown tones).
Extra ImageNet Examples
We provide more examples of the top correlated inputs from the visualization experiment in Section 4 and Figure 3. These inputs were randomly selected in chunks of 10 from between the 600th and 700th inputs of the 2500 for which we computed the loss kernel. The full set top-correlated inputs for all 2500 inputs is available at https://github.com/singfluence-anon/sf_imagenet_corrs.

Top 15 correlated inputs with reference input (randomly selected references). Reference images are the leftmost column.
Top 15 correlated inputs with reference input (randomly selected references). Reference images are the leftmost column.
Acknowledgments
Author Contributions
Cite as
@article{adam2025the,
author = {Maxwell Adam and Zach Furman and Jesse Hoogland},
title = {The Loss Kernel: A Geometric Probe for Deep Learning Interpretability},
year = {2025},
url = {https://arxiv.org/abs/2509.26537},
eprint = {2509.26537},
archivePrefix = {arXiv},
abstract = {We introduce the loss kernel, an interpretability method for measuring similarity between data points according to a trained neural network. The kernel is the covariance matrix of per-sample losses computed under a distribution of low-loss-preserving parameter perturbations. We first validate our method on a synthetic multitask problem, showing it separates inputs by task as predicted by theory. We then apply this kernel to Inception-v1 to visualize the structure of ImageNet, and we show that the kernel's structure aligns with the WordNet semantic hierarchy. This establishes the loss kernel as a practical tool for interpretability and data attribution.}
}