Automated Conversion Notice
Warning: This paper was automatically converted from LaTeX. While we strive for accuracy, some formatting or mathematical expressions may not render perfectly. Please refer to the original ArXiv version for the authoritative document.
1 Introduction
A central challenge in deep learning is to measure a model’s complexity, that is, the amount of information about the dataset that is encoded in its parameters. This cannot be trivially derived from the loss because there are ways to achieve a given level of loss that involve different quantities of information: for example, the network can memorize the training data (encoded using a relatively large fraction of its weights) or discover a general solution (encoded using a small number of weights). A measurement that could distinguish these two kinds of solutions would be useful, for example, in predicting how a network will behave out of distribution. How then are we to measure this quantity?
One simple practical answer involves compression: given a loss tolerance and some compression scheme with parameter (such that larger means more compression) let be the amount of compression that increases the loss from its original value up to the threshold . Intuitively, if the network encoded its solution to the constraints in the data using a small fraction of its weights, then it could “withstand” a large amount of compression and will be large. If the network has used all of its capacity to encode the solution then we expect to be small. Given the practical importance of compression techniques like quantization, this seems like a useful measure of model complexity. However, the theoretical status of this notion of “compressibility” is a priori unclear.
The informal relationship between compressibility and complexity goes back to LeCun et al. (1989); Hochreiter and Schmidhuber (1997) and has been the basis for theoretical bounds on generalization error (Arora et al., 2018). It is clear that compressibility in the above sense must be related to ideas like minimum description length (MDL; Grünwald and Roos 2019). In this paper we investigate the relation between various practical compression schemes and MDL via singular learning theory (SLT; Watanabe 2009) and the estimator for a measure of model complexity known as the local learning coefficient (Lau et al., 2024) and in this way provide some theoretical basis for the intuitive connection between compressibility and complexity in the setting of deep learning.
Contributions.
We make the following contributions:
-
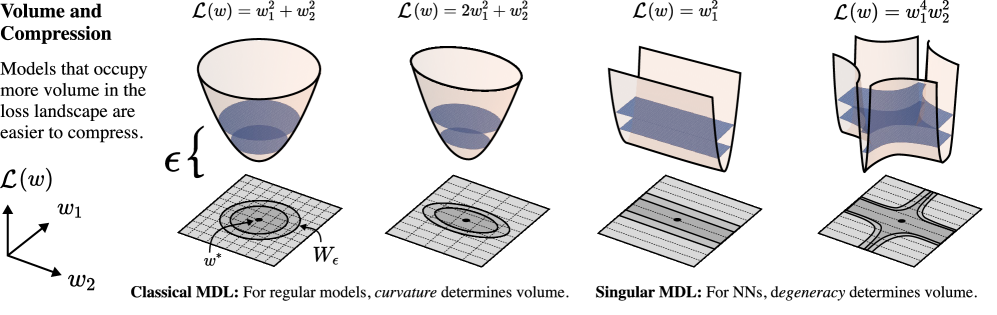
We derive a singular MDL principle (Section 3): Using ideas from singular learning theory (SLT; Watanabe 2009), we extend the minimum description length (MDL; Grünwald and Roos 2019) principle to neural networks and prove that there is a two-part code for which the asymptotic redundancy involves the local learning coefficient (LLC; Lau et al. 2024), a measure of model complexity from SLT. In contrast to the classical treatment of MDL, where geometric invariants like the curvature determined by the Hessian appear in the description length, the important geometric feature in the singular case is degeneracy (Figure 1).
-
We compare the LLC to compressibility: in the setting of compression via quantization and factorization we study empirically the relation between compressibility and the LLC, by plotting them against each other for a range of models form the Pythia family up to 6.9B parameters, across training checkpoints. As expected we find that models with larger LLCs tend to be less compressible. For quantization we observe a particularly close relationship: over a large fraction of training steps there is a linear relationship between the estimated LLC and the compressibility measured in bits.
From these results we draw two main conclusions. Firstly, the informal notion of compressibility as a measure of model complexity is consistent with the LLC estimate, which has a sound theoretical foundation. Secondly, compressibility in Pythia models serves as an independent check on the practice of using LLC estimates for models at these scales; this is valuable since we lack theoretical knowledge of the true LLC for large transformer models (see Section D.2).
2 Related Work
Network compression in deep learning.
There is a large literature on model compression, which is evolving rapidly. A standard reference is Han et al. (2016), and newer surveys include Hoefler et al. (2021); Wang et al. (2024b). It has long been recognized that the “effective dimension” of deep neural networks is typically much smaller than the number of parameters (Maddox et al., 2020). This is widely understood as one reason why model compression is possible (LeCun et al., 1989; Hassibi et al., 1993; Denil et al., 2013). Pruning models by discarding small magnitude weights, or using the spectrum of the Hessian to determine low saliency weights, coupled with the empirical success of such pruning methods, has led to an informal working understanding of effective dimension in terms of “how much compression can be done without sacrificing too much performance.” Nonetheless, the theoretical basis for using, e.g., the Hessian spectrum to determine effective dimension remains weak. The existence of “lottery tickets” (that is, sparse and trainable subnetworks at initialization) also suggests a large degree of redundancy in the final trained parameter (Frankle and Carbin, 2019).
Intrinsic dimension of fine-tuning.
Related to, but distinct from, the low effective dimension of trained neural networks is the low observed “intrinsic dimension” of fine-tuning pretrained LLMs (Li et al., 2018). Here the intrinsic dimension refers to the minimum dimension of a hyperplane in the full parameter space in which the fine-tuning optimization problem can be solved to some precision level. This can be many orders of magnitude smaller than the full dimension; for example, Aghajanyan et al. (2021) note that parameters are enough to solve a fine-tuning problem for a RoBERTa model (with 335M parameters) to within 90% performance of the full model. This observation that the update matrices in LLM fine-tuning have a low “intrinsic rank” led to the introduction and widespread usage of low-rank adaptation for fine-tuning (Hu et al., 2022). The relation of this intrinsic dimension to the effective dimension of the full pretrained model is unclear.
For additional related work see Appendix A.
3 Theory: Singular MDL
MDL is the canonical theoretical framework that relates compressibility and model complexity. The idea of measuring the complexity of a trained model or at a given local minimum of the population loss landscape is well-known in the literature on MDL (Grünwald and Roos, 2019) and was used by Hochreiter and Schmidhuber (1997) in an attempt to quantify the complexity of a trained neural network. However, these classical MDL treatments make the assumption that models are “regular” meaning that the parameter-to-distribution map, , is one-to-one (which implies that there is a unique global minimum) and that the Fisher information matrix, is everywhere non-singular (middle-left panel of Figure 2). Since this assumption is invalid for neural networks, the resulting theory does not apply. In this section, we start from the MDL principles and use insights from SLT to extend its applicability to singular models like ANNs.
3.1 Setup
Let denote a sample space and let be an unknown data-generating distribution on the space of -sequences of length . We assume that is finite (e.g., the token vocabulary for modern transformer language models). Any distribution on gives rise to a prefix-free (thus uniquely decodable) encoding, , for any with code length given by . Conversely, every prefix-free encoding can be used to define such distributions (Kraft, 1949; McMillan, 1956), which we shall call an encoding distribution.
A central observation of the MDL principle is that any statistical pattern or regularity in can be exploited to compress samples of . If a learning algorithm can extract these regularities through only samples , then it has implicitly learned a good compression of . This is the oft-invoked principle of “learning as compression”. Throughout, we will consider learning machines with a finite-dimensional parameterized statistical models, denoted as where is a compact -dimensional parameter space. An important example for this work is the case of modern auto-regressive language models where are the token sequences and the model takes the form
for some learned sequence-to-next-token model , such as a transformer (Vaswani et al., 2017).111This is an example of what is known as prequential code in MDL literature. For exposition, we will focus on the case where both the data and model are independent and identically distributed (i.i.d., see discussion of assumptions in Appendix F). This means that, for every , the data distribution and model distribution on are respectively given by
for some unknown and model . Under such assumptions, the unique minimum average code length in the long-run (large ) is achieved by setting the data generating distribution itself as the encoding distribution, i.e., setting . The expected per-symbol excess length compared to this minimum is measured by the Kullback-Leibler (KL) divergence,
where denotes the (cross-)entropy. We will call the first parameter-dependent term above the population loss and denote it as . Note that the empirical estimate of given by is the usual per-token cross-entropy criterion used for training modern transformer network, also known as the average negative log-likelihood at .
3.2 Two-Part Codes
We will focus on the case of two-part codes to clarify the underlying geometrical phenomenon and explain the direct relevance to neural network compression. To communicate with two-part codes, the sender and receiver agree to first communicate an encoding distribution by sending some encoded representation , before sending the data encoded with , . Once is received, the receiver can reconstruct the encoding distribution and decode any message encoded with . The result is a message of length
One measure of code performance, known as redundancy, is defined to be the excess code length as compared to the encoding generated using the data distribution itself as encoding distribution. So, if the data is drawn i.i.d. from , then the redundancy of the two-part code is given by
| (1) |
Notice that if the chosen encoding distribution is sufficiently good in the sense of having small KL-divergence, , from , then it is worth paying bits to obtain a cheap encoding for samples drawn from .
Suppose the sender and receiver have a shared knowledge of a finite dimensional statistical model (e.g., a neural network architecture). This allow them to communicate using codes specific to the biases implicit in the model architecture. In other words, the model provides an implicit prior on the set of distributions , allocating codes of varying length depending on which hypotheses are considered simple or complex.
To the state the main theorem let be a statistical model of finite dimension . We will assume some technical conditions on the model laid out in Appendix (E.1). In particular, we require that all distributions in our models are in the restricted simplex of uniformly lower bounded distributions where given and a distribution over we say if .
Theorem 1.
There exists a two-part code such that, for any realizable data generating distribution and dataset drawn i.i.d. from , the asymptotic redundancy is
where is the learning coefficient of for the model and is the multiplicity.
We refer to Watanabe (2009) for the definition of the learning coefficient and multiplicity .
To establish this result, we need to specify a way for the sender to communicate a specific hypothesis or distribution in the model. We note that a model generally contains uncountably many distinct distributions, yet any parameter encoding can specify at most countably many. Thus, discretization is needed. We assume the sender and receiver have a way to construct, for any , shared finite sets such that any belongs to some set of the form where 222This is a finite -net of the model in distribution space.. Let us define (R for Reversed)
Given , we assume a consistent and shared algorithm for choosing333breaking ties consistently when needed such that and .
Observe that this produces a partition of the model, , with each set in the partition represented by a grid point in 444possibly a smaller set, in which case we take to be this non-redundant set. Ideally, we would like a tight -KL-sphere packing. If is a subset of the interior of simplex, itself, with non-empty interior, we can use construction similar to Balasubramanian (1996) to obtain such an -net.. We will then assign probability555this is only an approximate equality because the true volume should be the volume of the partitions instead of those of the -nets. However, their difference can be made small via careful selection of centers and sphere packing arguments. to and therefore a code of length
Notice that this is very different from putting the uniform distribution on (e.g., by using the Jeffrey’s prior on if is regular). We are deliberately assigning shorter codes to hypotheses that are simpler according to the model’s own implicit bias: a hypothesis is simpler to state relative to a given model if it takes up more parameter volume (requires lower parameter-precision to specify its distribution) up to error tolerance.
With such a construction, we can now calculate the two-part code length with respect to some model for i.i.d. data drawn from data distribution that is realizable () and satisfies assumptions in Appendix (E.1). Let be the maximum likelihood distribution and define be the grid point in closest to , . To send the data we send the encoding of and the data encoded with this distribution. Writing the redundancy of the code at tolerance is given by
| (2) | ||||
| (3) |
Now, we introduce a dependency of the tolerance on by for some . With this assumption, both and are by Theorem 5 and Theorem 3 respectively. Therefore, the redundancy is given asymptotically by
In (3) we see a fundamental tradeoff: decreasing the error tolerance (a finer grid) decreases the excess code length because we can find a grid point closer to and thus , but decreasing the tolerance will also decrease the volume and thus increase the cost for communicating . Similar to the case for regular models (see for example Balasubramanian (1996)), the optimal grid size for data set of size scale as : any higher order rate of decay for implies a finer distinguishability of grid points than the number of data points can justify (the MLE itself has , see further discussion in Appendix E.4).
It remains to determine the behavior of the . One difficulty is that the center is a random variable depending on data and changes with . However, it is also clear that, as , approaches in KL-divergence to the data generating distribution . Furthermore, the relevant volume will also be similar to that of the set of parameter where is close to defined by . Theorem 4 shows that there exist such that for any and such that we get
| (4) |
This allows us to make conclusions about , for such that , by investigating . To do that, we invoke a central result of SLT:
Theorem 2 ((Watanabe, 2009; Arnold et al., 2012)).
Let be a non-negative analytic function. Then there exist and , such that the volume of the -sublevel sets is given by as for some constant .
Applying this theorem to the map and using Equation (4), we get
Using the fact that as for any , we conclude there exist such that for sufficiently small ,
| (5) |
This in turn implies666note that Equation (5) shows that for .
| (6) |
Finally, recalling that we took grid scale to be . For sufficiently large , this implies that with high probability by Theorem 5. Therefore, the result about in Equation (6) applies and plugging in expression for , we get
which concludes the proof for Theorem 1. Notice that the leading order terms above can be interpreted as model complexity: it is the code length required to communicate a sufficiently good encoding distribution in the model while maintaining an excess length for the encoded message even when the number of sample .
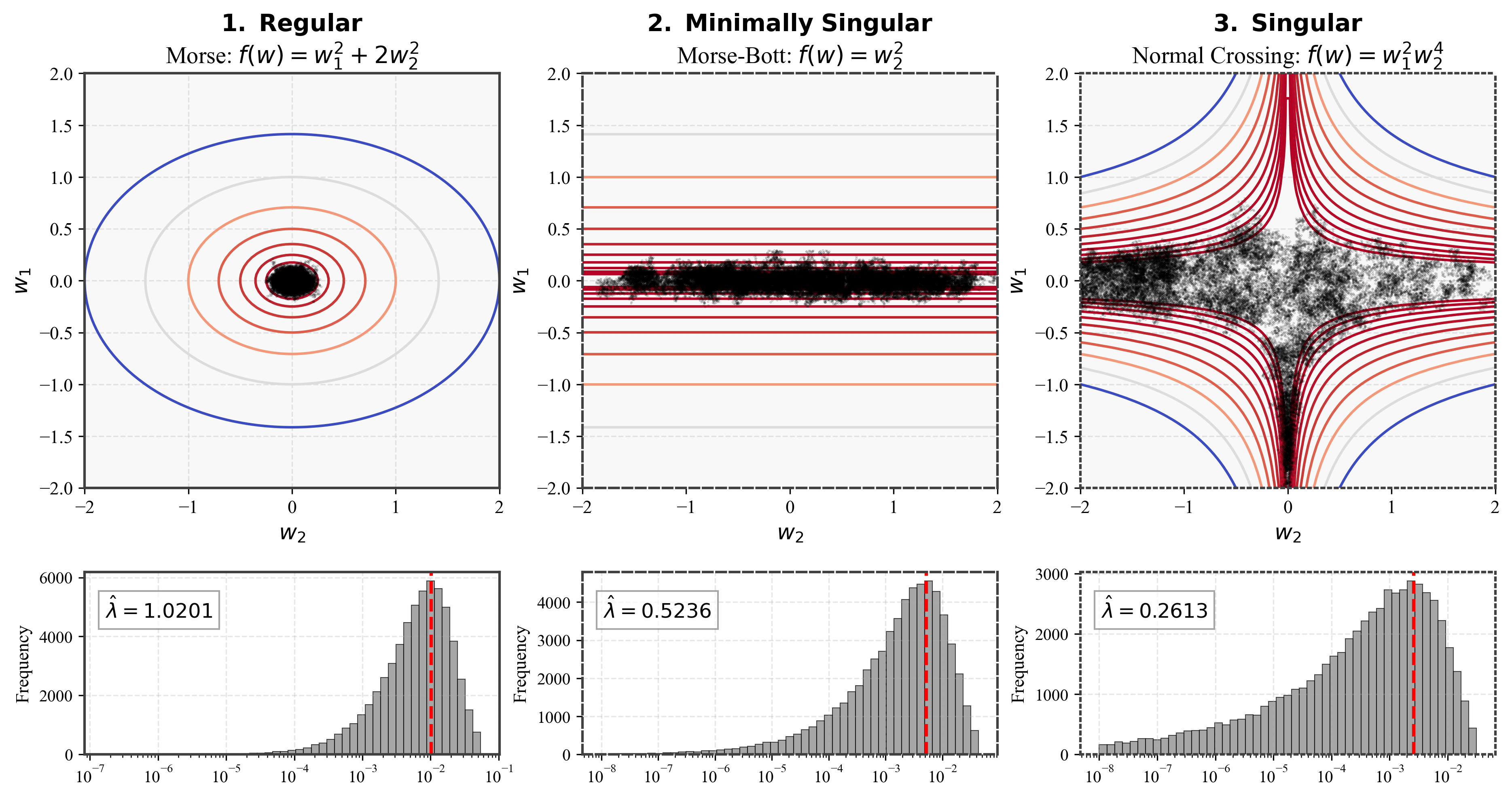
We remark that Theorem 2 is a consequence of the celebrated theorem on the resolution of singularities by Hironaka (1964). The scaling exponent is known as the real log canonical threshold (RLCT) of the analytic function and is its multiplicity. Watanabe (2009) was the first to make use of the resolution of singularities and thereby connect these geometrical invariants to statistical learning, showing that gives the leading-order term for model complexity and gives the leading-order term for generalization error in Bayesian learning. In the context of machine learning, is referred to as the learning coefficient. For regular models, the sublevel sets look ellipsoidal (Figure 2 top-left), with volume and thus the learning coefficient is where is the parameter count. Its multiplicity is . Indeed, there are simpler two-part code construction for regular model that achieves by just having regular rectangular grid in of scale (corresponding to KL-divergence scale of in the space of distributions). Observe that this leading order behavior of for regular model is independent of data distribution . For singular model, , which means models can potentially be much more compressible than their explicit parameter count suggests. Figure 2 (top-middle and top-right) illustrates how the sublevel sets can have complex geometry with degeneracies, resulting in larger sublevel set volume that allow for higher level of compressibility.
3.3 Relation to compressibility
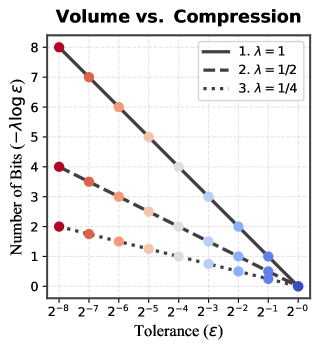
In the previous section we established the existence of a two-part code in which the leading term of asymptotic redundancy (excess code length compared to the encoding which we would use if we knew the true data distribution) is where is the learning coefficient.
This is directly related to compression (Grünwald and Roos, 2019) as it tells us the number of bits needed to communicate a set of samples between a sender and receiver who share a statistical model. This MDL perspective captures the idea that a model class which allows for simpler representations of a given data distribution (smaller ) offers better compression of its samples. However, it remains to explain how any given practical compression scheme (e.g., quantization) fits into this story. In this section we provide a less formal argument based on the concepts introduced in the previous section which aims to explain this connection in a straightforward way.
From a mathematical perspective parameters live in a continuous space , but any realization in a computer uses some kind of grid with spacing . Fix a local minimum of the population loss and define the local excess loss . We consider only parameters in a neighborhood near that is small enough that is non-negative. Invoking the sublevel-set volume law (Theorem 2), there exist numbers and such that
| (7) |
Here and are known as the local learning coefficient (LLC) and multiplicity, introduced in Lau et al. (2024). Our in the remainder of this section is to connect the resolution to the loss tolerance through the LLC .
Consider the quantization cell around a parameter with a volume proportional to . To guarantee that quantization does not increase excess loss beyond , it is sufficient that the cell containing be contained in the -sublevel set around . A surrogate for this containment is the volume condition or
| (8) |
If we write for the number of intervals for each coordinate in our grid, then this behaves like . We denote by and the level of quantization that reaches the loss tolerance and therefore makes (8) an equality. Hence, writing the per-coordinate bit budget as we have
| (9) |
Thus, for a fixed loss tolerance the critical bits per coordinate grows linearly with the LLC. Intuitively with larger (less degeneracy), the admissible basin is smaller, so smaller cells (finer grids, more bits) are needed to keep the entire cell inside the basin. This is illustrated in Figure 2.
4 Methodology
In order to complement the theory on the singular MDL principle, we study how compressibility relates to local learning coefficient (LLC) estimates in practice. In the main text we focus on quantization (Section 4.1). In the appendices, we also treat tensor factorization (Section C.2), pruning (Section C.5) and adding Gaussian noise to the model parameters (Section C.4). For estimating the LLC, in Section 4.2, we describe a preconditioned variant of the estimator in Lau et al. (2024).
4.1 Quantization
We quantize models using a symmetric quantization scheme that includes . Given and we divide the intervals and into intervals of length so that in each interval there are possible values lying at the endpoints of subintervals (including and ). Combining these to form and accounting for double counting of there are intervals and possible quantized values. To quantize a parameter with means firstly to “clamp” each to the interval and then round these values to the nearest quantized value in this interval according to the above subdivision. More precisely we define and . Note that specifying each requires bits.
In Section 5 we treat as a free parameter and search for a value that minimizes the loss of the quantized model. This is our baseline method, inspired by a more sophisticated approach in Cheong and Daniel (2019) where they allow for non-evenly spaced quantization intervals.
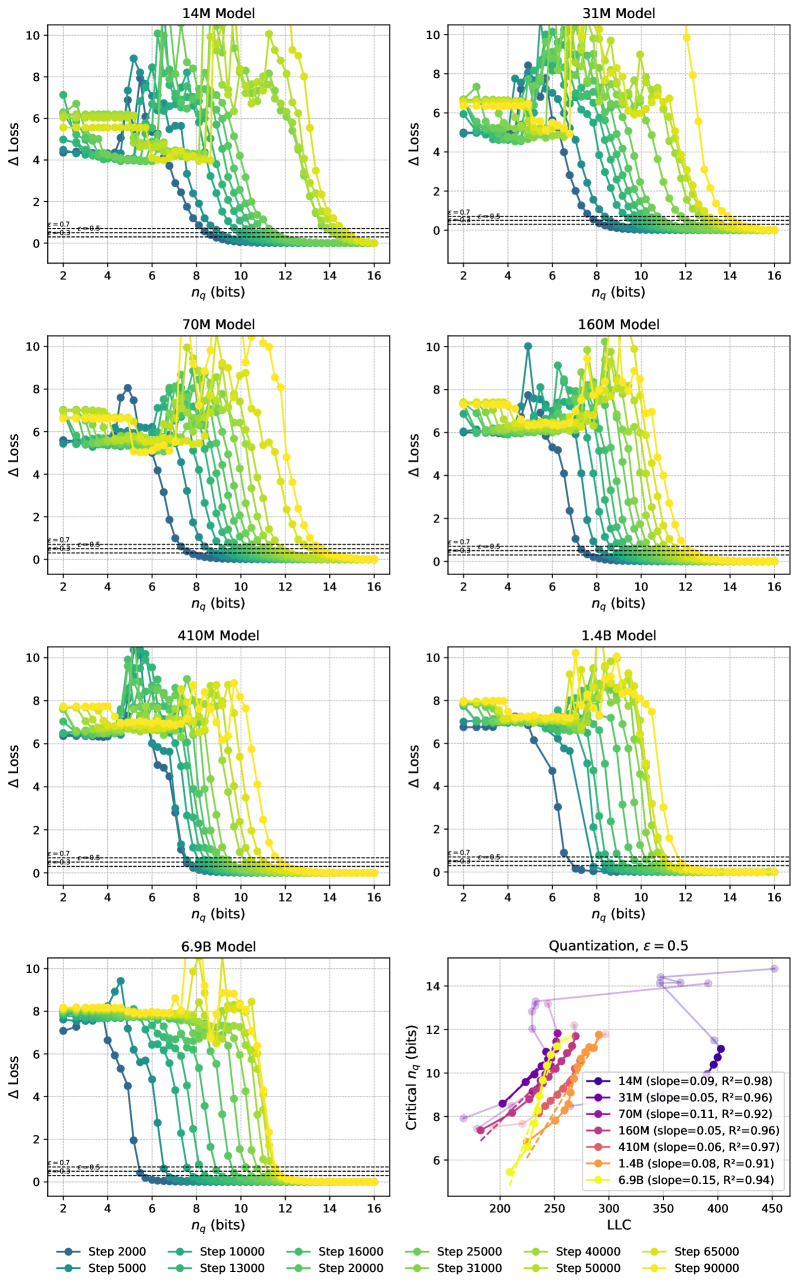
The increase in loss caused by quantization is a function of and . This is typically larger when is smaller. We measure the compressibility of a language model with parameter by finding the smallest with and call this value the critical and denote it . When is large the model is less compressible (we hit the threshold with a smaller amount of compression), and conversely when is small the model is more compressible.
In Section C.3 we show results of the cruder quantization method of setting to the largest parameter absolute value, which is equivalent to the scheme used by Kumar et al. (2025).
4.2 LLC estimation
We consider a transformer neural network that models the conditional distribution of outputs (next tokens) given inputs (contexts), where represents the network parameters in a compact parameter space . Given samples from a true distribution with associated empirical loss , we define the estimated local learning coefficient at a parameter point to be:
| (10) |
where is the expectation with respect to the Gibbs posterior (Bissiri et al., 2016),
| (11) |
The hyperparameters are the sample size , the inverse temperature , which controls the contribution of the loss, and the localization strength , which controls proximity to . For a full account of these hyperparameters, we refer the reader to Watanabe (2013); Lau et al. (2024); Hoogland et al. (2025). Our LLC estimation procedure uses the preconditioned stochastic gradient Langevin dynamics (pSGLD) algorithm (Li et al., 2015). This combines RMSNorm-style adaptive step sizes with SGLD (Welling and Teh, 2011). For more details on LLC estimation and its uncertainties, see Appendix D.
5 Results

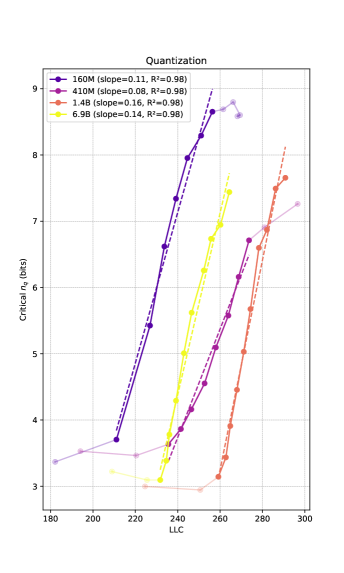
In this section we give experimental results relating compressibility under quantization with LLC estimates. For results on tensor factorization see Section C.2. As explained in Section 4.1, given a loss threshold we measure compressibility by the critical number of quantization intervals at which the increase in loss hits the threshold.
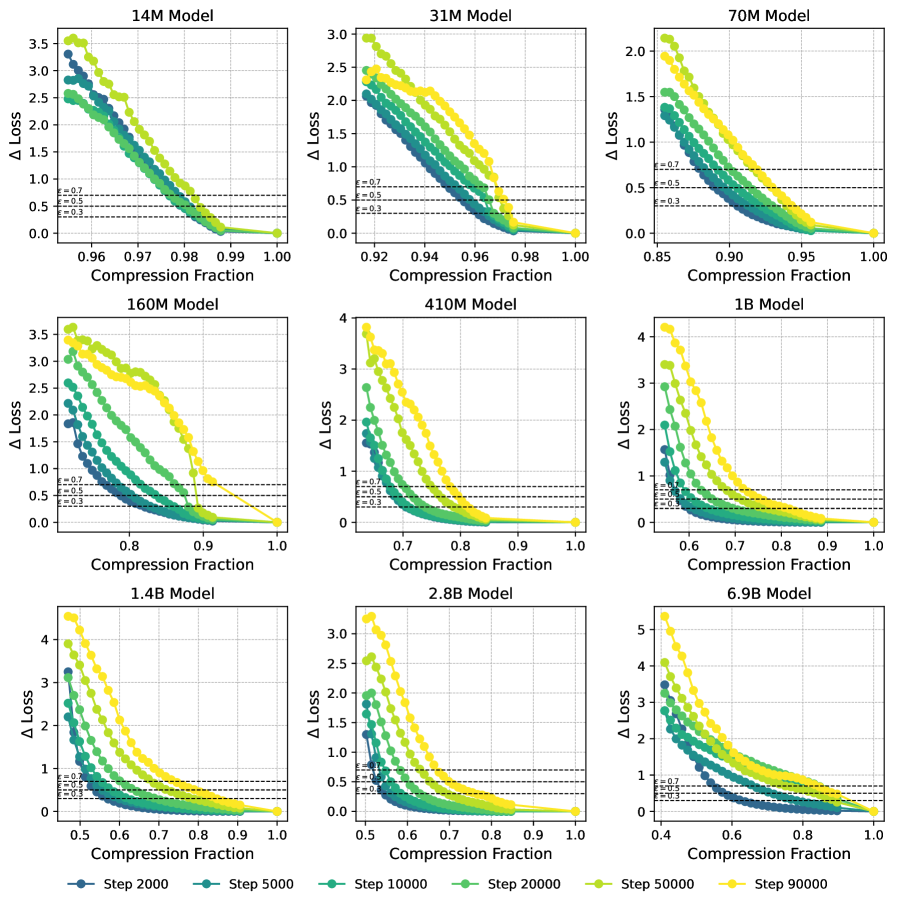
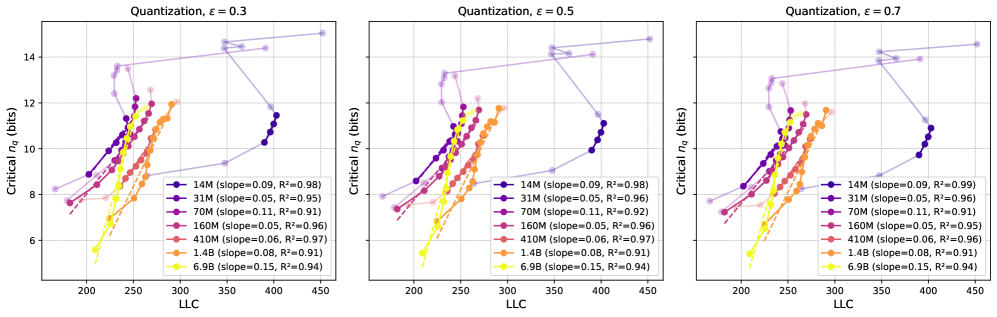
In Figure 3, left side, we show the increase in loss due to compression as a function of the number of quantized values, . We observe the loss curves featuring a knee at a loss increase of around , and we therefore choose this as our loss tolerance. In the appendix, we show a selection of other values, showing that they lead to similar results. In the panel to the right, we observe the critical increasing linearly with the LLC for a large range of training steps, as expected from (9). We find a linear fit with for all the shown models. In Section C.1 we show results for additional Pythia models, showing that these also feature ranges of training checkpoints with a linear relation between critical and LLC.
6 Conclusion
We have established a theoretical foundation for understanding neural network compression through the lens of singular learning theory, extending the minimum description length principle to account for the degenerate geometry of neural network loss landscape. Our experiments demonstrate that the local learning coefficient (LLC) provides a principled measure of compressibility, with model checkpoints featuring larger estimated LLC proving to be less resistant to compression across multiple compression techniques including quantization and factorization.
The strong linear relationships observed between LLC estimates and critical compression thresholds for quantization () is an independent check that our current SGLD-based estimates are capturing meaningful information about model complexity for transformer models up to 6.9B parameters. This is an encouraging signal for applications of SLT to large neural networks, but significant methodological challenges remain for LLC estimation and similar techniques. The sensitivity of LLC estimates to hyperparameters and the likely gap between estimated and true values represent the primary limitations of our current framework.
Looking forward, the field is advancing along two complementary paths that will eventually converge. From one direction, practical compression techniques continue to improve, pushing closer to theoretical limits. From the other direction, the developing science of LLC estimation offers a path toward more accurate estimation of these limits. As these approaches converge, we will gain precise understanding of both the fundamental limits of compression and how closely practical techniques are approaching them.
Appendix
This appendix provides detailed information about our methodology, experimental setup, and additional results that supplement the main paper. We organize the appendix into the following sections:
-
Appendix A: Additional related work and discussion.
-
Appendix B: Descriptions of the Pythia model architectures used in our experiments.
-
Appendix C: Additional experimental results:
-
Additional quantization results with loss minimization, including more models, more values and critical vs. steps (Section C.1)
-
Results on tensor factorization (Section C.2)
-
Quantization results without loss minimization, including loss increase plotted against , three different values and critical vs. LLC and training step (Section C.3)
-
Addition of Gaussian noise, loss increase plotted against strength of Gaussian noise, three different values and critical amount of gaussian noise vs. LLCs and steps (Section C.4)
-
Structured pruning, our retraining protocol and loss increase as a function of pruning amount (Section C.5)
-
-
Appendix D: Details on our LLC estimation procedure, including hyperparameter settings and computational resources required.
-
Appendix E: Supplementary mathematical derivations and proofs that extend the theoretical framework presented in Section 3.
-
Appendix F: Further details on the derivation of the singular MDL principle and its implications.
Appendix A Additional related work and discussion
Model compression in industry.
Model compression techniques are widely employed by industry leaders to scale inference of large language models (LLMs), as they significantly reduce model size, memory footprint, and inference latency. The connection to compression is due to the fact that memory and latency are primarily determined by the total number of bits in the parameters [Dettmers and Zettlemoyer, 2023]. Quantization is used by Meta to compress their LLaMA models, approximately halving their memory footprint and doubling inference throughput [AI, 2024]. Knowledge distillation has similarly been utilized by Anthropic to create smaller models like Claude 3 Haiku, which achieves near-identical performance to its larger predecessor, Claude 3.5 Sonnet, while substantially lowering deployment costs [Anthropic, 2024]. Pruning, particularly structured sparsity supported by NVIDIA GPUs, also shows empirical evidence of approximately doubling inference throughput by eliminating around half of the model’s weights [Mishra et al., 2021].
Scaling laws and compression.
The training of large-scale neural networks obeys empirical scaling laws [Kaplan et al., 2020, Hoffmann et al., 2022], which relate test loss to parameter count and tokens seen during training. Since model compression techniques work by reducing the effective parameter count, at the cost of an increase in loss, it is natural to wonder how to incorporate compression into the neural scaling laws. Most of the work to date has been on empirical scaling laws for quantization [Dettmers and Zettlemoyer, 2023, Ouyang et al., 2024, Xu et al., 2024, Frantar et al., 2025, Kumar et al., 2025], although there is some work on distillation [Busbridge et al., 2025].
Data-dependent compression bounds.
Lossy compression is always defined relative to a specific loss function on a particular dataset, which implicitly chooses which capabilities to prioritize and preserve. A corollary is that any attempts to derive compression bounds based on the pretraining objective may be unnecessarily conservative: a large fraction of a model’s capacity goes to memorization [Carlini et al., 2023], much of which may be irrelevant to particular capabilities. Understanding compression requires data-dependent bounds such as those considered here.
Security implications.
Our work establishes a theoretical connection between SLT and neural network compressibility, providing a principled framework that could inform future security research. By demonstrating that the local learning coefficient (LLC) correlates with practical compression limits, we lay groundwork for developing rigorous bounds on how much specific capabilities can be compressed. Future work building on these theoretical foundations could provide robust bounds on the information required to transmit specific capabilities, helping calibrate security measures and inform discussions about model weight protection.
Economic drivers & theoretical limits of compression
Halving the memory cost of a model can potentially double its operational value: under fixed GPU budgets, compressing parameters (e.g., pruning or quantization) directly raises the volume of token processing and thus revenue [Wang et al., 2024b, Zhu et al., 2024]. This incentive is driving substantial private research and development so that the state of the art in model compression likely surpasses known public benchmarks [Cheng et al., 2017, Han et al., 2015a]. In this situation, it is particularly valuable to understand the theoretical limit to model compression since this limit is a key factor in the economic feedback loops driving investment. This is particularly true as AI systems start to do autonomous research.
Appendix B Model details
We conduct experiments on models from the Pythia suite [Biderman et al., 2023], ranging from 14M to 6.9B parameters for most experiments. For Pythia, we include model checkpoints ranging from 2k to 90k, excluding later checkpoints because of apparent instability in the original training runs. Note that all Pythia models are trained on the same data in the same order from the Pile [Gao et al., 2020].
We begin with an already (losslessly) compressed version of the Pythia models, in which layer norm weights are folded into subsequent linear layers, following the default settings in our TransformerLens-based implementation [Nanda and Bloom, 2022].
Appendix C Additional Results
In this appendix, we provide quantization and factorization results for additional model sizes, as well as quantization results for quantization without loss minimization, addition of Gaussian noise to the parameters, and pruning.
C.1 Quantization with Loss Minimization
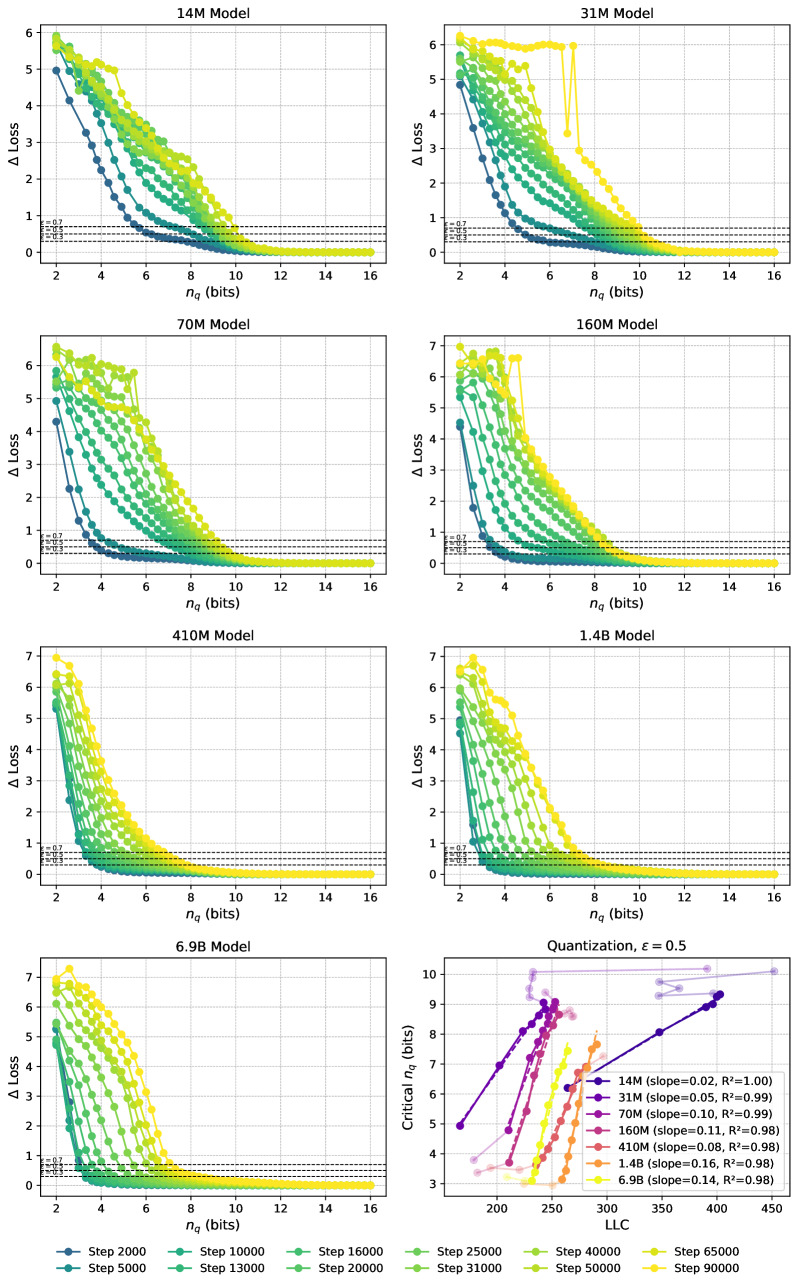
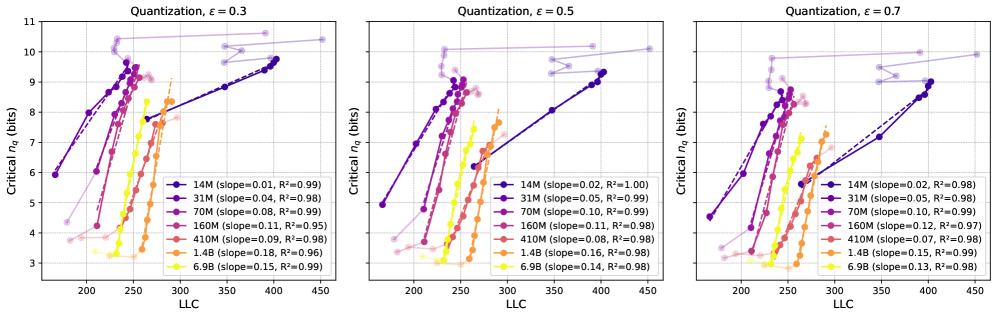
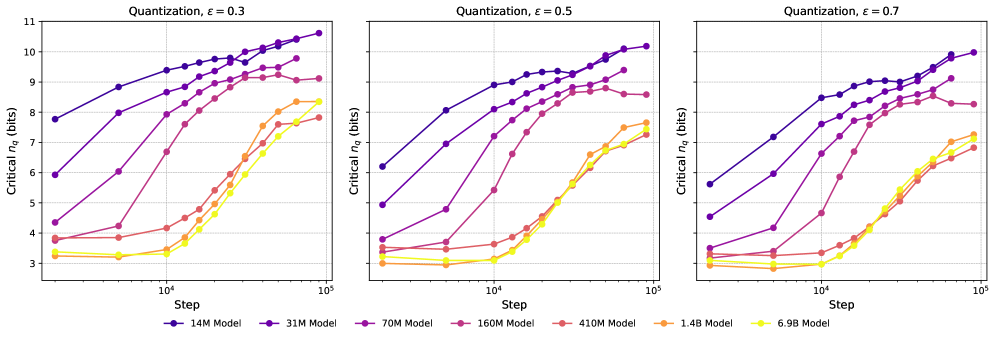
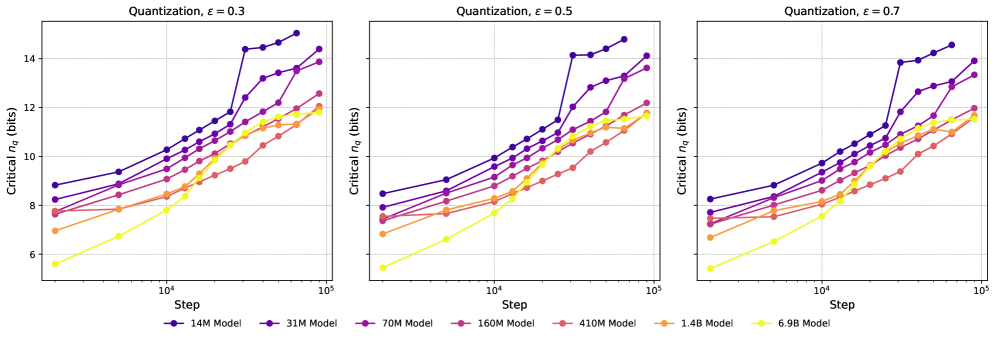
We show results on additional models for the quantization method used in Section 5 in Figure 4, showing linear fits with for checkpoint ranges across a wide range of Pythia models. The comparison of LLC vs. critical for 3 different choices of is shown in Figure 5. As stated in the main body, these curves are qualitatively -insensitive. For comparison, we show the critical as a function of training step in Figure 6, and observe that the curves are qualitatively similar to the ones with the LLC on the x-axis. This is expected, as the LLC is an increasing function of training steps, as shown in Figure 21.
C.2 Tensor Factorization
Tensor factorization techniques decompose weight matrices in neural networks into products of smaller matrices, reducing the total number of parameters. We perform the factorization by performing Singlar Value Decomposition on weight matrices , and truncating a fixed fraction of the singular values, leaving the weight matrix approximated as
| (12) |
where is a diagonal matrix with diagonal entries. We do this by following the heuristics outlined in Moar et al. [2024]: We target a selection of layers and factorize all matrices in those layers. We avoid the very last and very first layers, and also avoid factorizing consecutive layers. In the experiments shown in Section 5, we avoid factorizing the embedding and unembedding matrices. If has dimensions by , then before factorization the matrix has parameters, whereas after factorization it has parameters. The reported compression fraction is the ratio between the total number of parameters in the model after and before factorization, i.e.
| (13) |
For the smaller Pythia models where the embedding and unembedding matrix dominate the parameter count of the model, the compression fraction is always close to 1. To measure the compressibility of the models under factorization, we find the critical compression fraction, i.e., the value of the compression fraction which causes a loss increase of .
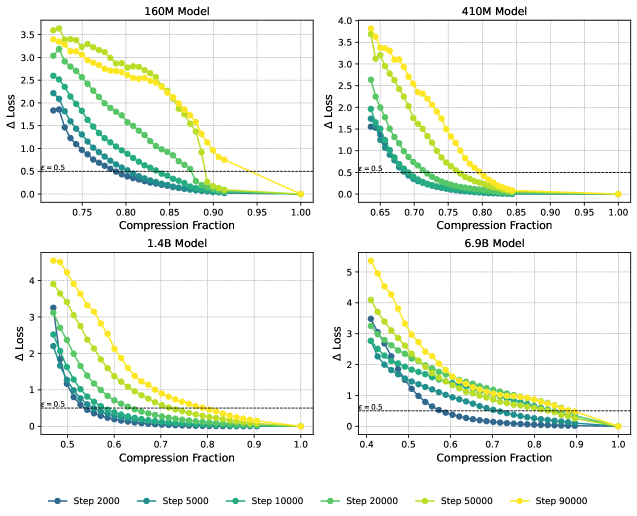
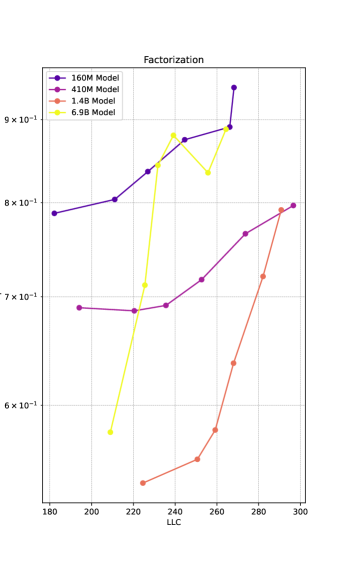
In Figure 7, left side, we show the compression-induced loss increase as a function of compression fraction. To a lesser extent than with quantization, we observe the loss curves featuring a knee at a loss increase of around . For consistency, we stick to the same value of for factorization as for quantization. In the Section C.2, we show a selection of other values, showing that they lead to qualitatively similar results. In the panel to the right, we observe the critical compression fraction largely increasing with increasing LLC, with the exception of Pythia-6.9B where it seems to flat-line at later steps. This might be related to Pythia-6.9B late in training featuring a knee at considerably higher values, between 1 and 1.5.
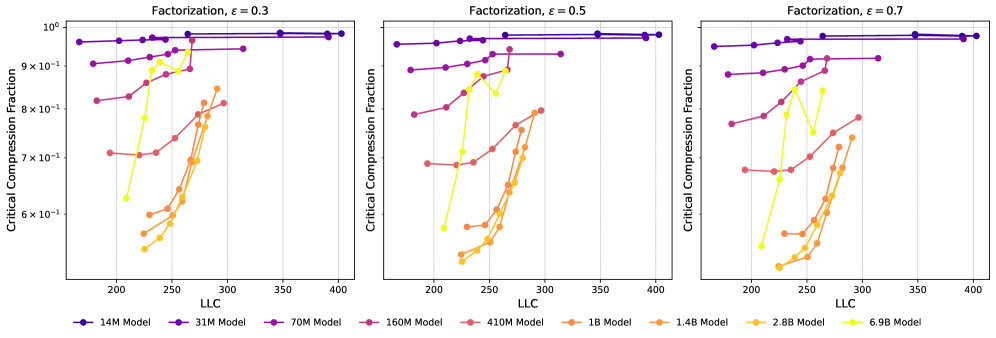
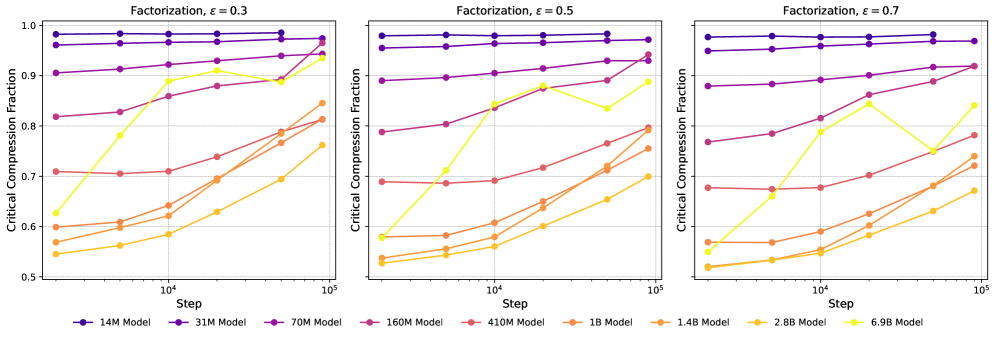
In Figure 8 we show the loss increase as a function of compression fraction for all Pythia models up to and including 6.9B. We compare different choices of in Figure 9 and Figure 10, and observe the curves being largely -insensitive. We observe that the critical compression fraction is mostly an increasing function of both LLC and training step.
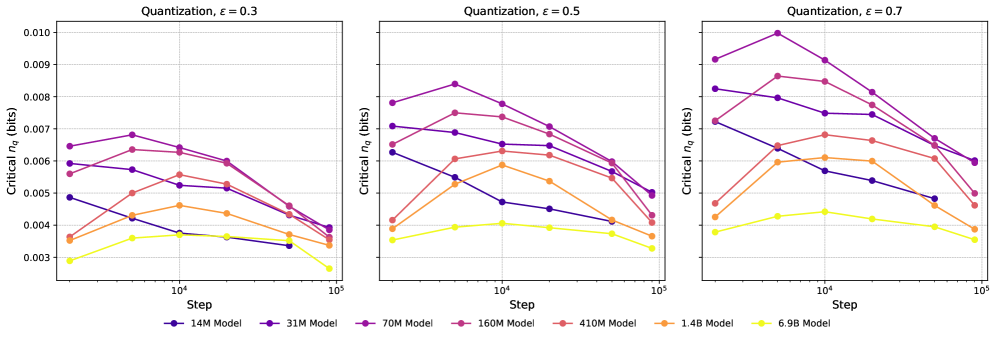
C.3 Quantization without Loss Minimization
Here we quantize by setting to the largest parameter value, rather than selecting it by minimizing the post-quantization loss. We show the loss increase for this form of quantization in Figure 11. A comparison of 3 critical for different choices of is shown in Figure 12 and Figure 13, and we observe that the curves are largely -insensitive. We observe that this form of quantization also features critical increasing as a function of LLC, but find worse linear fits for critical vs. LLC than we find for quantization with loss minimization in Section C.1. This might be because quantization with loss minimization better probes the loss landscape near the .
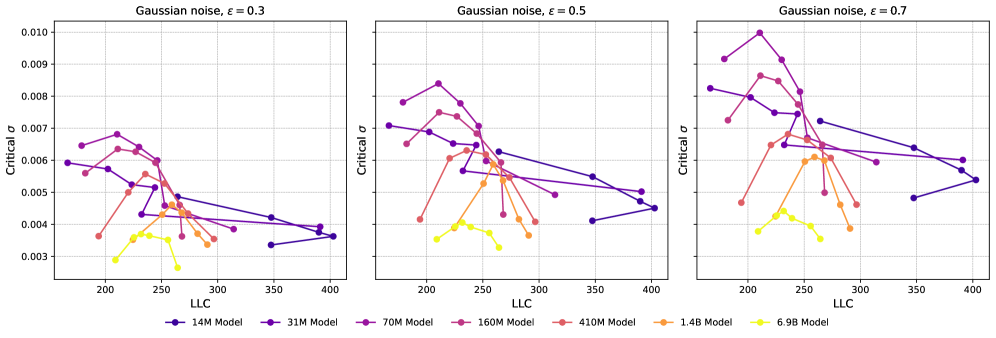
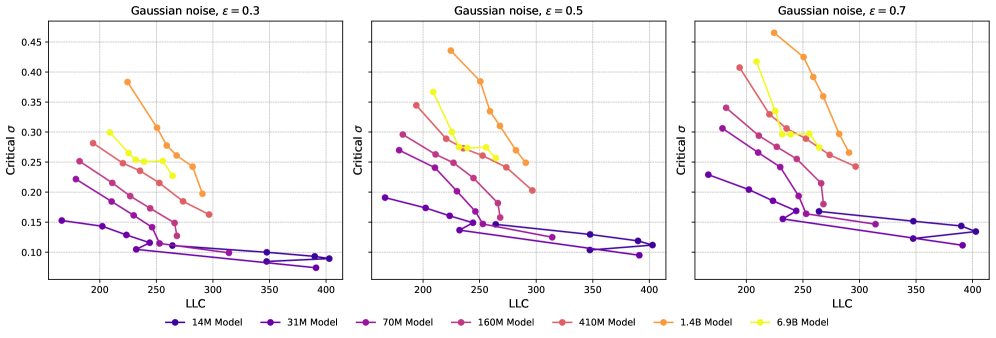
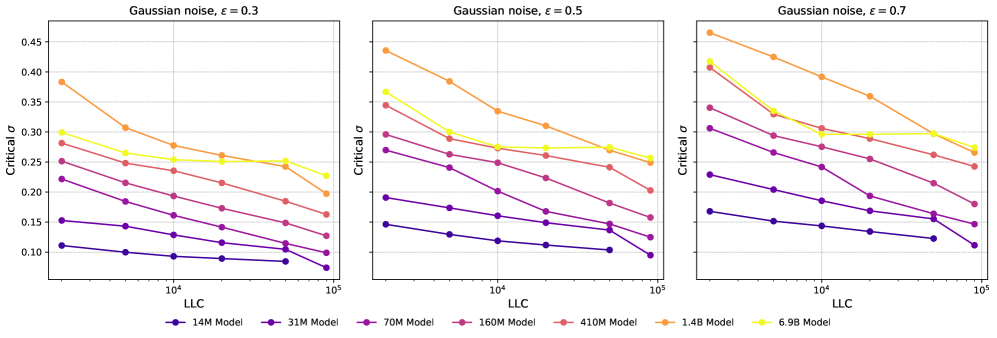
C.4 Adding Gaussian Noise
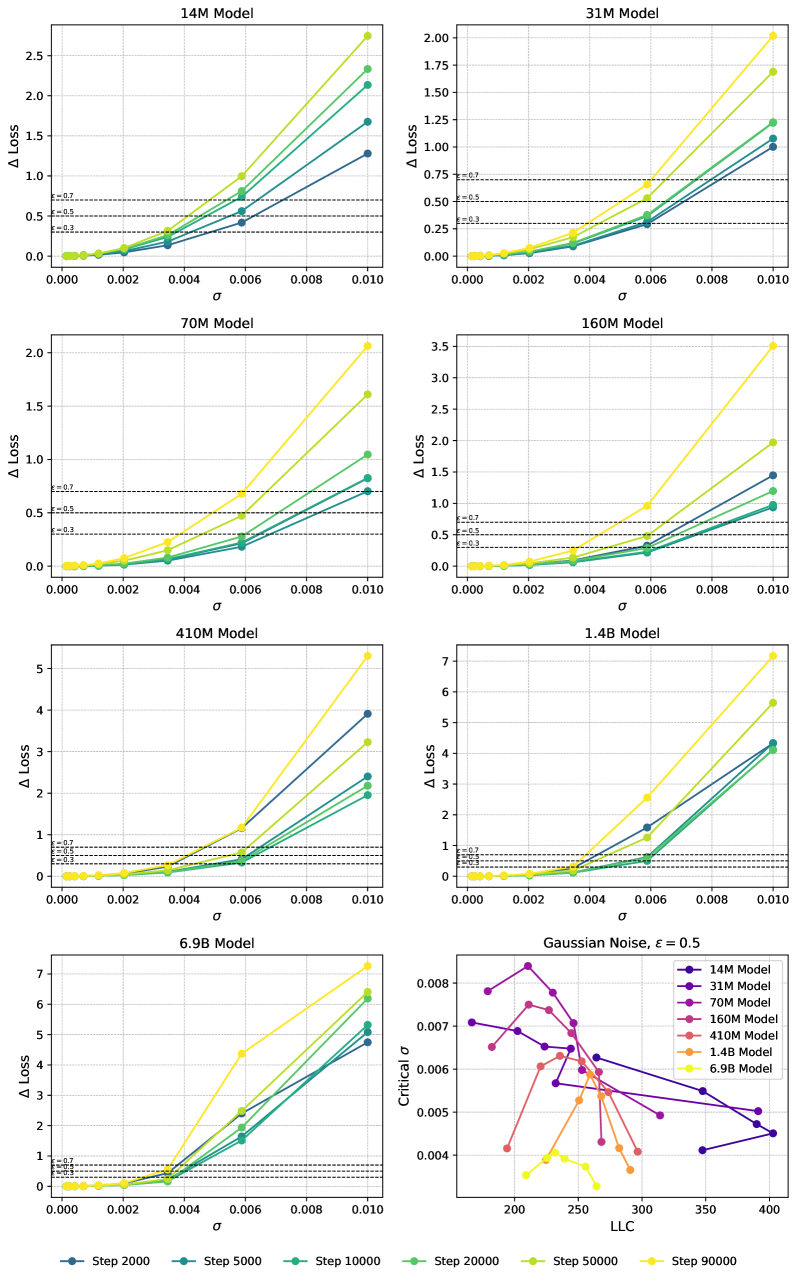
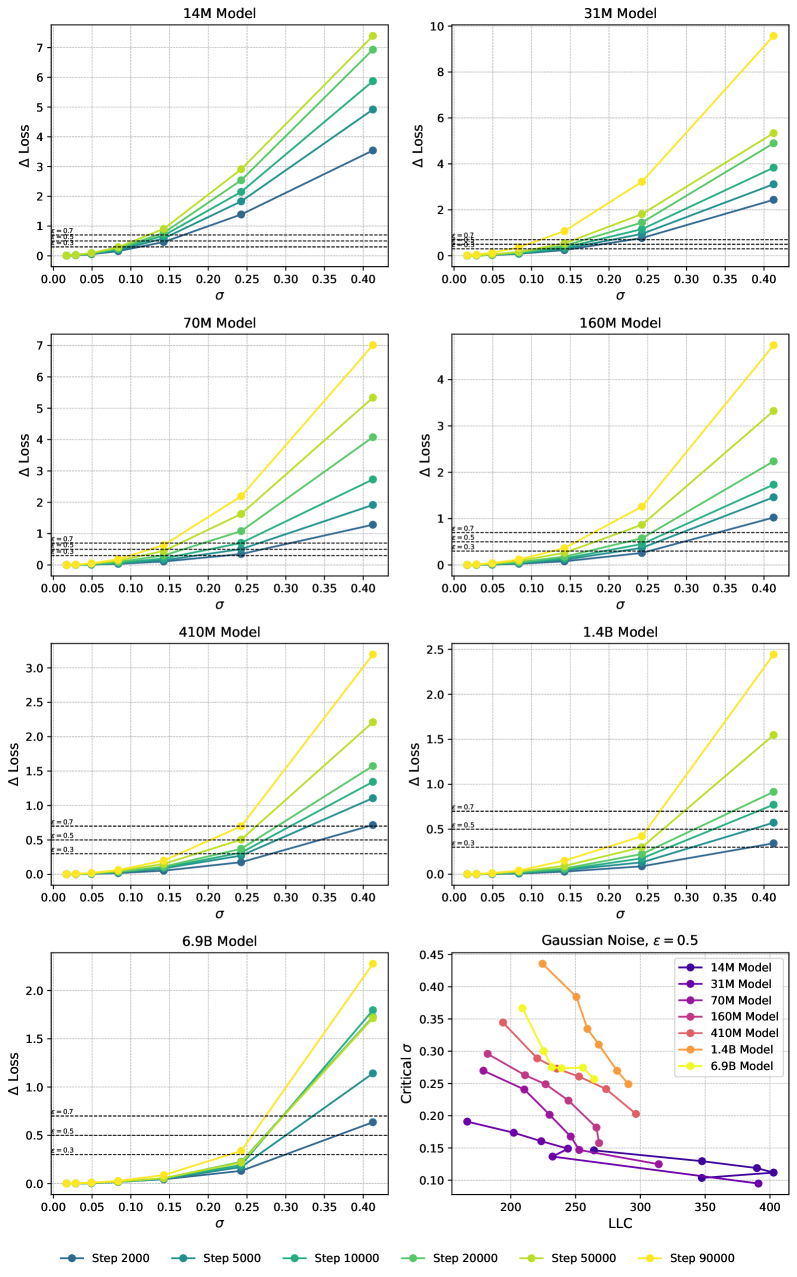
We have two ways of adding Gaussian noise. The first we call absolute Gaussian noise, and involves updating the parameters of the model according to
| (14) |
We use relative Gaussian noise to refer to adding noise proportional to the parameter,
| (15) |
In Figure 14 and Figure 15, we show the loss increase as a function of for absolute and relative noise, respectively, with the lower right corner showing the critical for as a function of LLC. We observe that for addition of relative noise, critical largely decreases with increasing LLC, as expected. For absolute Gaussian noise, the picture is more complicated, and is probably impacted by the change in magnitude of the model parameters over the course of training. In Figure 16 and Figure 17, we show critical as a function of LLC for different values of loss tolerance . We observe that the qualitative shape of the curves are -insensitive. In Figure 18 and Figure 19 we plot the critical as a function of training step. We observe a similar relation between the training steps and critical as between the LLC and critical . Again, we observe that the curves are qualitatively -insensitive.
C.5 Pruning
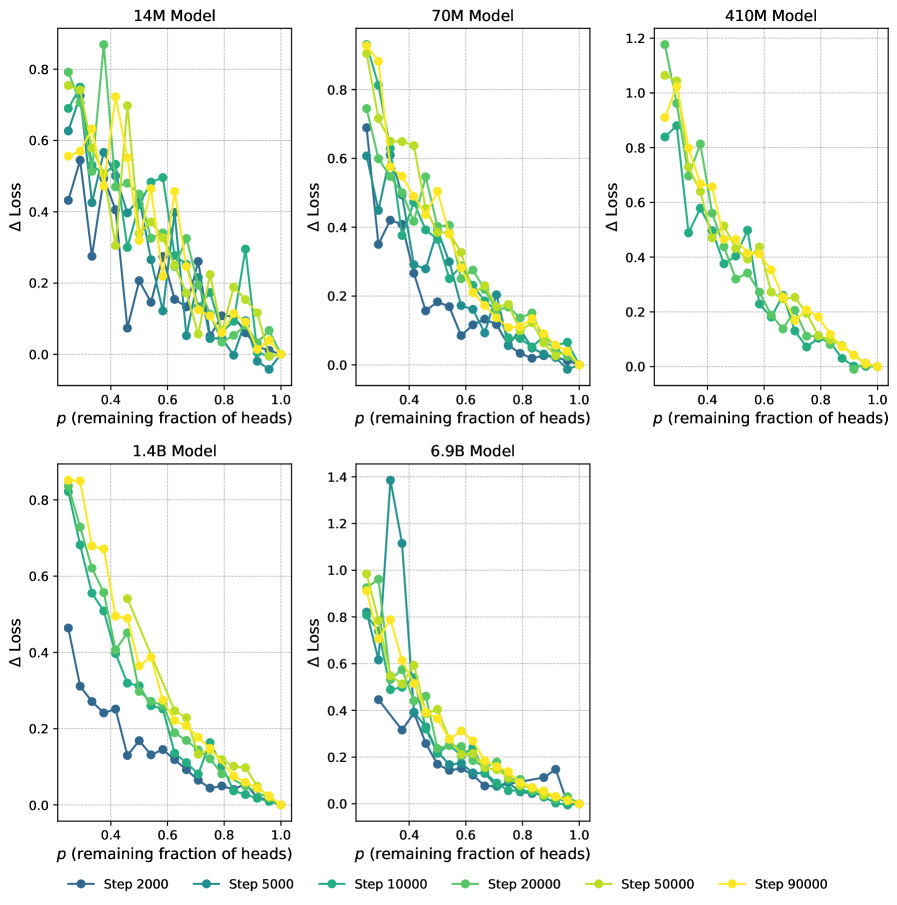
Pruning techniques can be broadly categorized into structured and unstructured approaches. Unstructured pruning involves removing individual weights throughout the network without any regular pattern, potentially achieving higher compression rates but requiring specialized hardware or software to realize computational speedups. Structured pruning, on the other hand, removes entire structured components (e.g., neurons, filters, or attention heads), resulting in models that are inherently smaller and faster on standard hardware.
For our experiments, we focus on structured pruning of attention heads in transformer models. When pruning a model, we first specify a desired fraction of heads to keep . From this, we compute the number of heads to prune as:
| (16) |
where is the total number of attention heads in the model. We then select heads at random and set their weight matrices to zero (excluding biases). Following pruning, we implement a retraining phase with the following specifications [Han et al., 2015b]:
-
The gradients of the weight matrices in pruned heads are fixed to zero to maintain the pruning structure.
-
We use a learning rate 1/10th of the one used during initial training.
-
We retrain for 1000 steps, taking the post-retraining loss to be the minimal training loss during retraining.
In Figure 20, we show how the loss changes during pruning of a selection of Pythia models. Since several of these curves are very rugged, we refrain from plotting LLC vs critical values of .
Appendix D LLC Estimation Details
Sanity checks for LLCs.
It was shown in Lau et al. [2024] that variations in training hyperparameters (learning rate, batch size and momentum) affect LLC estimates in the way one would expect for a measure of model complexity. Outside of the limited cases where theoretical values of the LLC for large neural networks are available (principally deep linear networks, Aoyagi 2024), such experiments serve as a crucial “sanity check” on LLC estimates. The experimental results on the effect of compression on the LLC in this paper serve as a complementary set of sanity checks for LLC estimation in models up to 6.9B parameters.
D.1 Implementation of the LLC Estimator
Computational Resources.
LLC estimation for our largest models required substantial computational resources. For reference, a single LLC estimation for the Pythia-6.9B model required approximately 3.5 hours on an H200 GPU with 141GB memory.
Hyperparameters.
We estimate the LLC of the Pythia models on the Pile [Gao et al., 2020], using the full context of 2048 tokens, with localization , inverse temperature and 4 SGLD chains with 200 steps for models smaller than 1B parameters and 100 steps for models equal to or larger than 1B parameters. We use a batch size of 32, and use 8 batches to calculate . The SGLD learning rate varies with model size, and we use for Pythia-14M, for Pythia-31M and Pythia-70M, for Pythia-160M and Pythia-410M, for Pythia-1B and Pythia-1.4B, for Pythia-2.8B and for Pythia-6.9B.
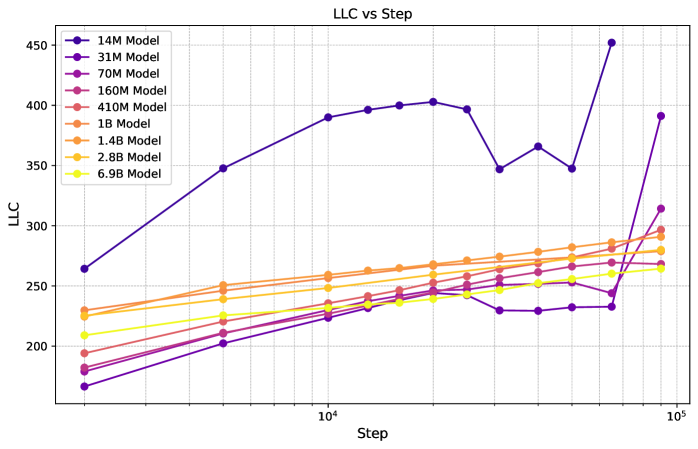
Estimated LLCs for Pythia models.
In Figure 21 we show the LLC as function of training step for the Pythia models. We see that with the exception of Pythia-14M through 70M, the LLC rises smoothly as function training step.
D.2 (Challenges in) Estimating the LLC
The main obstacle to using the LLC in practice as a tool for evaluating compression techniques is that we usually do not have direct access to the true LLC, , but must instead estimate its value, , and these estimates may be systematically biased. Currently, the only scalable approach to estimating LLCs for large neural networks is via gradient-based approximate posterior sampling methods like SGLD [Lau et al., 2024]. The resulting estimates have been found in recent years to be useful in practice for understanding the development of neural networks [Hoogland et al., 2025, Wang et al., 2024a, Carroll et al., 2025, Urdshals and Urdshals, 2025].
However, while there is a deep mathematical theory behind the definition of the LLC, there are several serious problems with the current state of empirical practice:
-
There are gaps in the theory of SGLD. Although there is a theoretical literature [Welling and Teh, 2011, Chen et al., 2015, Teh et al., 2016], which provides conditions (for example, decaying step size and long chains) under which gradient-based posterior sampling methods converge weakly to the true posterior for some classes of statistical models, some of the technical conditions in these theorems do not hold for all neural networks. Thus, the theoretical status of SGLD-based estimation is unclear.
-
We do not fully understand the role of hyperparameters like inverse temperature. In practice, we know that varying the inverse temperature used for estimation does affect the estimates. In principle, any inverse temperature is valid (since the effect due to the tempering of the posterior should be canceled by the occurring as a prefactor), but in practice, SGLD-based estimation appears sensitive to this factor. Since the only principled setting is [Watanabe, 2013], which is too small for stable estimation in our settings, we know that the LLC estimates can, at best, be meaningful up to whatever effect this variation has on estimates. Chen and Murfet [2025] prove that the temperature acts as a resolution dial on the loss landscape, so that we sample from an effectively truncated posterior, but this effect is not yet fully understood; this explains why we have focused on applications of LLC estimation to a single model with the same hyperparameters across training, under the hypothesis that this effect does not confound comparisons of LLC values at different training timesteps.
-
Unrealistic values for large networks. SGLD-based LLC estimation can produce accurate estimates for deep linear networks [Lau et al., 2024]. Keeping in mind the previous point, the hyperparameters we select for the Pythia suite lead to LLC estimates that are on the order of hundreds, for models with parameter counts ranging from millions to billions.
Appendix E Theoretical results for Singular MDL
E.1 Assumptions
In this section, we list the sufficient conditions for the results discussed in this work to hold. Recall that we have an outcome space , data distribution and model .
Finite outcome space.
We assume that the outcome space is finite so that the data distribution, and distributions in a model are members of the finite dimensional simplex . This is a severe restriction stated for expository ease. There isn’t any fundamental limitation from relaxing this criterion to the continuous case.
Conditions for SLT.
As we rely heavily on the core result of SLT, we require similar sufficient conditions as stated by Watanabe [2009, Definition 6.1 and 6.3] and the relaxation of the realisability assumptions stated in Watanabe [2018, Chapter 3.1].
Importantly, we require that
-
The parameter space is a compact subset of with non-empty interior.
-
The data distribution satisfies relatively finite variance condition set out in Watanabe [2018, Definition 7].
-
The loss function can be extended to a -valued complex analytic function.
Uniformly bounded away from boundary.
This is a technical condition that allow us to treat KL-divergence as almost a metric on . We require that the model we considered to be a subset of the restricted simplex for some defined as follow.
Definition 1.
Let be a finite set and be a number . We define as the set of distributions in the interior of the simplex that is uniformly bounded away from the simplex boundary by . That is
E.2 Lemmas
Lemma 1.
Let be fixed. There exist constants such that for any ,
where denotes the -norm.
Proof.
Let . Note that . Now,
since . Let . Taylor expanding at up to order 2 with Lagrange remainder give us for some . Therefore,
Now, from the calculation above, we have and therefore
where we have used the fact that and . Finally, and , we get
The above result allows us to show that the KL-divergence on this restricted space of distribution satisfies a form of triangle inequality.
Lemma 2.
With the same assumption as Lemma (1), there exist such that for any
Since this holds over all , the ordering of the arguments for each KL-divergence above does not matter.
Proof.
Applying the Lemma (1), once in each direction of inequality, together with the fact that give
which is the desired result with . We note that whenever has more than 1 element.
Lemma 3.
Let and and . Suppose and are both finite, then there exist constants , independent of , such that
Proof.
Let . Using Taylor’s theorem with Lagrange remainder, there exist such that
Furthermore, observe that
Combining the above, we have that for some
Given the condition on , we have
Taking and , we get
Note that this implies as .
E.3 Theorems
A rather straight forward application of Bernstein inequality together with the variance bound above give the following result.
Theorem 3.
Let and be a data sequence of size drawn i.i.d. from . Define the random variable . Suppose and for some constant , then for sufficiently large ,
for some constant independent of . In other words, .
Proof.
We apply Bernstein inequality on the centered random variable with norm bounded by to get
Unpacking definition, we get
Using the result from Lemma (3), we get know that for sufficiently large there exist such that
Choose and we get the required result. We can apply the same argument to to get the lower tail bound.
Theorem 4.
Let be a model consisting of distributions with uniform lower bound . There exist constant such that for any and any satisfying the following holds
Proof.
Now, set . Let , be given such that . For any given such that , we get
This proves the first inclusion.
Similarly, whenever
This proves the second inclusion.
Theorem 5.
Let be a model consisting of distributions with uniform lower bound and be a data distribution in (realizable). Given any and , we suppose there exist sets such that for every there exist with where . Given any i.i.d. samples of size , let be the maximum likelihood hypothesis in and define be the closest grid point to , i.e. . Then the random variable is satisfies
for some sequences of random variables and that are both of order . Furthermore, is bounded with high probability.
Proof.
Using the inequality from Lemma twice (2), we get
for some constant . This jointly implies
| (17) |
for some constants . Now, Watanabe [2009, Main theorem 6.4] shows that where is a non-zero random variable with non-zero expectation. So, . Combined with the fact that , we get the desired result.
Finally, to show that is bounded with high probability, we observe that Watanabe [2009, Main theorem 6.4] also shows that the random variable , being a maximum of a Gaussian process with continuous sample paths on a compact parameter space , is almost surely bounded. Hence, for sufficiently large , we have which is bounded with high probability.
E.4 Justification for
Equation (17) shows that even if , then will still converge to a non-zero random variable (with non-zero expectation) since will then be the sole dominant term instead, which is still . For the purpose of minimizing the redundancy in Eq (1), we would not want that decays faster than since that would increase the cost of the model description term without saving message length.
On the other hand, if , i.e. for some that diverges to infinity, then can be dominated by the discretisation cost, leaving . Yet, assuming for some , then, relative to , this only provide saving for the model description term of order and is thus not optimal.
Appendix F Further theoretical discussion on Singular MDL
F.1 Phases and phase transition in code lengths
In regular models, regardless of the underlying data distribution being modeled and regardless of the minimum of the population loss under consideration, the complexity, as measured by LLC, is always , where is the model parameter count. The difference in complexity only shows up in lower-order terms in the form of local curvature. In contrast, the geometry of the loss landscape can change drastically for singular models with even small changes in the data distribution, and each minimum of the population loss can have a different LLC value.
Importantly for compression, there can be sudden reversals in the balance of loss-complexity trade-off when the data size increases. This is a consequence of the fact that for different minima of , the associated total code length has leading-order terms . For low , minima with lower complexity but higher loss can be preferred since that can give rise to a lower code length. But as increases, the term will dominate, and it is increasingly favored to pay a high upfront cost for specifying a high complexity set of weights, which is then amortized by having a lower marginal cost for using those weights to send more symbols. This is the usual model selection procedure statisticians perform to balance model complexity and fit, but for singular models, this process can happen implicitly and internally to the model.
These phenomena are collectively known as phase transitions in statistical learning. Watanabe [2009] first described these phase transitions, which have since been observed and measured in various settings. For example, Chen et al. [2023] track phase transitions in a toy model of neural network superposition [Elhage et al., 2022]. They find that loss decreases as the LLC increases in a Bayesian-learning setting (performing Bayesian updates on increasing numbers of data points) and also in an SGD-training setting (taking an increasing number of gradient steps for a fixed dataset size). While there are mature theoretical explanations for the Bayesian setting, the observations in the SGD setting remain empirical results [Urdshals and Urdshals, 2025, Hoogland et al., 2025, Wang et al., 2024a]. Nonetheless, those results provide an important context for the present work where the trade-off between loss and model complexity – thus compressibility – is also a primary concern.
F.2 I.I.D. Assumption
Needing to assume i.i.d. is a severe theoretical weakness for applications of the theory in linguistic domains. Neither the data-generating distribution nor the auto-regressive training objective treats sequences of tokens as i.i.d. sequences. Results in MDL and SLT can be generalized to non-i.i.d. settings like Markovian processes, but usually some form of ergodicity assumptions are needed. Those are likely violated by natural language-generating processes.
This is less of a theoretical issue when we are mainly discussing pretraining loss as we can treat each chunk of text the size of the maximum context window, , as a single data point and treat them as i.i.d. data. This means our outcome space is . While the underlying data-generating process for internet text certainly does not have this structure, it is reasonable to use this model for some pretraining data-loading process where the chunks are fed in as independent data points.
The critical caveats are thus:
-
Our framework has yet to explain any capabilities gains via post-training methods like various forms of fine-tuning and reinforcement learning.
-
This framework is also not strong enough to discuss the base model capability (as opposed to their ability for compressing internet text) as most capabilities measures require modeling a joint distribution of the form , which are likely non-stationary distributions.
It is plausible that leading order indicators like loss and LLC are unaffected by these considerations, but that is an open theoretical and empirical question at this stage. There is evidence that the emergence of certain algorithmic capabilities correlates sharply with changes in the LLC Wang et al. [2024a], Urdshals and Urdshals [2025]
Cite as
@article{urdshals2025compressibility,
author = {Einar Urdshals and Edmund Lau and Jesse Hoogland and Stan van Wingerden and Daniel Murfet},
title = {Compressibility Measures Complexity: Minimum Description Length Meets Singular Learning Theory},
year = {2025},
url = {https://arxiv.org/abs/2510.12077},
eprint = {2510.12077},
archivePrefix = {arXiv},
abstract = {We study neural network compressibility by using singular learning theory to extend the minimum description length (MDL) principle to singular models like neural networks. Through extensive experiments on the Pythia suite with quantization, factorization, and other compression techniques, we find that complexity estimates based on the local learning coefficient (LLC) are closely, and in some cases, linearly correlated with compressibility. Our results provide a path toward rigorously evaluating the limits of model compression.}
}