Automated Conversion Notice
Warning: This paper was automatically converted from LaTeX. While we strive for accuracy, some formatting or mathematical expressions may not render perfectly. Please refer to the original ArXiv version for the authoritative document.
1 Introduction
A striking phenomenon in modern deep learning is the sudden shift in a model’s internal computational structure and associated changes in input/output behavior (e.g., Wei et al., 2022; Olsson et al., 2022; McGrath et al., 2022). As large models become more deeply integrated into real-world applications, understanding this phenomenon is a priority for the science of deep learning.
A key feature of the loss landscape of neural networks is degeneracy—parameters for which some local perturbations do not affect the loss. Motivated by the perspectives of singular learning theory (SLT; Watanabe, 2009) and nonlinear dynamics (Waddington, 1957; Thom, 1972), where degeneracy plays a fundamental role in governing development, we believe that studying degeneracy in the local geometry of the loss landscape is key to understanding the development of structure and behavior in modern deep learning.
| Stage | LM1 |
LM2 |
LM3 |
LM4 |
LM5 |
|---|---|---|---|---|---|
| End | 900 | 6.5k | 8.5k | 17k | 50k |
| Stage | LR1 |
LR2 |
LR3 |
LR4 |
LR5 |
|---|---|---|---|---|---|
| End | 1k | 40k | 126k | 320k | 500k |
In this paper, we contribute an empirical investigation of the link between degeneracy and development for transformers in two learning settings. We track loss landscape degeneracy along with model structure and behavior throughout training, using the following methodology.
-
Transformer training (Section˜3): We train two transformers, a language model (LM) with around 3M parameters trained on a subset of the Pile (Gao et al., 2020; Xie et al., 2023), and an in-context linear regression model (LR) with around 50k parameters trained on synthetic regression data following Garg et al. (2022).
Crucially, we discover that most of the developmental stages identified by changes in loss landscape degeneracy coincide with significant, interpretable shifts in the internal computational structure and input/output behavior of the transformers, showing that the stage division is meaningful. Our investigations are motivated by the hypothesis of a fundamental link between degeneracy and development in deep learning. This hypothesis is theoretically grounded in SLT but so far not empirically validated except in toy models (Chen et al., 2023). We view the above discoveries as preliminary evidence for this hypothesis in larger models, and an indication of the potential of degeneracy as a lens for understanding modern neural network development. Section˜8 discusses this and other implications of our investigation.
2 Related work
Degeneracy and development in singular learning theory
Our hypothesis that degeneracy and development are fundamentally linked is motivated by singular learning theory (SLT; Watanabe, 2009), a framework for studying singular statistical models a class that includes neural networks, Hagiwara et al., 1993; Watanabe, 2007; Wei et al., 2023. SLT proves that in singular models, Bayesian inference follows the singular learning process, in which degeneracy in the likelihood governs stagewise development in the posterior as the number of samples increases Watanabe, 2009, §7.6; Lau et al., 2025; Chen et al., 2023. While there are many differences between Bayesian inference and modern neural network training, an analogy to the singular learning process informs our methodology for stage division.
Degeneracy and development in nonlinear dynamics
Further motivation for our hypothesis comes from viewing neural network training as a stochastic dynamical system, in which the population loss is a governing potential encoding the data distribution. It is well-understood in nonlinear dynamics that degeneracy in the local geometry of a potential can give rise to stagewise development of system structure (Waddington, 1957; Thom, 1972, cf. Franceschelli, 2010). This connection has been observed in biological systems at significant scale and in the presence of stochasticity (Freedman et al., 2023). We emphasize changes in degeneracy over a stage whereas in bifurcation theory the focus is more on the degeneracy at stage boundaries (Rand et al., 2021; MacArthur, 2022; Sáez et al., 2022).
Stagewise development in deep learning
The idea that neural networks development occurs in stages goes back decades (Raijmakers et al., 1996) and has received renewed attention in modern deep learning (e.g., Wei et al., 2022; Olsson et al., 2022; McGrath et al., 2022; Odonnat et al., 2024; Chen et al., 2024; Edelman et al., 2024). In the case of deep linear networks, we understand theoretically that models learn progressively higher-rank approximations of their data distribution (see, e.g., Baldi & Hornik, 1989; Rogers & McClelland, 2004; Saxe et al., 2019) throughout training. Our findings suggest that studying degeneracy could help generalize this understanding to modern architectures that exhibit more complex internal computational structure, such as transformers.
Studying loss landscape geometry
Given the central role played by the loss landscape in deep learning, it is unsurprising that there have been many attempts to study its geometry.
One approach is to visualize low-dimensional slices of the loss landscape (Erhan et al., 2010; Goodfellow et al., 2014; Lipton, 2016; Li et al., 2018; Tikeng Notsawo et al., 2024). Unfortunately, a random slice is with high probability a quadratic form associated to nonzero eigenvalues of the Hessian and is thus biased against geometric features that we know are important, such as degeneracy (Wei et al., 2023). Moreover, Antognini & Sohl-Dickstein (2018) have emphasized the difficulty of probing the loss landscape of neural networks with dimensionality reduction tools.
Other standard methods of quantifying the geometry of the loss landscape, such as via the Hessian, are insensitive to important aspects of degeneracy. For example, the Hessian trace or maximum eigenvalues quantify the curvature of a critical point but ignore degenerate dimensions, and the Hessian rank counts the number of degenerate dimensions but fails to distinguish between dimensions by the order of their degeneracy (e.g., quartic vs. zero). In contrast, the LLC is a principled quantitative measure of loss landscape degeneracy. Section˜B.5 includes experiments showing that Hessian statistics do not reveal the clear stage boundaries revealed by the LLC in our in-context linear regression setting.
3 Training transformers in two settings
We study transformers trained in two learning settings, namely language modeling and in-context linear regression. These settings have been the subject of recent work on the emergence of in-context learning (ICL), a compelling example of a sudden shift in a model’s internal computational structure in modern deep learning (Olsson et al., 2022).
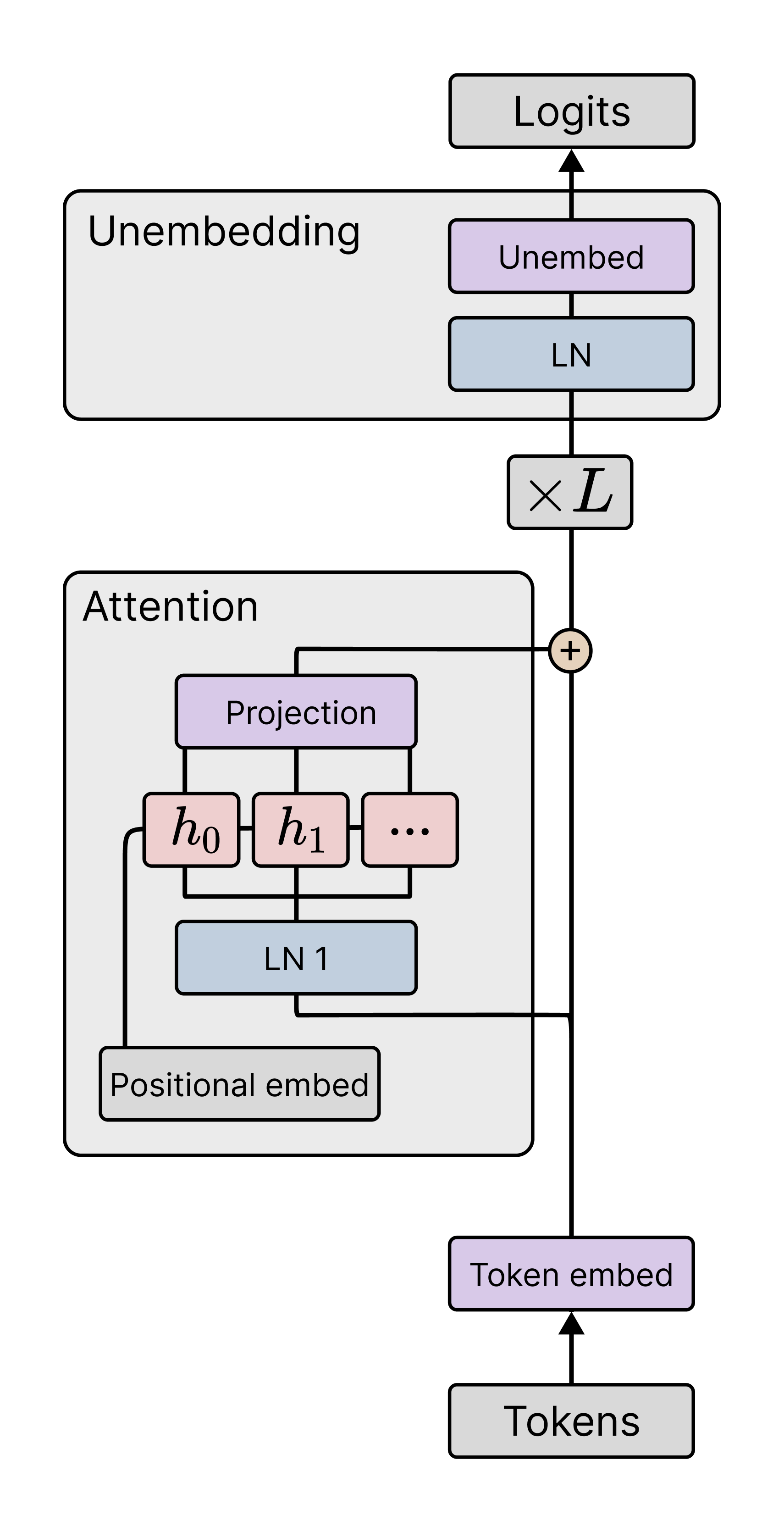
In this section, we describe both settings and introduce their loss functions and data distributions. Common to both settings is a transformer model denoted with parameters , which takes as input a sequence of tokens, also called a context. We describe specific architecture details and training hyperparameters in Sections˜F.1 and F.2.
Language modeling
Elhage et al. (2021) and Olsson et al. (2022) observed that two-layer attention-only transformers (transformers without MLP layers) form interesting internal computational structures supporting ICL, including induction heads. In order to compare with their behavioral and structural analysis we adopt the same architecture. In Appendix˜E we also study one-layer attention-only transformers. We note that, while we don’t study language models with MLP layers (following prior work), we do use MLP layers for in-context linear regression.
We consider the standard task of next-token prediction for token sequences taken from a subset of the Pile (Gao et al., 2020; Xie et al., 2023). We denote the input context by where is the context length. We denote by the prefix context of context . Our data is a collection of length- contexts, . Thus denotes a prefix of the th context, .
Given the context , the transformer model outputs a vector of logits such that is a probability distribution over all tokens (we denote by the probability of token ). The per-token empirical loss for language modeling is then the average cross-entropy between this distribution and the true next token at each index ,
| (1) |
The empirical loss is then , with the test loss defined analogously on a held-out set of examples. The corresponding population loss is defined by taking the expectation with respect to the true distribution of contexts (see also Section˜A.6).
In-context linear regression
Following Garg et al. (2022), a number of recent works have explored ICL in the setting of learning simple function classes, such as linear functions. This setting is of interest because we understand theoretically optimal (in-context) linear regression, and because simple transformers are capable of good ICL performance in practice (see, e.g., Garg et al., 2022; Raventós et al., 2023).
We consider a standard synthetic in-context linear regression problem. A task is a vector , and an example is a pair . We sample a context by sampling one task and then sampling i.i.d. inputs and outputs . This results in the context with label . We denote by the prefix context of context , its label is . Section˜F.2.2 describes how we encode the and as tokens. Our data is a set of contexts sampled i.i.d. as described above.
Running a context through the transformer yields a prediction , leading to the per-token empirical loss for in-context linear regression for ,
| (2) |
The associated empirical loss is . The corresponding test loss and population loss are defined analogously as in the language modeling setting.

4 Quantifying degeneracy with the local learning coefficient
We track the evolution of degeneracy in the local geometry of the loss landscape throughout training by estimating the local learning coefficient (LLC; Watanabe, 2009; Lau et al., 2025) at model checkpoints. In this section, we review the LLC and the estimation procedure of Lau et al. (2025).
The local learning coefficient (LLC)
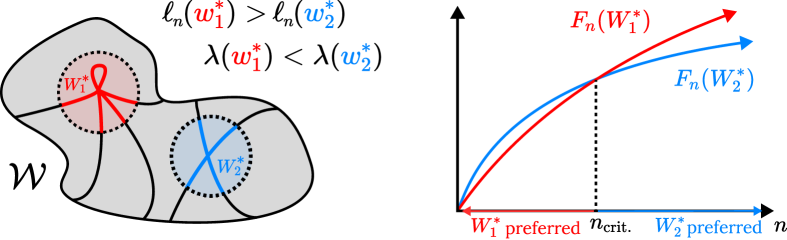
Given a local minimum of a population loss (a negative log likelihood), the LLC of , denoted , is a positive rational number that measures the amount of degeneracy in near (Watanabe, 2009; Lau et al., 2025), i.e., how many ways can be varied near such that remains equal to . Formally, the LLC is defined as the volume-scaling rate near . This is illustrated in Figure˜2, further described in Section˜A.1, and treated in full detail in Lau et al. (2025). Informally, the LLC is a measure of minimum “flatness.” It improves over conventional (second-order) Hessian-based measures of flatness because the LLC is sensitive to more significant, higher-order contributions to volume-scaling.
Estimating the LLC
Lau et al. (2025) introduced an estimator for the LLC based on stochastic-gradient Langevin dynamics (SGLD; Welling & Teh, 2011), which we use in our experiments. Let be a local minimum of the population loss . The LLC estimate is
| (3) |
where denotes the expectation with respect to the localized Gibbs posterior
with inverse temperature (controlling the contribution of the empirical loss landscape) and localization strength (controlling proximity to ). The basic idea behind this estimator is the following: the more degenerate the loss landscape, the easier it is for a sampler exploring the Gibbs posterior to find points of low loss, and, in turn, the lower . Section˜A.3 discusses technical SGLD details, Section˜A.4 documents the hyperparameters used in our experiments, and Section˜A.5 outlines our hyperparameter tuning procedure.
Assumptions of LLC estimation
Strictly speaking, the LLC is defined only for loss functions arising as a negative log likelihood, whereas our loss function includes terms from overlapping context prefixes. It is possible to define a negative log likelihood-based loss for transformer training—we show empirically in Section˜A.6 that this does not have a significant effect on LLC estimates, and so we proceed with overlapping contexts for efficiency.
Moreover, the LLC is defined only for local minima of such loss functions, whereas we note equation ˜3 is defined for arbitrary and we apply the estimator throughout training. This approach has precedent in prior work on LLC estimation: Lau et al. (2025) showed that when applied to trained parameters, the estimator accurately recovers the learning coefficient associated with a nearby minimum, and Chen et al. (2023) found that the estimator produces reliable results for parameters throughout training. In our case, we obtain stable estimates throughout training given sufficiently strong localization . See Section˜A.7 for more details.
5 Degeneracy-based stage division
We use critical points (that is, plateaus, where the first derivative vanishes) in the LLC curve to define stage boundaries that divide training into developmental stages. This approach is motivated by the singular learning process in Bayesian inference, which we review below.
Bayesian local free energy
Let be a neighborhood of a local minimum of the population loss (a negative log likelihood). Given samples we can define the local free energy of the neighborhood (Lau et al., 2025),
where is a prior positive on the neighborhood . The lower the local free energy of a neighborhood , the higher the Bayesian posterior mass of . In fact, by a log-sum-exp approximation, the Bayesian posterior is approximately concentrated on the neighborhood with the lowest local free energy (cf., Chen et al., 2023).
The singular learning process
Watanabe’s free energy formula gives, under certain technical conditions, an asymptotic expansion in of the local free energy Watanabe, 2018, Theorem 11; Lau et al., 2025:
| (4) |
Here, is the empirical loss, is the LLC, and the lower-order terms include a constant contribution from the prior mass of .
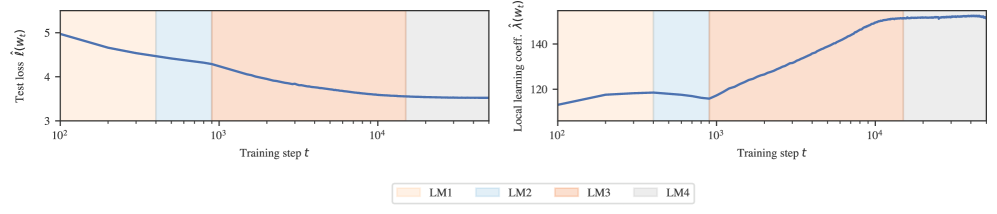
The first two terms in equation ˜4 create a tradeoff between accuracy () and degeneracy (). Moreover, as increases, the linear term becomes increasingly important relative to the logarithmic term, changing the nature of the tradeoff. At certain critical the neighborhood with the lowest local free energy may rapidly change to a neighborhood with decreased loss and increased LLC, as illustrated in Figure˜3.
A sequence of such posterior transitions between increasingly degenerate neighborhoods is a prime example of the singular learning process (Watanabe, 2009, §7.6). We note that this is not the only possible dynamic—lower-order terms may also play a role in the evolving competition.
LLC plateaus separate developmental stages
While the general connection between the singular learning process in Bayesian inference and stagewise development in deep learning remains to be understood, Chen et al. (2023) showed that, in small autoencoders, both Bayesian inference and stochastic gradient descent undergo rapid transitions between encoding schemes, and these transitions are reflected as sudden changes in the estimated LLC.
This perspective suggests that changes in the loss landscape degeneracy, as measured by the LLC, reflect qualitative changes in the model. In larger models, we expect that these qualitative changes may be more gradual, while still being delineated by brief moments in which the posterior is stably concentrated around a given local minimum. This motivates our approach of identifying plateaus in the estimated LLC curve—brief pauses before and after a given increase or decrease in degeneracy—as stage boundaries which divide training into approximate developmental stages. The resolution of these stage boundaries depends on the density of checkpoints used for LLC estimation and the precision of those estimates.
Results
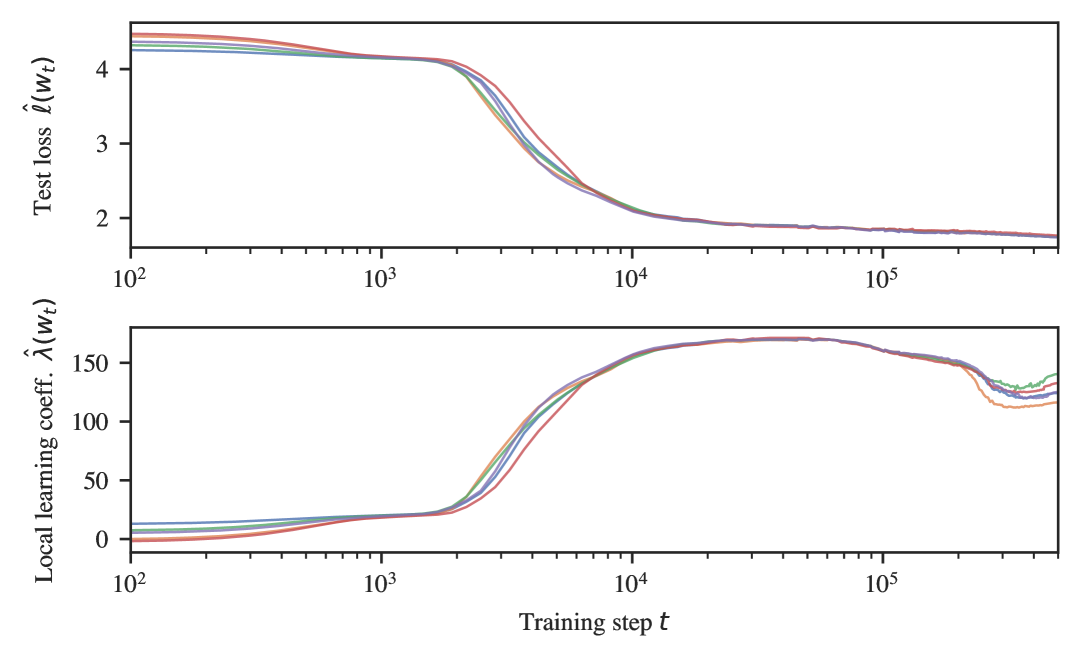
In our experiments, we identify plateaus in the estimated LLC curve by first lightly smoothing the LLC curve with a Gaussian process to facilitate stable numerical differentiation with respect to log training time. We identify plateaus as approximate zeros of this derivative, namely local minima of the absolute derivative that fall below a small threshold (see Section˜B.1). Figures˜1, B.2 and B.3 show the results. Sections˜B.4 and B.4 shows that similar stage divisions arise for independent training runs.
6 Results for language modeling
Plateaus in LLC estimates (Figures˜1(a) and 1(a)) reveal five developmental stages for our language model. In order to validate that this stage division is meaningful, we search for concomitant changes in the model’s input/output behavior and its internal computational structure. In this section, we report a range of setting-specific metrics that reveal the following significant, interpretable changes coinciding with each stage: in LM1 the model learns to predict according to bigram statistics; in LM2 the model learns to predict frequent -grams and use the positional embedding; in LM3 and LM4 the model respectively forms “previous-token heads” and “induction heads” as part of the same induction circuit studied by Olsson et al. (2022). Note that we did not discover significant changes in LM5, and we do not claim that these are the only interesting developmental changes occurring throughout training. There may be other interesting developmental changes that are not captured by our metrics, or are not significant enough to not show up in the LLC curve.
6.1 Stage LM1 (0–900 steps)
Learning bigram statistics
Figure˜4(a) shows that the bigram score—the average cross entropy between model logits and empirical bigram frequencies (see Section˜C.1.1)—is minimized around the LM1–LM2 boundary, with a value only 0.3 nats above the irreducible entropy of the empirical bigram distribution. This suggests that during LM1 the model learns to predict using bigram statistics (the optimal next-token prediction given only the current token).
6.2 Stage LM2 (900–6.5k steps)
Using positional information
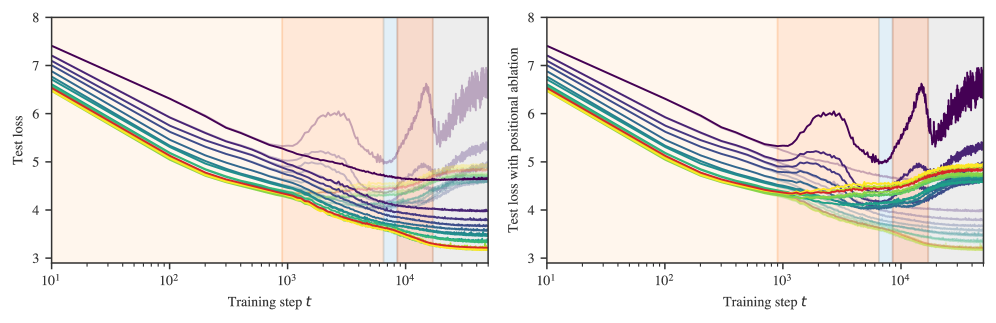
During LM2 the positional embedding becomes structurally important. Figure˜4(b) shows that here the test loss for the model with the positional embedding zero-ablated diverges from the test loss of the unablated model (see Section˜C.2.1). Specifically, we mean setting learned positional embeddings to zero during evaluation. Conditional on our architecture this establishes whether the model effectively uses positional information. A similar method could be used in a model without learned positional embeddings. There is also an uptick in previous-token attention among some first-layer attention heads shown in green in Figure˜4(d).
Learning common -grams
We define an -gram score as the ratio of final-position token loss on (1) a baseline set of samples from a validation set truncated to tokens, and (2) a fixed set of common -grams (see Section˜C.1.2). To compute the “common n-grams” score after extracting the top 1000 n-grams, we compute the loss on contexts like
[<bos_token>, <token_1>, <token_2>, ..., <token_n>]
using the loss on <token_n> and normalize against the average loss on the
-th token of similar-length contexts drawn from the pretraining distribution, then divide
the -th token loss of truncated pretraining contexts by the
-gram loss to get the -gram score.
Figure˜4(c) shows a large improvement in -gram score for during LM2. This suggests that during LM2 the model memorizes and learns to predict common -grams for (note this requires using the positional encoding and may also involve previous-token heads).
Foundations of induction circuit
In this stage, the heads that eventually become previous-token and induction heads in future stages begin to compose (that is, read from and write to a shared residual stream subspace; see Figures˜C.4 and C.2.2). This suggests that the foundations for the induction circuit are laid in advance of any measurable change in model outputs or attention patterns.
6.3 Stages LM3 & LM4 (6.5k–8.5k & 8.5k–17k steps)
Formation of induction circuit as studied in Olsson et al., 2022
Figure˜4(d) shows the previous-token matching score (Section˜C.2.3) rises over LM3 and LM4 for the two first-layer heads that eventually participate in the induction circuit (as distinguished by their composition scores, Section˜C.2.2). Figure˜4(e) shows that during LM4 there is an increase in the prefix-matching score (Section˜C.2.4) for the two second-layer induction heads that complete the induction circuit. Figure˜4(f) shows a corresponding drop in the ICL score (Section˜C.1.3) as the model begins to perform in-context learning.
The LLC decreases during LM3, suggesting an increase in degeneracy (a decrease in model complexity). This may be related to interaction between heads. It would be interesting to study this stage further via mechanistic interpretability.
7 Results for in-context linear regression
Plateaus in the LLC estimates (Figures˜1(b) and 1(b)) reveal five developmental stages for our in-context linear regression model. We validate that this stage division is meaningful by identifying significant, concomitant changes in the model’s structure and behavior: in LR1 the model learns to predict without looking at the context; in LR2 the model acquires a robust in-context learning ability; and in LR3 and LR4 the model becomes more fragile to out-of-distribution inputs. We did not discover significant changes in LR5, nor do we claim this is an exhaustive list of developments.
7.1 Stage LR1 (0–1k steps)
Learning to predict without context
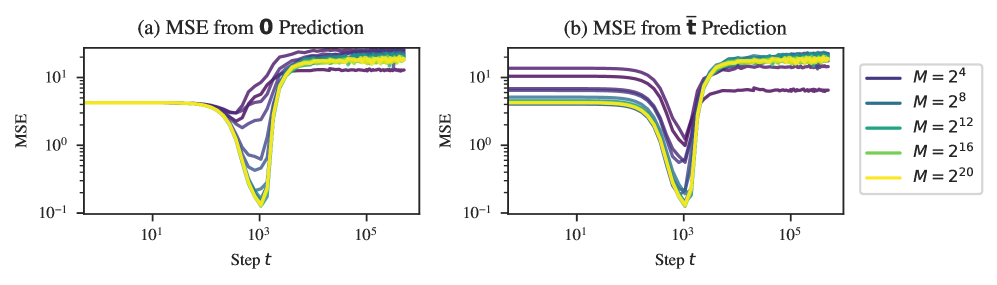
Figure˜5(a) shows that the mean square prediction for all tokens decreases during LR1, reaching a minimum of (smaller than the target noise ) slightly after the end of LR1. Similar to how the language model learned bigram statistics in LM1, this suggests the model first learns the optimal context-independent prediction where is the mean of the task distribution (zero in this case).
7.2 Stage LR2 (1k–40k steps)
Acquiring in-context learning
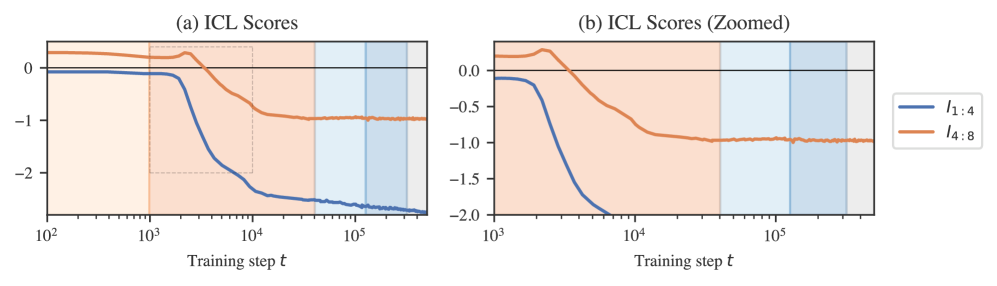
Figure˜5(b) shows that during LR2 there is a drop in ICL score (Section˜D.1.2), indicating that the model acquires in-context learning.
Embedding and attention collapse
Section˜D.2 documents additional changes. Near the end of LR2, token and positional embeddings begin to “collapse,” effectively losing singular values and aligning with the same activation subspace (Sections˜D.2.1 and D.2.2). At the same time, several attention heads form concentrated, input-independent attention patterns (Section˜D.2.3).
7.3 Stages LR3 & LR4 (40k–126k & 126k–320k steps)
Reduced robustness to input magnitude
Layer-normalization collapse
Figure˜5(c) shows the individual weights in the final layer normalization module. A large fraction of these weights go to zero in LR3 and LR4. This occurs in tandem with a similar collapse in the weights of the unembedding transforms (Section˜D.2.4). This results in the model learning to read its prediction from a handful of privileged dimensions of the residual stream. Since this means that the network outputs become insensitive to changes in many of the parameters, we conjecture that this explains part of the striking decrease in estimated LLC over these stages (Section˜D.2.4).
This collapse is most pronounced and affects the largest proportion of weights in the unembedding module, but in LR4 it spreads to earlier layer normalization modules, particularly the layer normalization module before the first attention block (Section˜D.2.5).
8 Discussion
In this paper, we have examined the development of transformer models in two distinct learning settings. We quantified the changes in loss landscape degeneracy throughout transformer training by estimating the local learning coefficient (LLC). Motivated by the singular learning process in Bayesian inference, we divided these training runs into developmental stages at critical points of the LLC curve. We found that these developmental stages roughly coincided with significant changes in the internal computational structure and the input/output behavior of each model. In this section, we discuss several implications of these findings.
Towards a degeneracy-based understanding of deep learning
That significant structural and behavioral changes show up in the LLC curve is evidence that the development of our transformers is closely linked to loss landscape degeneracy. This finding underscores the potential of loss landscape degeneracy as a crucial lens through which to study the development of deep learning models.
While we studied two distinct learning settings (including language modeling with a nontrivial transformer architecture), it remains necessary to verify the connection between degeneracy and development across a more diverse range of emergent model structures and behaviors. Moreover, future work should investigate this connection in more depth, seeking to establish a causal connection between changes in degeneracy and changes in structure and behavior.
Towards developmental interpretability
We showed that degeneracy can reveal meaningful changes in transformers. We emphasize that our analysis is not exhaustive—we expect only certain “macroscopic” changes, such as the emergence of in-context learning, will have a significant enough effect on loss landscape degeneracy to appear separated by plateaus in the LLC curve. Recent work has extended these ideas by measuring the LLC with respect to network sub-modules and with different data distributions, providing a more refined picture of model development (Wang et al., 2025). We expect this research direction will lead to insights into the development of more complex models.
Loss landscape degeneracy offers a setting-agnostic, “unsupervised” alternative to setting-specific progress measures such as those derived by Barak et al. (2022) or developed using mechanistic insights from similar models by Nanda et al. (2023). Both approaches can reveal developments invisible in the loss, but loss landscape degeneracy is able to detect changes without requiring a mechanistic understanding in advance. Of course, once a change is detected through its effect on degeneracy, it remains to interpret the change.
Cases studies in transformer development
We do not claim that the structural and behavioral developments we observed in each setting are universal phenomena. Transformers trained with different architectures, data distributions, algorithms, or hyperparameters may develop differently. Rather, our detailed analysis contributes two “case studies” to the growing empirical literature on the emergence of structure in transformers.
On this note, our observations extend those of Olsson et al. (2022) and Elhage et al. (2021). We show that before the induction circuit forms, our 2-layer language model learns simpler interpretable strategies (based on bigram statistics and common -grams). This shows that a single training run follows a progression akin to that found by Olsson et al. (2022) for fully-developed models of increasing depth (they showed that “0-layer” models learn bigram statistics and 1-layer models learn “skip-trigrams”). A similar progression was observed by Edelman et al. (2024) in a Markovian sequence modeling task.
Moreover, in both settings, we saw that before in-context learning emerges, the model learns to predict tokens using the optimal prediction given only the current token (bigram statistics for language modeling, zero for in-context linear regression with this distribution of tasks).
Development and model complexity
While we have described the LLC as a measure of loss landscape degeneracy, it can also be understood as a measure of model complexity (cf. Section˜A.2). It is natural for changes in a model’s internal structure to show up as a change in complexity. For example, Chen et al. (2024) showed that the emergence of syntactic attention structure coincides with a spike in two model complexity measures, namely the model’s Fisher information and the intrinsic dimension (Facco et al., 2017) of the model’s embeddings.
Notably, we observe stages in which the LLC decreases, corresponding to a simplification of the computational structure of the model. Such model simplification has empirical precedent, for instance with Chen et al. (2024) and the recent literature on grokking (Power et al., 2022; Nanda et al., 2023; Tikeng Notsawo et al., 2024). In our case, the mechanistic nature of the simplification is not fully clear, with the collapse of various weights and attention patterns arising as candidates in the in-context linear regression setting.
This phenomenon is currently not accounted for by theories of neural network development. In the theory of saddle-to-saddle dynamics, deep linear networks learn progressively more complex approximations of the data (Saxe et al., 2019). Likewise, the example transitions in the singular learning process outlined in Sections˜5 and 3 describe LLC increases. Though we note that decreasing the LLC while holding the loss constant would be another way to decrease the free energy according to equation ˜4, providing a full theoretical account of these stages is an open problem.
Appendix
Appendix˜A reviews the learning coefficient, providing some simple toy examples contrasting the learning coefficient with Hessian-based measures. This section also discusses SGLD-based LLC estimation including experiment hyperparameters (Section˜A.4), and offers a detailed example of the calibrations involved in applying LLC estimation to regression transformers to serve as a reference (Section˜A.5). Appendix˜B provides further detail on our procedure for LLC-based stage identification, including stages identified in additional training runs and a brief comparison with Hessian statistics. Appendices˜C and D examine the developmental stages of language models and in-context linear regression in more detail and explain the various metrics we use to track behavioral and structural development. Appendix˜E describes some additional experiments on a one-layer language model. Appendix˜F covers transformer training experimental details, such as model architectures, training procedures, and hyperparameters.
To facilitate reproduction of our analyses, we have made our codebase available. A repository containing additional figures and code can be accessed at the URL https://github.com/timaeus-research/icl.
[sections] [sections]l1
Appendix A The local learning coefficient (LLC)
A.1 Formal Definition of the LLC
In the setting of Section˜4, let be a closed ball around such that is a global minimum on , by which we mean a point with (equal) lowest loss. If there are multiple such global minima, the volume asymptotics are determined by the geometry of one that is most degenerate in the precise sense of SLT, formalised in Lau et al. (2025), roughly corresponding to having the lowest LLC. We call this minimum the maximally degenerate global minimum on . Consider the volume of the set of nearby low-loss parameters,
As , is asymptotically equivalent to
where is the LLC, is another geometric quantity called the local multiplicity, and is a constant.
A.2 Interpretations and examples of the LLC
In Section˜4, we introduced the LLC as a quantification of geometric degeneracy. In this section, we discuss an additional perspectives on the LLC as a count of the “effective” dimensionality of a parameter, and we give additional examples of the LLC. We refer the reader to Watanabe (2009) and Lau et al. (2025) for more discussion.
The LLC has some similarity to an effective parameter count. If the population loss looks like a quadratic form near then is half the number of parameters, which we can think of as contributions of from every independent quadratic direction. If there are only independent quadratic directions, and one coordinate such that small variations in near do not change the model relative to the truth (this dimension is “unused”) then .
The situation becomes more intricate when certain dimensions are degenerate but not completely unused, varying to quartic or higher order near the parameter (rather than being quadratic or flat). While every unused coordinate reduces the LLC by , changing the dependency on a coordinate from quadratic () to quartic () (increasing its degeneracy while still “using” it) reduces the contribution to the LLC from to .
As a source of intuition, we provide several examples of exact LLCs:
-
with . This function is nondegenerate, and . This is independent of . That is, the LLC does not measure curvature. For this reason, it is better to avoid an intuition that centers on “basin broadness” since this tends to suggest that lowering should affect the LLC.
-
in is degenerate, but its level sets are still submanifolds and . In this case the variable is unused, and so does not contribute to the LLC.
-
is degenerate and its level sets are, for our purposes, not submanifolds. The singular function germ is an object of algebraic geometry, and the appropriate mathematical object is not a manifold or a variety but a scheme. The quartic terms contribute to the LLC, so that . The higher the power of a variable, the greater the degeneracy and the lower the LLC.
Figure˜2 offers several additional examples, from left to right:
-
A quadratic potential , for which the LLC is maximal in two dimensions, .
-
A quartic potential , for which the LLC is .
-
An even more degenerate potential , for which . We note that Hessian-derived metrics cannot distinguish between this degeneracy and the preceding quartic degeneracy.
-
A qualitatively distinct potential from Lau et al. (2025) with the same LLC at the origin, .
While nondegenerate functions can be locally written as quadratic forms by the Morse Lemma (and are thus qualitatively similar to the approximation obtained from their Hessians), there is no simple equivalent for degenerate functions, such as the population losses of deep neural networks.
A.3 Estimating LLCs with SGLD
We follow Lau et al. (2025) in using SGLD to estimate the expectation value of the loss in the estimator of the LLC. For a given choice of weights we sample independent chains with steps per chain. Each chain is a sequence of weights . From these samples, we estimate the expectation of an observable by
| (5) |
with an optional burn-in period. Dropping the chain index , each sample in a chain is generated according to:
| (6) | ||||
| (7) |
where the step comes from an SGLD update
| (8) |
In each step we sample a mini-batch of size and the associated empirical loss, denoted , is used to compute the gradient in the SGLD update. We note that LLC estimator defined in ˜3 uses the expectation which in the current notation means we should take to be . For computational efficiency we follow Lau et al. (2025) in recycling the mini-batch losses computed during the SGLD process. That is, we take rather than .
Time and Space Complexity.
The computational cost per LLC estimate is proportional to a standard training step, denoted . We expect to require a constant number of samples (on the order of –) to yield robust estimates, independent of model size. Using logarithmically spaced checkpoints, the total computational complexity for generating an LLC curve over the entire training process scales as , where is the total number of training steps. The space complexity incurs a modest linear overhead compared to standard SGD, requiring storage for one additional copy of the weights to enable localization.
A.4 LLC estimation experiment details
A.4.1 LLC estimation details for language models
For language models, we use SGLD to sample 20 independent chains with 200 steps per chain and 1 sample per step. For the one-layer model, we used , and for the two-layer model we used . Estimating the LLC across all checkpoints took around 200 GPU hours for the two-layer model on a single A100 and around 125 GPU hours for the one-layer model. For additional runs of the two-layer model, we ran fewer chains, bringing the time down to about 2 TPU hours per training run.
We sampled a separate set of 1 million lines (lines 10m-11m) from the DSIR filtered Pile, denoted as . The first 100,000 lines from this SGLD set (lines 10m-10.1m) were used as a validation set. The sampling of batches for SGLD mirrored the approach taken during the primary training phase. Each SGLD estimation pass was seeded analogously, so, at different checkpoints, the SGLD chains encounter the same selection of batches and injected Gaussian noise.
| Hyperparameter | Category | Description/Notes | 1-Layer | 2-Layer |
|---|---|---|---|---|
| C | Sampler | # of chains | ||
| Sampler | # of SGLD steps / chain | |||
| SGLD | Step size | |||
| SGLD | Localization strength | 300 | 100 | |
| SGLD | Inverse temperature | 21.7 | ||
| SGLD | The size of each SGLD batch | 100 | ||
| Data | Dataset size for gradient minibatches | 13m | ||
A.4.2 LLC estimation details for in-context linear regression
For in-context linear regression models, we generate a fixed dataset of samples. Using SGLD, we sample independent chains with 5,000 steps per chain, of which the first 1,000 are discarded as a burn-in, after which we draw observations once per step, at a temperature , , and , over batches of size . LLC estimation takes up to 72 CPU-hours per training run.
| Hyperparameter | Category | Description/Notes | Default Values |
|---|---|---|---|
| C | Sampler | # of chains | |
| Sampler | # of SGLD steps / chain | ||
| SGLD | Step size | ||
| SGLD | Localization strength | ||
| SGLD | Inverse temperature | ||
| SGLD | The size of each SGLD batch | ||
| Data | Dataset size for gradient minibatches |
A.5 A guide to SGLD-based LLC estimation
This section walks through some of the hyperparameter choices and sweeps involved in calibrating LLC estimates. We provide it as a reference for others seeking to adjust LLC estimation to novel settings.
A.5.1 Varying the temperature
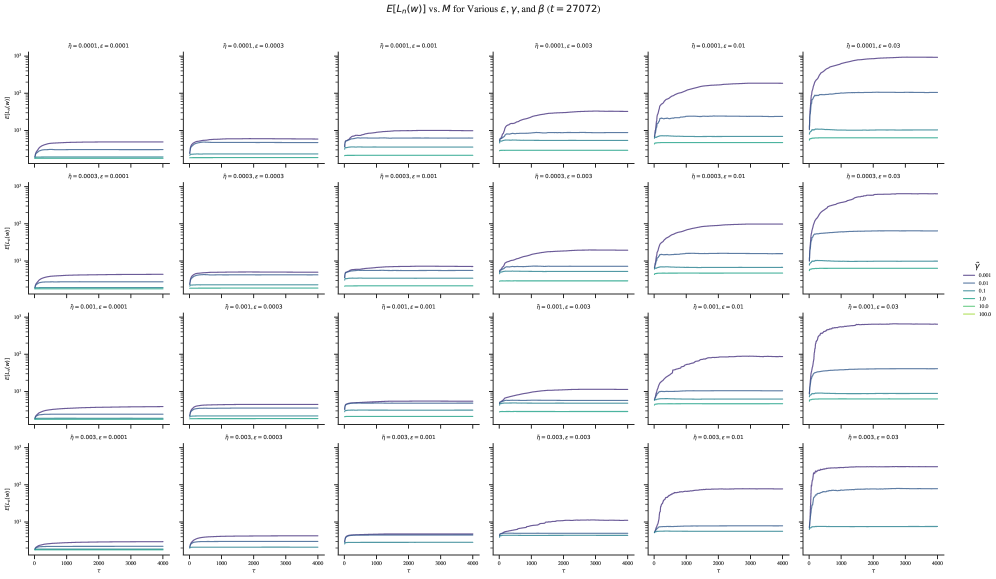
In Lau et al. (2025), the inverse temperature is set to a fixed “optimal” value , where is the number of training samples. In practice, we find that it can be advantageous to sample at a higher temperature.
Since always shows up in a product with (in ˜8 for the SGLD step and in ˜3 for the LLC), we can view the inverse temperature as a multiplier that adjusts the effective size of your dataset. In a Bayesian setting, would mean updating twice on each of the samples in your dataset.
The problem with the default choice of is that as we increase we have to decrease the SGLD step size to prevent the update from becoming ill-conditioned, and this eventually causes the gradient term to suppress the noise term. This, in turn, leads to requiring larger batches to suppress the gradient noise and requiring longer chains to sufficiently explore the local posterior (Section˜A.5.3).
Instead of , we perform LLC estimation at , where is the SGLD batch size.
A.5.2 Seeding the random noise
To smooth out the curves, we reset the random seed before LLC estimation run at each checkpoint. This means the sequence of injected Gaussian noise is the same for LLC estimation runs at different checkpoints. Additionally, if the batch size is held constant, the batch schedule will also be constant across different estimation runs. Figure˜A.3 shows that this does not affect the overall shape of the learning coefficient curves; it simply smooths it out.
A.5.3 Calibrating , , and
As a rule of thumb, should be large enough that the estimate converges within the steps of each chain but not too large that you run into issues with numerical stability and divergent estimates. Subject to this constraint, should be as small as possible to encourage exploration without enabling the chains to “escape” to nearby better optima, and should be as large as possible (but no greater than ).
To determine the optimal SGLD hyperparameters, we perform a grid sweep over a reparametrization of the SGLD steps in terms of :
where , .
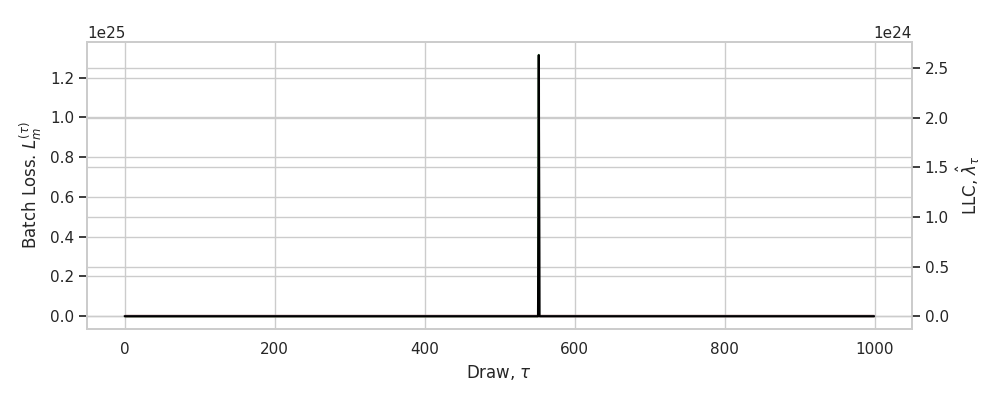
The results of this hyperparameter sweep are illustrated in Figure˜A.4 for final checkpoints. Separately (not pictured), we check the resulting hyperparameters for a subset of earlier checkpoints. This is needed since, for example, a well-behaved set of hyperparameters at the end of training may lead to failures like divergent estimates (Figure˜A.5) earlier in training when the geometry is more complex and thus the chains less stable.
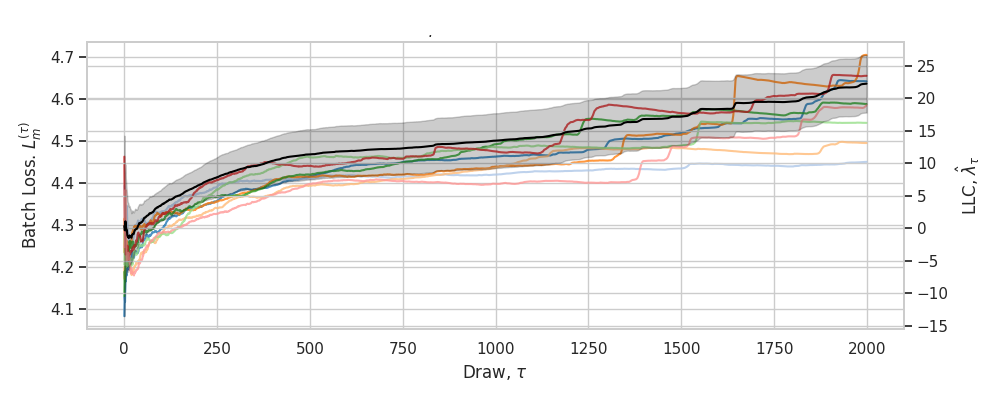
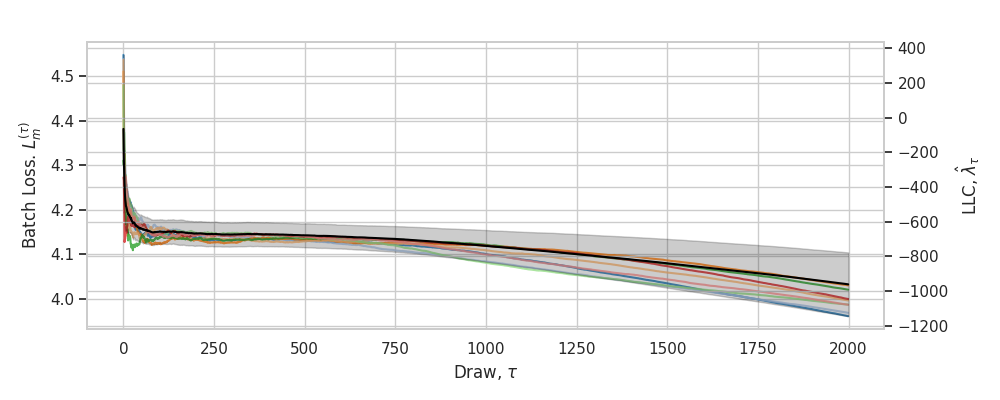
A.5.4 LLC traces
As a useful diagnostic when calibrating the LLC estimates, we propose an online variant for learning coefficient estimation. When overlaid on top of individual-chain LLC traces, this helps reveal common failure modes like divergent estimates, non-converged estimates, and escapes (Figure˜A.5). These traces display the running estimate of as a function of the number of steps taken in a chain (with the estimate averaged across independent chains).
Define , the LLC at after time-steps for a single SGLD chain as follows (Lau et al., 2025):
Moving terms around, we get,
| (9) | ||||
| (10) | ||||
| (11) | ||||
| (12) |
where
This can be easily extended to an online estimate over chains by averaging the update over multiple chains.
A.6 LLC estimates for a non-log-likelihood-based loss
In the main body, we apply the LLC to empirical loss functions that do not arise as the log likelihood of independent random variables, due to the repeated use of dependent sub-sequences. Here we explain that it is possible to define a proper negative log likelihood over independent observations for the in-context linear regression setting: similar observations can be made in the language modeling setting.
Let be a probability distribution over the context length . Ideally, the transformer would be trained to make predictions given a context of length where is sampled from . With the given distribution over contexts this leads to a negative log likelihood of the form
| (13) |
where is the probability of sampling from and
| (14) |
using the notation of Section˜3 so is a context of length . It is straightforward to check that this negative log likelihood agrees with the population loss associated to the empirical loss defined in Section˜3. However the empirical quantities and defined for a set of samples of size are not the same.
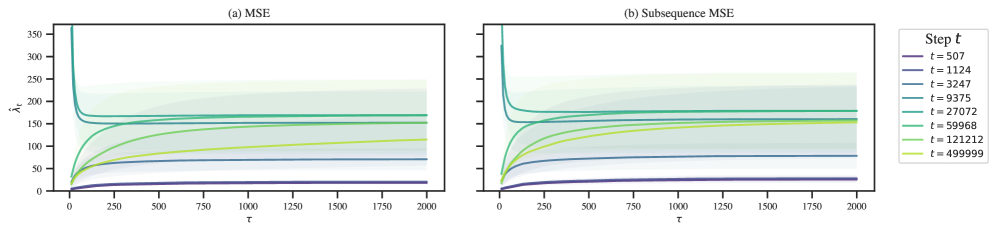
Since we use the empirical loss in our calculation of the estimated LLC, whereas the foundational theory of SLT is written in terms of the empirical negative log likelihood , it is natural to wonder how much of a difference this makes in practice. Figure˜A.6 depicts LLC traces (Section˜A.5) for a highlighted number of checkpoints using either a likelihood-based estimate (with variable sequence length) or loss-based estimate (with fixed sequence length). The relative orderings of complexities does not change, and even the values of the LLC estimates do not make much of a difference, except at the final checkpoint, which has a higher value for the sub-sequence-based estimate.
A.7 LLC estimates away from local minima
Our methodology for detecting stages is to apply LLC estimation to compute at neural network parameters across training. In the typical case these parameters will not be local minima of the population loss, violating the theoretical conditions under which the LLC is defined.
It is not surprising that the estimator appears to work if is approximately a local minima. Lau et al. (2025) validated their estimator at both parameters constructed to be local minima of the population loss and also at parameters found through training with stochastic gradient descent (possibly not local minima of the empirical loss, let alone the population loss). They showed that in both cases the estimator recovers the true learning coefficient associated with the global minimum of the population loss.
On the other hand, if is far from any local minima, it is a priori quite surprising that the SGLD-based estimation procedure works at all, as in this situation one might expect the chains to explore directions in which the loss decreases. Nevertheless, Chen et al. (2023) found that, empirically, LLC estimation away from local minima appears to give sensible results in practice. In our case, with sufficient localization we see stable estimates throughout training.
Theoretically accounting for this phenomenon is an interesting open problem. Perhaps there is a notion of stably evolving equilibrium in the setting of neural network training, echoing some of the ideas of Waddington (1957), such that the LLC estimation procedure is effectively giving us the LLC of a different potential to the population loss—a potential for which the current parameter actually is at a critical point. We leave addressing this question to future work.
Appendix B LLC-based stage boundary identification
B.1 Procedure for stage boundary identification
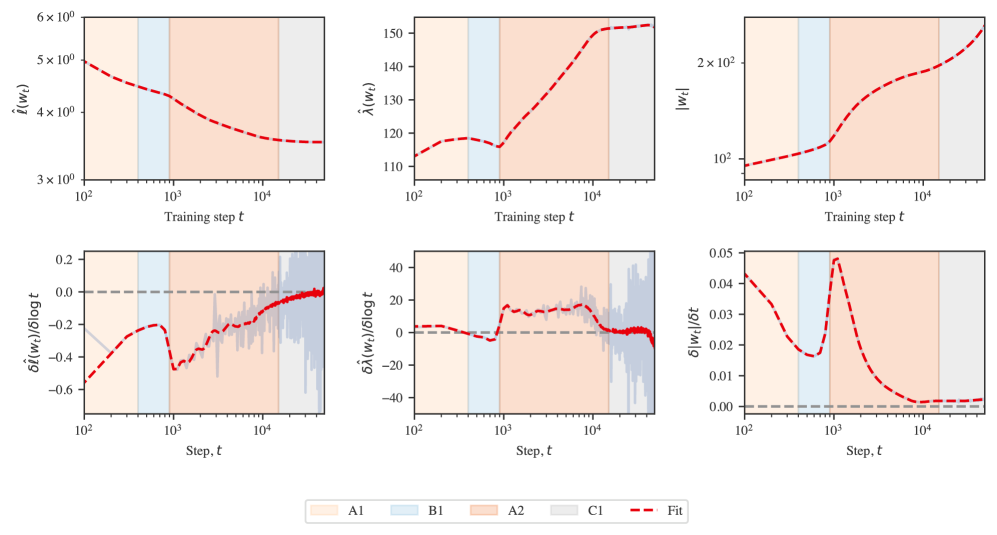
To identify stage boundaries, we look for plateaus in the LLC: checkpoints at which the slope of over vanishes. To mitigate noise in the LLC estimates, we first fit a Gaussian process with some smoothing to the LLC-over-time curve. Then we numerically calculate the slope of this Gaussian process with respect to . The logarithm corrects for the fact that the learning coefficient, like the loss, changes less as training progresses. We identify stage boundaries by looking for checkpoints at which this estimated slope equals zero. The results of this procedure are depicted in Figure˜B.1 for language and Figure˜B.2 for in-context linear regression.
At a local minima or maxima of the estimated LLC curve identifying a plateau from this estimated slope is straightforward, since the derivative crosses the x-axis. However at a saddle point, the slope may not exactly reach zero, so we have to specify a “tolerance” for the absolute value of the derivative, below which we treat the boundary as an effective plateau.
In this case, we additionally require that the plateau be at a local minimum of the absolute first derivative. Otherwise, we may identify several adjacent points as all constituting a stage boundary.
To summarize, identifying stage boundaries is sensitive to the following choices: the intervals between checkpoints, the amount of smoothing, whether to differentiate with respect to or , and the choice of tolerance. However, once a given choice of these hyperparameters is fixed, stages can be automatically identified, without further human judgment.
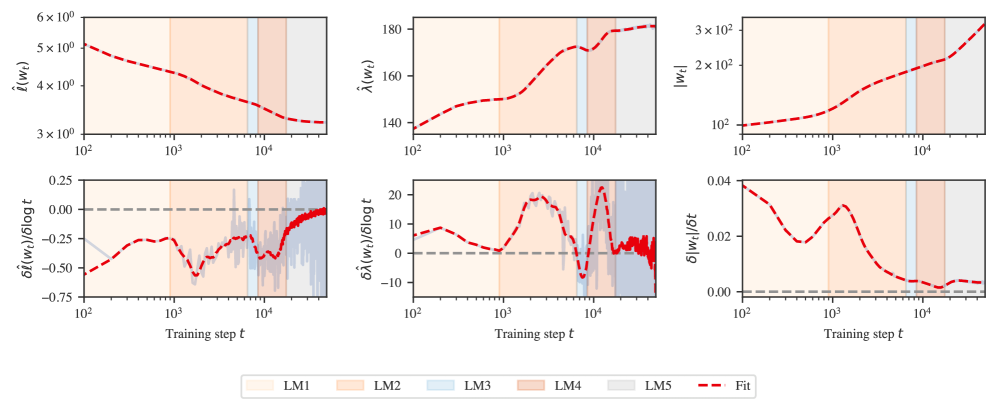
B.2 Stage boundary identification details for language model
Figure˜B.1 displays the test loss and LLC curves from Figure˜1(a) in addition to the weight norm over time and associated slopes. Stage boundaries coincide with where the slope of the LLC crosses zero, that is, where there is a plateau in the LLC.
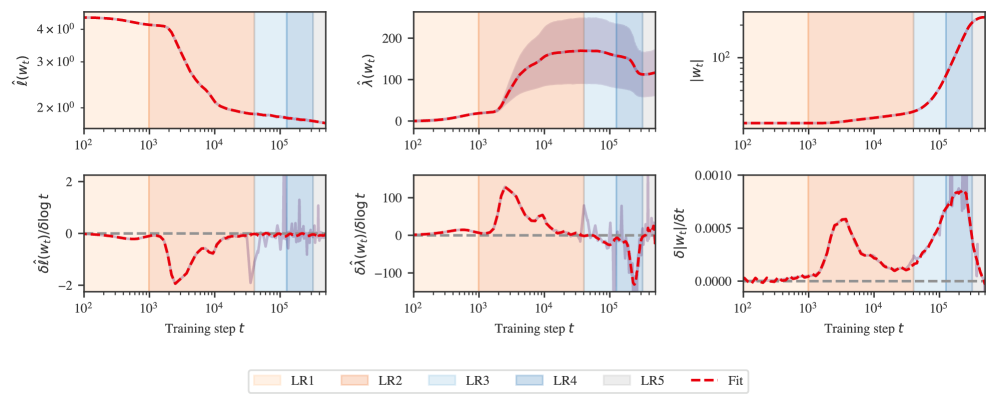
B.3 Stage boundary identification details for in-context linear regression
Figure˜B.2 displays the test loss and LLC curves from Figure˜1(b) in addition to the weight norm over time, and numerically estimated slopes associated to these three metrics. As in the case of language models, we identify stage boundaries by looking for plateaus in the LLC. Unlike the language models, here the boundaries LR1–LR2 and LR2–LR3 are clearly visible in the loss.
B.4 Stage identification for additional training runs
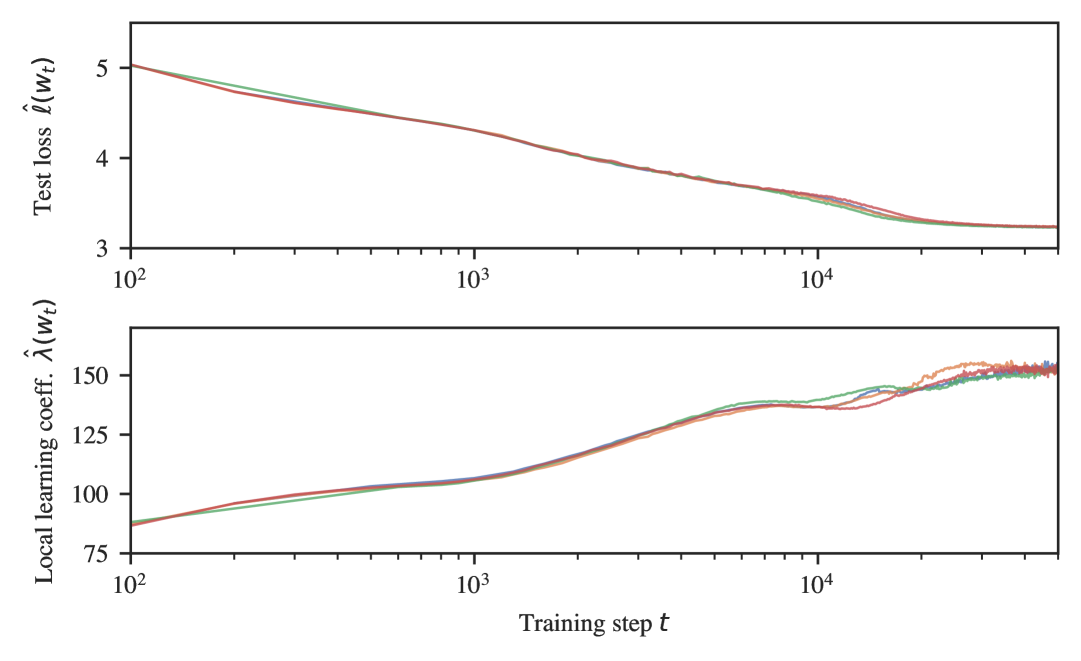
Figure˜3(a) shows loss and LLC curves for five seeds (differing in model initialization and batch schedule). In each seed, LLC estimation reveals stage LM1–LM4. In three of the five seeds, stage LM5 is subdivided into two additional stages.
Figure˜3(b) shows loss and LLC curves for five unique seeds (differing in model initialization and batch schedule). In each seed, LLC estimation reveals stages LR1–LR5. There is remarkably little variance across different seeds.
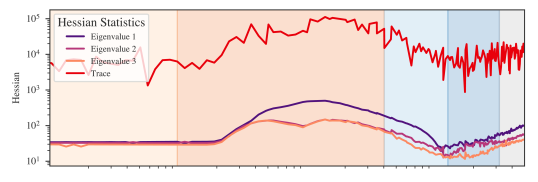
B.5 Comparison to Hessian statistics
Figure˜B.4 shows a quantification of the curvature-based notion of flatness captured by the Hessian (in contrast to the degeneracy-based notion of flatness captured by the LLC) for our in-context linear regression transformer. To estimate the trace and maximum eigenvalues shown in this figure, we use the PyHessian library (Yao et al., 2020) over a batch of samples.
Crucially, we observe that these Hessian-derived metrics (henceforth, “curvature”) and the LLC are not consistently correlated. During the first part of LR2, the LLC and the curvature are jointly increasing. Starting at around , while the LLC is still increasing, the curvature starts decreasing. In the first part of LR3, both metrics decrease in tandem, but as of around , the curvature turns around and starts increasing.
The Hessian fails to detect three of the four stage boundaries identified by our LLC-based methodology. Since these Hessian-based metrics are dominated by the largest eigenvalues—the directions of maximum curvature—they fail to observe the finer-grained measures of degeneracy that dominate the LLC. Moreover, we observe that LLC estimation is more scalable (empirically, it seems to be roughly linear in parameter count) than estimating the full Hessian (which is quadratic).
Appendix C Developmental analysis of language models
In this section, we present further evidence on behavioral (Section˜C.1) and structural (Section˜C.2) development of the language model over the course of training.
C.1 Behavioral development
C.1.1 Bigram score
We empirically estimate the conditional bigram distribution by counting instances of bigrams over the training data. From this, we obtain the conditional distribution , the likelihood that a token follows . The bigram score at index of an input context is the cross entropy between the model’s predictions at that position and the empirical bigram distribution,
| (15) |
where the range over the possible second tokens from the tokenizer vocabulary. From this we obtain the average bigram score
| (16) |
where we take fixed random sequences of and for , which is displayed over training in Figure˜4(a). This is compared against the best-achievable bigram score, which is the bigram distribution entropy itself, averaged over the validation set.
C.1.2 -gram scores
In stage LM2 we consider -grams, which are sequences of consecutive tokens, meaning -grams and bigrams are the same. Specifically, we consider common -grams, which is defined heuristically by comparing our 5,000 vocab size tokenizer with the full GPT-2 tokenizer. We use the GPT-2 tokenizer as our heuristic because its vocabulary is constructed iteratively by merging the most frequent pairs of tokens.
We first tokenize the tokens in the full GPT-2 vocabulary to get a list of 50,257 -grams for various . The first 5,000 such -grams are all -grams, after which -grams begin appearing, then -grams, -grams, and so on (where -grams and -grams may still continue to appear later in the vocabulary). We then define the set of common -grams as the first 1,000 -grams that appear in this list for a fixed , .
If we track the performance on -grams and see it improve, we may ask whether this is simply a function of the model learning to use more context in general, rather than specifically improving on the set of -grams being tracked. We measure performance against this baseline by defining an -gram score. For a fixed , we obtain the average loss of the model on predicting the final tokens of our set of 1,000 -grams and also obtain the average loss of the model on a validation set at position of each validation sequence. The -gram score is then defined to be .
C.1.3 In-context learning score
The in-context learning score is a behavioral measure of the relative performance of a model later in a sequence versus earlier in the sequence. We define to be the loss on token minus the loss on token , so a more negative score indicates better relative performance later in the sequence. A more negative ICL score does not, however, mean that a model is achieving better overall loss on later tokens; it is only about the relative improvement. For the language model, we follow a similar construction as Olsson et al. (2022), where we take to be the 500th token and to be the 50th token. This is then averaged over a 100k-row validation dataset. The performance of the language model over the course of training can be seen at the bottom of Figure˜4(f).
C.1.4 Visualizing behavioral changes
In Figure˜C.1, we visualize changes in the model’s input/output behavior by comparing model predictions before and after developmental stages and highlighting tokens with the greatest differences.

C.2 Structural development
C.2.1 Positional embedding
In Figure˜C.2, we measure the effect of the positional embedding on model performance by comparing the model’s performance at particular context positions on a validation set over the course of training against performance on the same validation set but with the positional embedding zero-ablated. The full context length is 1024, and we measure test loss at positions 1, 2, 3, 5, 10, 20, 30, 50, 100, 200, 300, 500, and 1000. In the transition from stage LM1 to LM2, the model begins using the learnable positional embedding to improve performance. The difference between test loss with and without the positional ablation is negligible at all measured positions until the LM1–LM2 boundary.
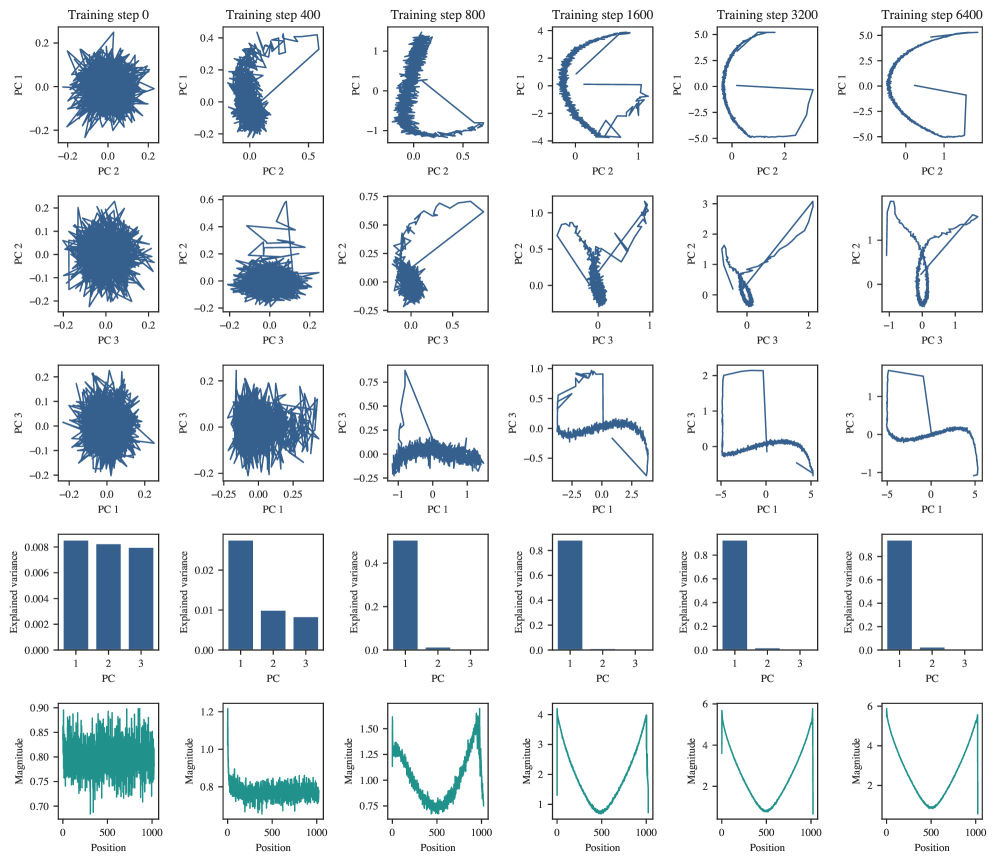
Structurally, we might predict that the positional embeddings should organize themselves in a particular way: in order to understand relative positions, adjacent positions should be embedded close to each other, and far-away positions should be embedded far apart.
In Figure˜C.3, we examine the development of the positional embedding itself over time from two angles. The first is to take the embeddings of each position in the context and to run PCA on those embeddings. The result is that as training progresses, the positional embedding PCAs gradually resolve into Lissajous curves, suggesting that the positional embeddings might look like a random walk (Antognini & Sohl-Dickstein, 2018; Shinn, 2023). However, if we look to the explained variance, we see that it grows very large for PC1, reaching at training step 6400. This is much higher than we would expect for Brownian motion, where we expect to see about explained variance in PC1 (Antognini & Sohl-Dickstein, 2018).
The second perspective we use is to look at how the magnitudes of positional embeddings over the context length develop. In this case, we observe that the magnitudes seem to have a fairly regular structure. In conjunction with the PCAs and explained variance, we might infer that the positional embeddings look approximately like a (possibly curved) line in dimensional space. A positional embedding organized in this way would make it easier for an attention head to attend to multiple recent tokens, which is necessary if a single head is to learn -grams.
C.2.2 Composition scores
Let be the query, key, and value weights of attention head respectively. There are three types of composition between attention heads in transformer models in Elhage et al. (2021):
-
Q-Composition: the query matrix of an attention head reads in a subspace affected by a previous head
-
K-Composition: the key matrix of an attention head reads in a subspace affected by a previous head
-
V-Composition: the value matrix of an attention head reads in a subspace affected by a previous head
If is the output matrix of an attention head, then and . The composition scores are
| (17) |
Where , , and for Q-, K-, and V-Composition respectively. See Figure˜C.4 for K-composition scores over time between attention heads in the induction circuits.
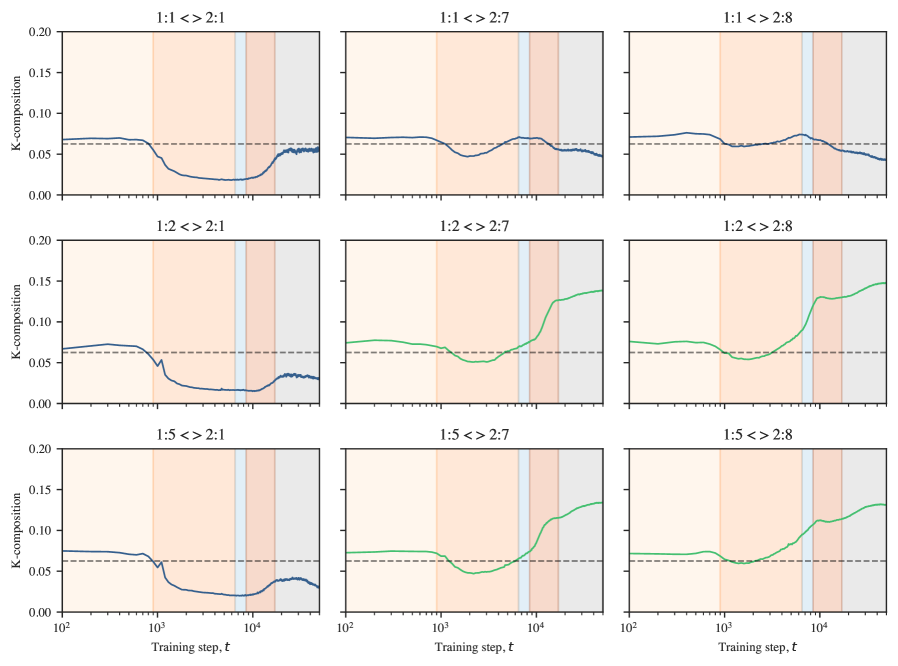
C.2.3 Previous-token matching score
The previous-token matching score is a structural measure of induction head attention. It is the attention score given to by an attention head at in the sequence (i.e., how much the head attends to the immediately preceding token).
We compute this score using a synthetic data generating process, generating 10k fixed random sequences with length between 16 and 64. The first token is a special “beginning of string" token, and the remaining tokens are uniformly randomly sampled from other tokens in the vocabulary.
For each sample in this synthetic dataset, we measure the attention score that an attention head gives to the previous token when at the last token in the sequence. These scores are averaged across the dataset to produce the previous-token matching score for that attention head at a given checkpoint. The progression of previous-token matching scores over time can be seen in Figure˜4(d).
C.2.4 Prefix matching score
The prefix matching score from Olsson et al. (2022) is defined similarly to the previous-token matching score. Given a sequence , the prefix matching score of a particular attention head is how much the attention head attends back to the first instance of when at the second instance of .
We compute this score using a synthetic data-generating process. We first generate 10k fixed random sequences of length 128. The first token is always a special “beginning of string" token and the and tokens are selected and placed randomly. One token is placed in the first half of the sequence, the other is placed in the second half, and the token is placed directly after the first token. The remaining tokens are randomly sampled from the tokenizer vocabulary, excluding the , , and beginning of string tokens.
For each sample in this synthetic dataset, we measure the attention score that each attention head assigns to the earlier instance of from the latter instance of . These scores are averaged across the dataset to produce the prefix matching score for that attention head at a given checkpoint. The progression of prefix matching scores over time can be seen in Figure˜4(e).
Appendix D Developmental analysis of regression transformers
In this section, we present further evidence on the behavioral (Section˜D.1) and structural (Section˜D.2) development of the transformer in the setting of in-context linear regression.
D.1 Behavioral development
D.1.1 Task prior score
In addition to training models on a data distribution in which tasks are generated on-the-fly, we examine the setting of Raventós et al. (2023), in which a finite set of tasks is generated ahead of time, and training samples involve randomly selected tasks from this set.
Figure˜D.1 depicts (a) the mean square distance between the model’s predictions and the zero prediction in addition to (b) the mean square distance between the model’s predictions and the “task prior” prediction, using the component-wise averaged over the set of tasks encountered during training. For all models, the minimum distance to the task prior prediction is lower than the minimum distance to the zero prediction. Hence, we call stage LR1 “learning the task prior” rather than simply learning the zero prediction.
D.1.2 ICL
We consider two variants of the ICL score: , and .
If the noise term equals zero and both tasks and inputs are normalized (i.e., ), then observations of input/output pairs are enough to precisely identify . Therefore, measures how successful the model is at initially locating the task. The fact that the tasks and inputs are not normalized changes this only slightly: the task will still sit near within a shell of vanishing thickness as .
Once localized, measures how successfully the model refines its internal estimate of with additional examples, which it can use to reduce the error due to noise.
In terms of implementation, it’s not necessary for the model to internally make a distinction between locating and refining its estimate of the task. For example, ridge regression makes no distinction. Still, we find it useful for reasoning about the progression of the model. In particular, we note that early in stage LR2, while the model begins to develop ICL for early tokens, it becomes worse at ICL over tokens late in the context. Later, at around 23k steps, stabilizes, while continues improving over the entire training run.
D.1.3 OOD generalization
To further investigate behavior in stages LR2 and LR3, we probe the model on data sampled from different distributions than encountered during training.111Cf. Raventós et al. (2023) evaluating models trained on a set of discrete tasks on the “true” distribution consisting of novel tasks. We evaluate behavior on two families of perturbations: “OOD inputs” , sampled according to a different scale
| (18) |
for some gain parameter , and “OOD tasks”
| (19) |
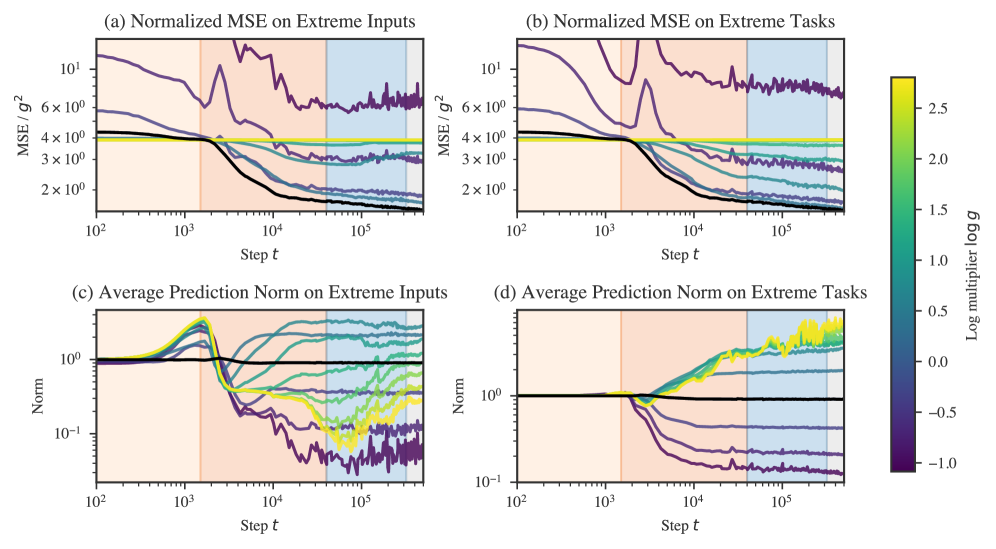
Note that these inputs and tasks are not out-of-distribution in the sense of coming from a distribution with a different support than the training distribution. However, the samples drawn from these “extreme” distributions are exponentially suppressed by the original training distribution. Figure˜D.3 plots the normalized MSE for these two distributions over training time.
Between and the model’s outputs rapidly diminish in scale for out-of-distribution samples, both for and , especially for out-of-distribution inputs. While the model is moving away from predicting with the task prior for in-distribution samples, it moves closer to predicting with the task prior for-in-distribution samples.
Between and , the model recovers on moderately out-of-distribution inputs with performance remaining close to constant beyond this range. Past this stage, performance improves constantly for out-of-distribution tasks.
For out-of-distribution inputs, performance eventually worsens for some ranges of . Between and the model further approaches the task prior prediction for extreme out-of-distribution inputs . Subsequently, between and the model moves away from the task prior prediction for extreme inputs, and performance deteriorates for inputs with . As of LR5, performance is roughly constant.
D.2 Structural development
D.2.1 Embedding
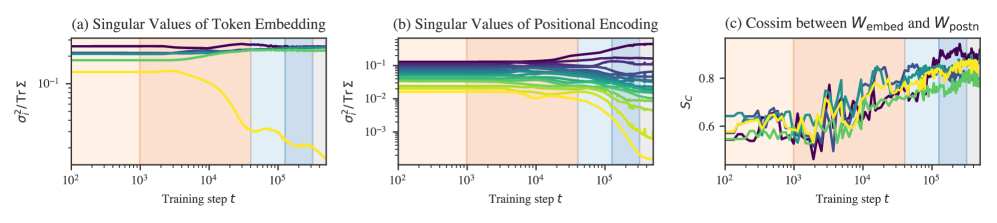
The embedding matrix is a linear transformation from . Plotting the singular values of this matrix, we notice that the embedding partially loses one of its components starting at the end of LR2 (Figure˜D.4a).
The input “tokens” span a -dimensional subspace of the -dimensional “token space.” The target tokens span an orthogonal -dimensional subspace. The collapse of one of the embedding matrix’s singular values means that the model learns to redundantly encode the inputs and targets in the same -dimensional subspace of the space of residual stream activations. The almost order of magnitude separation in the magnitudes of the square singular value means that the th component of the token embedding explains only 2.9% of the variance in activations of the residual stream immediately after the embedding, whereas the dominant components explain roughly 24% each.
Contributions to degeneracy
Given a linear transformation followed by another linear transformation , reducing the rank of from to renders components of the second transformation irrelevant. This would mean a decrease in the learning coefficient of (a decrease in the effective dimensionality of leads to a decrease in the LLC of 222Note that this is not the only possible way for the LLC to decrease. Changing the local loss landscape from quadratic to quartic or some higher power would also lower the LLC, by a fractional amount.). In the actual model, we don’t see an exact decrease in the rank, and a layer normalization sits between the linear transformation of the embedding and the linear transformations of each transformer block and unembedding. It is unclear what the precise relation between structure and degeneracy is in this case (Section˜D.2.6). Still, suggestively, the onset of embedding collapse coincides with a decrease in the rate of increase of .
D.2.2 Positional encoding
The positional encoding goes through a similar collapse to the unembedding starting during the second part of LR2 and continuing into LR3 (Figure˜D.4b). Additionally, throughout these stages, the subspace spanned by the embedding becomes more aligned with the subspace spanned by the positional encoding (Figure˜D.4c).
Contributions to degeneracy
For the same reason as with the token embedding, a decrease in the dimensionality of the subspace occupied by activations reduces the effective number of dimensions and thus the learning coefficient. This occurs both as the positional encoding’s effective dimensionality decreases (vanishing singular values, Figure˜D.4b) and as the token embedding subspace and positional embedding subspace align (increasing cosine similarity, Figure˜D.4b).
D.2.3 Attention collapse
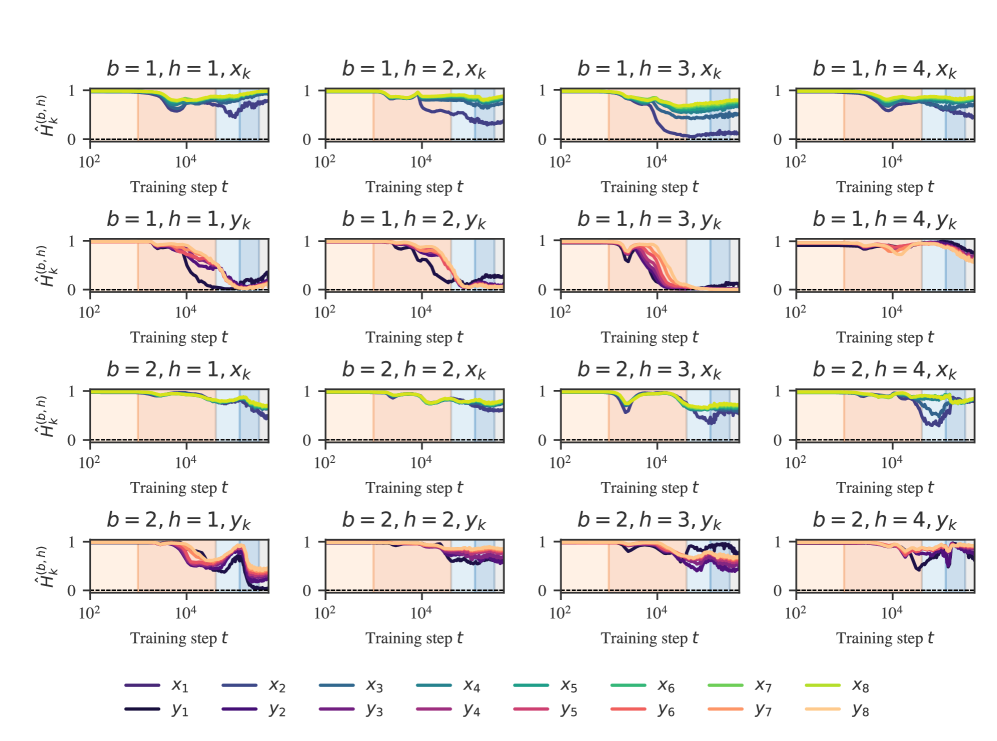
Over the course of training, we observe that some attention heads learn to attend solely (soft attention becomes hard attention) and consistently to certain positions (the attention pattern becomes content-independent). We call this phenomenon attention collapse in parallel with the other observed forms of collapse. Not only does this potentially contribute to a decrease in the LLC, but it also makes the attention heads identifiable: we find a self-attention head, previous-attention heads, previous--attention heads, and previous--attention heads.
-attention vs. -attention
For convenience we separate each attention head in two: one part for the -tokens, and the other for the -tokens.
Attention entropy score
To quantify attention hardness, we use the attention entropy score (Ghader & Monz, 2017; Vig & Belinkov, 2019). Given the attention pattern for how much token in head in block attends back to token , its attention entropy score is the Shannon entropy over preceding indices ,
| (20) |
From this, we compute the normalized entropy , which divides the attention entropy by the maximum entropy for the given context length,
| (21) |
This accounts for the entropy being calculated over different numbers of tokens and is displayed in Figure˜D.5. Notably, the identified stages line up closely to stages of these attention entropy curves.
Constant attention
Accomplishing constant attention requires the presence of biases in the query and key transformations, or if there is no bias (as is the case for the models we investigated), requires attending to the positional embedding. With the Shortformer-style positional encoding used for the language models (Section˜F.1.1), this is straightforward: the positional information is injected directly into the key and weight matrices. With the in-context linear regression models, where the positional embedding is added to the residual stream activations, this is less straightforward: achieving constant attention requires separating residual stream activations into orthogonal positional- and input-dependent subspaces, then reading from the former with the query and key weight matrices.
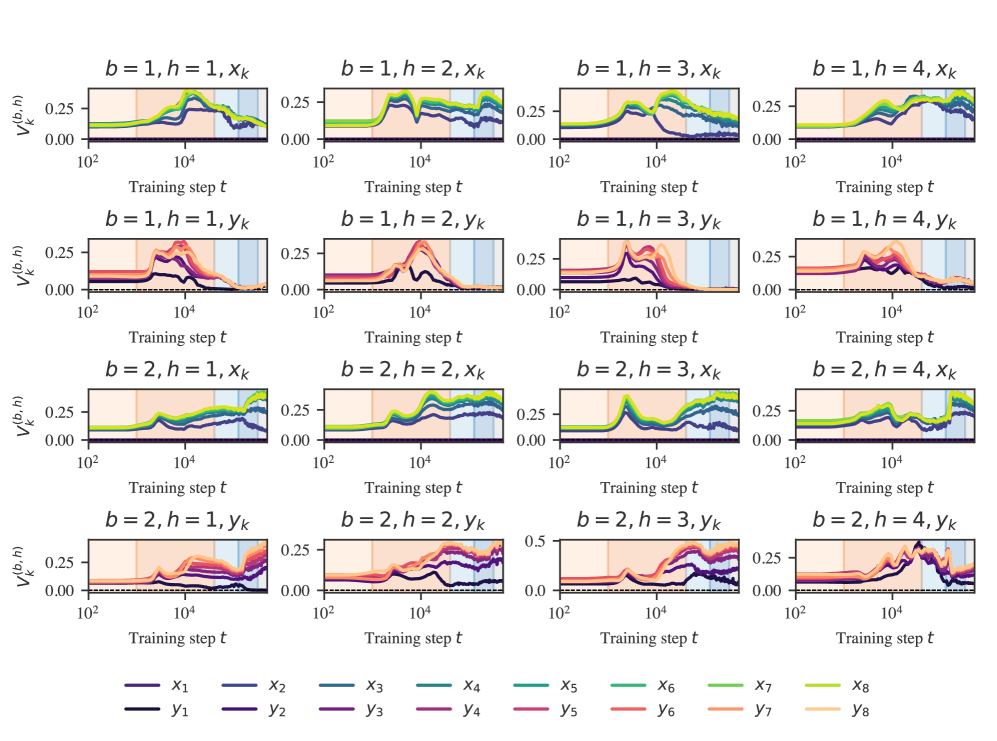
Attention variability score
To quantify how constant the attention pattern is, we use measure attention variability (Vig & Belinkov, 2019),
| (22) |
where the division by ensures the variability lies in the range . This is displayed in Figure˜D.6. These reveal that though attention hardness and variability are independent axes of differentiation, empirically, we observe that hard attention is correlated with low variability.
Self-attention score
Self-attention is measured by the average amount a token attends to itself, .
Previous-token attention score
Previous-token attention is measured the same as in the language model setting (Section˜C.2) with one difference: we compute the previous-token score not over a synthetic dataset but over a validation batch.
-attention score
The total amount attended to inputs , that is .
-attention score
Defined analogously .
Classifying attention heads
Several attention heads are easy to identify by virtue of being both concentrated and consistent. These are depicted in Figure˜D.7 and include: (B1H3y) previous-token heads (also present in the language model case), (B1H1y) previous-x, and (B1H4x, B2H1y) previous-y heads. Other training runs also include self-attention heads.

Contributions to degeneracy
Suppose an attention head in block has the following constant attention pattern (after the softmax) . That is, for each token , that attention head attends solely to a single earlier token and no others. Restricting to single-head attention (the argument generalizes straightforwardly), the final contribution of this attention head to the residual stream is the following (Phuong & Hutter, 2022):
| (23) |
where is the attention pattern, is the value matrix, and is the matrix of residual stream activations, and is the value matrix. The result of this operation is subsequently multiplied by the output matrix and then added back into the residual stream. Plugging in the hard and constant attention pattern, writing out the matrix multiplication, and filling in the definition of we get
| (24) |
For each column in , the hard attention picks out a single element of at column for each row . Now suppose that there is a token that receives no attention from any position . That is, there exists no such that . Then, there is a column in which does not contribute to the result of , and, in turn, a column in , which does not contribute to the output of the head. As discussed for the embedding and layer norm, this decrease in effective dimensionality leads to a decrease in the learning coefficient.
Note that this argument does not hold for all hard and constant attention patterns. It holds solely for attention patterns that consistently ignore some earlier token across all positions, such as the previous- and previous- heads, but not the self-attention and previous-token heads. As discussed in Section˜D.2.6, it remains unclear what exactly the threshold for “ignoring” a token should be before it contributes to degeneracy and whether any of the heads we examine actually meet this threshold.
D.2.4 Unembedding collapse
The unembedding block consists of a layer normalization layer followed by a linear transformation and finally a projection to extract the -component. Given the 64-dimensional vector of activations in the residual stream right before the unembedding (for a specific token), the full unembedding operation is:
where denotes element-wise multiplication of two vectors and are the layer normalization weights and biases respectively.
Effective unembedding weights and biases
Moving terms around, we can represent this as
where we order the outputs so that the -token corresponds to the th row. Because we are reading out a single component, we can express the unembedding transformation in terms of “effective" unembedding weights and biases
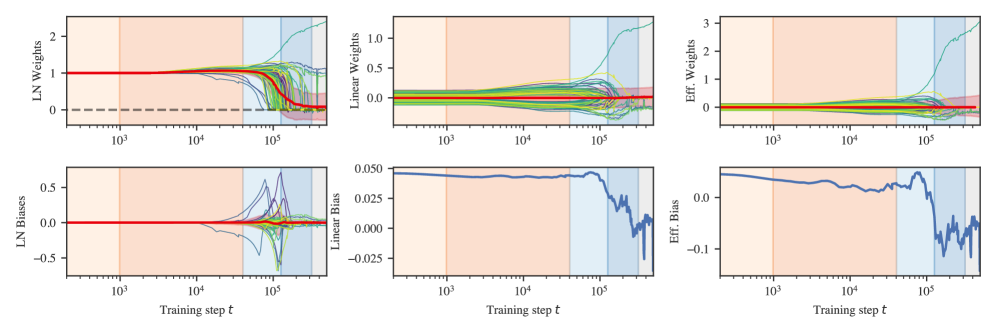
Unembedding weights over time
In Figure˜D.8, we plot , , and as a function of training steps, along with the mean weight over time. These are 64- and 1-dimensional vectors, so we can display the entire set of components. During stage LR3 the majority of weights and “collapse” to zero. Additionally, the layer normalization biases temporarily experience a large increase in variance before returning to small values. Despite this, the mean of the linear weights, layer normalization biases, and effective weights remains remarkably constant and close to zero throughout the entire process.
Contributions to degeneracy
Suppose that of the layer normalization weights have vanished, say for . Then the corresponding columns of only contribute to the unembedding via their product with the first rows of . This creates a typical form of degeneracy studied in SLT and found, for example, in deep linear networks, where we can change the weights to for any invertible matrix without changing the function computed by the network. If in addition the vanish for then the entries of are completely unconstrained, creating further degeneracy.
D.2.5 Layer normalization collapse
The “collapse” in layer normalization weights is not unique to the unembedding. As depicted in Figure˜D.9, this behavior occurs in all layer norms except for the second MLP. The biases also remain centered close to zero even as the variance in biases grows much larger. Unlike in the unembedding, these layers begin to change earlier (starting halfway through LR2).
What is most striking about the layer normalization collapse is that it occurs without any explicit regularization (neither weight decay nor dropout). As such, it demonstrates a clear example of implicit regularization, i.e., inductive biases in the optimizer or model that favor simpler solutions.
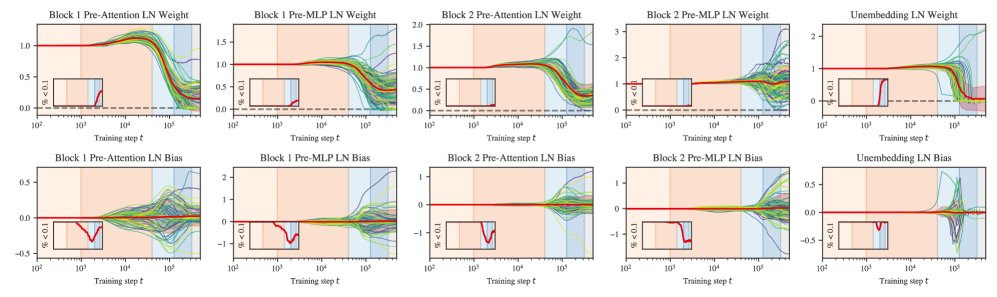
Contributions to degeneracy
In the previous section, we describe how layer norm collapse in the unembedding is linked to an increase in degeneracy because it ensures that parameters in the subsequent linear layer become irrelevant. The same is true for layer norm which precedes the attention and MLP blocks.
D.2.6 Degeneracy and development
In the previous subsections, we provide a set of theoretical arguments for how embedding collapse (Section˜D.2.1), layer normalization collapse (Section˜D.2.5), and attention collapse (Section˜D.2.3) can lead to an increase in degeneracy, even while leaving the implemented function unchanged.
The free energy formula tells us that, for two different solutions (sets of weights) with the same loss, the Bayesian posterior will asymptotically prefer the model that has the lower learning coefficient (i.e., higher degeneracy). This suggests that these different forms of collapse may be driven by a bias towards higher degeneracy, as captured in the free energy formula. However, in idealized Bayesian inference, we do not expect the posterior to concentrated around the neighborhood of an equal-loss-but-higher-degeneracy local minimum to begin with. That this kind of transition arises in practice might arise from one of the various differences between Bayesian inference and gradient-based training.
Actually establishing a causal link between increasing degeneracy and structure development is beyond the scope of this paper. For one, the theoretical arguments hinge on the collapse being complete, that is, the components that go to zero must become exactly zero in the limit, where we take the number of samples to compute the loss to infinity. In practice, we expect there to be some threshold below which we can treat weights as effectively zero. Second, even if these explanations are correct, we do not know that they account for all of the empirically observed decrease in the LLC during these stages. There may be other drivers we missed. Finally, establishing a causal link requires theoretical progress in relating the Bayesian learning process to the SGD learning process. The arguments are suggestive, but currently only a source of intuition for how structure and degeneracy can be related, and a starting point for future research.
Appendix E One-layer language model experiments
We also trained and ran some experiments on a one-layer language model (see Section˜F.1.1 for details). We aggregate results for the one-layer language model here, mirroring the experiments for the two-layer language model where possible. The early development of the one-layer model has many parallels with the two-layer model. At a single stage boundary, just as it occurs in the two-layer model, the one-layer model minimizes its bigram score (see Section˜C.1.1), begins utilizing the positional embedding to noticeably improve performance (see Section˜C.2.1), and starts making sudden improvements to the same -gram scores (see Section˜C.1.2). Remarkably this occurs at the same checkpoint as in the 2-layer model (at 900 training steps).
One key difference, however, is that this occurs at the second stage boundary as discerned by the plateaus of the LLC estimation. We did not closely investigate why the LLC estimation appears to drop between steps 400 and 900 in this model. As a result though, we do observe an interesting qualitative similarity to the drop in LLC in stage LM3 of the two-layer model, that this drop precedes a noticeable bump in the loss function.

Appendix F Transformer training experiment details
F.1 Language models
F.1.1 Architecture
The language model architectures we consider are one- and two-layer attention-only transformers. They have a context length of 1024, a residual stream dimension of , attention heads per layer, and include layer normalization layers. We also used a learnable Shortformer positional embedding (Press et al., 2021). The resulting models have a total of parameters for and parameters for . We used an implementation provided by TransformerLens (Nanda & Bloom, 2022).
| Component | 1-Layer | 2-Layer |
| Token Embedding Weights | ||
| Positional Embedding Weights | ||
| Layer 1 Layer Norm Weights | ||
| Layer 1 Layer Norm Bias | ||
| Layer 1 Attention Query Weights | ||
| Layer 1 Attention Key Weights | ||
| Layer 1 Attention Value Weights | ||
| Layer 1 Attention Output Weights | ||
| Layer 1 Attention Query Bias | ||
| Layer 1 Attention Key Bias | ||
| Layer 1 Attention Value Bias | ||
| Layer 1 Attention Output Bias | ||
| Layer 2 Layer Norm Weights | N/A | |
| Layer 2 Layer Norm Bias | N/A | |
| Layer 2 Attention Query Weights | N/A | |
| Layer 2 Attention Key Weights | N/A | |
| Layer 2 Attention Value Weights | N/A | |
| Layer 2 Attention Output Weights | N/A | |
| Layer 2 Attention Query Bias | N/A | |
| Layer 2 Attention Key Bias | N/A | |
| Layer 2 Attention Value Bias | N/A | |
| Layer 2 Attention Output Bias | N/A | |
| Final Layer Norm Weights | ||
| Final Layer Norm Bias | ||
| Unembedding Weights | ||
| Unembedding Bias | ||
F.1.2 Tokenization
For tokenization, we used a truncated variant of the GPT-2 tokenizer that cut the original vocabulary of 50,000 tokens down to 5,000 (Eldan & Li, 2023) to reduce the size of the model. We think this may contribute to the prominence of the the plateau at the end of LM1: the frequency of bigram statistics depends on your choice of tokens, and a larger tokenizer leads to bigrams that are individually much less frequent.
F.1.3 Training
The models are trained on a single epoch over steps on 5 billion tokens using a resampled subset of the Pile (Gao et al., 2020; Xie et al., 2023) using a batch size of . A snapshot was saved every steps for a total of checkpoints, though a majority of analysis used checkpoints every 100 steps. The training time was around 6 GPU hours per model on an A100. Additional seeds were trained on v4 TPUs at around 1.5 TPU hours per model.
Training was conducted on the first 10 million lines of the DSIR-filtered Pile (Xie et al., 2023; Gao et al., 2020) but did not exhaust all 10 million lines. The model was subject to weight decay regularization, without the application of dropout. We did not employ a learning rate scheduler throughout the training process.
| Hyperparameter | Category | Description/Notes | Value |
|---|---|---|---|
| Data | # of training samples | ||
| Data | # of training steps | ||
| Data | # of test samples | 512 | |
| Tokenizer Type | Data | Type of Tokenizer | Truncated GPT-2 Tokenizer |
| Data | Vocabulary size | 5,000 | |
| Data | Context size | 1,024 | |
| Model | # of layers in the model | ||
| Model | # of heads per layer | 8 | |
| Model | MLP hidden layer size | N/A | |
| Model | Embedding size | 256 | |
| Model | Head size | 32 | |
| Model | Model initialization | 1 | |
| m | Training | Batch Size | 100 |
| Optimizer Type | Optimizer | Type of optimizer | AdamW |
| Optimizer | Learning rate | ||
| Optimizer | Weight Decay | ||
| Optimizer | Betas |
F.2 In-context linear regression transformers
F.2.1 Architecture
In the following refers to the number of layers (blocks) in the transformer, is the number of heads in each layer, is the dimension of inputs and is the number of pairs provided to the Transformer in-context.
The architecture is a pre-layer-norm decoder-only transformer modeled after NanoGPT Karpathy, 2022; see also Phuong & Hutter, 2022 with a learnable positional embedding. For the models discussed in the main body, we consider , transformers (with parameters), i.e., two transformer blocks with four attention heads each.
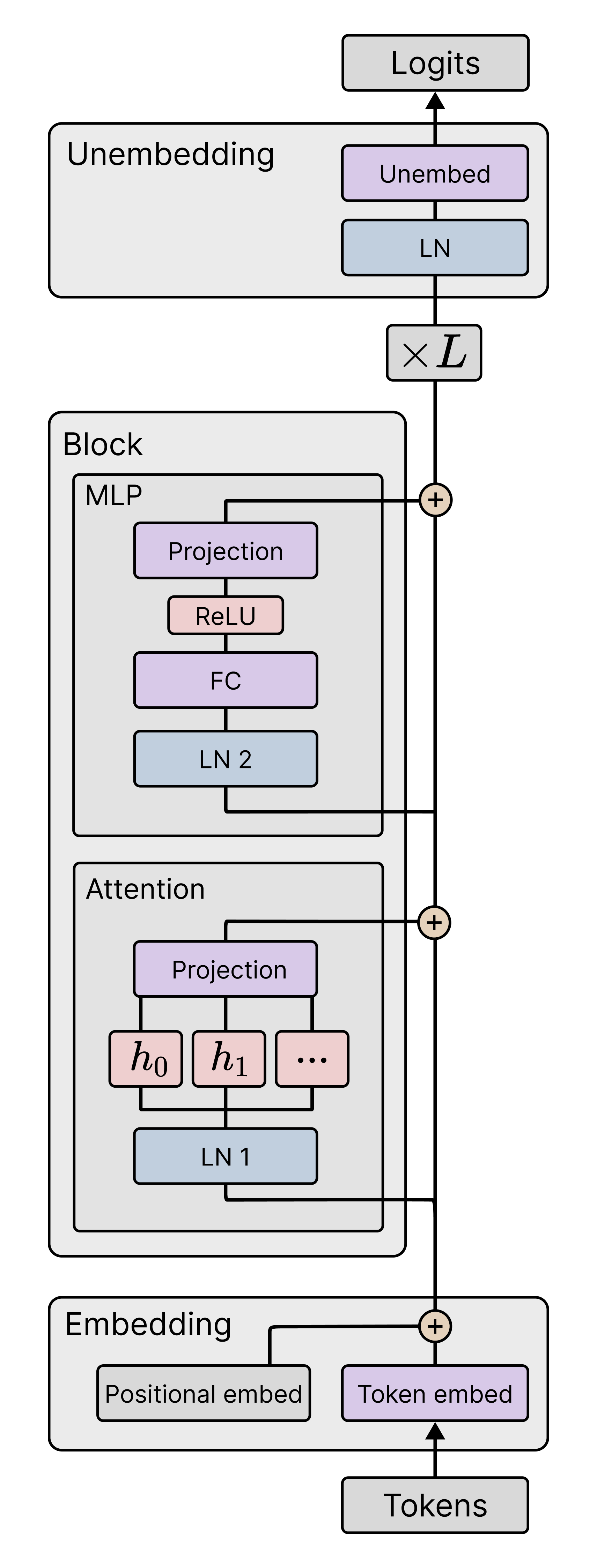
| Component | # of Parameters |
|---|---|
| Token Embedding Weight | |
| Positional Embedding Weight | |
| Layer 1 Layer Norm Weight 2 | |
| Layer 1 Layer Norm Bias 1 | |
| Layer 1 Attention Weights | |
| Layer 1 Attention Output Weights | |
| Layer 1 Layer Norm Weight 1 | |
| Layer 1 Layer Norm Bias 2 | |
| Layer 1 Feed-Forward MLP Weight | |
| Layer 1 Feed-Forward MLP Bias | |
| Layer 1 Feed-Forward Output Weight | |
| Layer 1 Feed-Forward Output Bias | |
| Layer 2 Layer Norm Weight 1 | |
| Layer 2 Layer Norm Bias 1 | |
| Layer 2 Attention Weights | |
| Layer 2 Attention Output Weights | |
| Layer 2 Layer Norm Weight 2 | |
| Layer 2 Layer Norm Bias 2 | |
| Layer 2 Feed-Forward MLP Weight | |
| Layer 2 Feed-Forward MLP Bias | |
| Layer 2 Feed-Forward Output Weight | |
| Layer 2 Feed-Forward Output Bias | |
| Unembedding Layer Norm Weight 1 | |
| Unembedding Layer Norm Bias 1 | |
| Unembedding Weight 2 | |
| Unembedding Bias 2 |
F.2.2 Tokenization
To run contexts through the above model requires an initial encoding or “tokenization step” and final “projection step.” The context is encoded as a sequence of “tokens” as follows:
Through the main text, we write for . Note that this tokenization includes the final token even though this receives no training signal. For this reason, we omit this token from the attention entropy and variability plots (Figures˜D.5 and D.6).
The transformer outputs a series of tokens of the same shape as . To read out the predictions, we read out the first component of every other token, i.e.,
| (25) | ||||
| (26) |
F.2.3 Training
We train from a single seed for each choice of architecture and optimizer hyperparameters using minibatch stochastic gradient descent. We train without explicit regularization and use the Adam optimizer (Kingma & Ba, 2014). The training runs take 1 to 5 TPU-hours on TPUs provided by Google Research. Models are trained from the same initialization and on the data vectors within each batch (but for different sets of tasks and task orderings).
Models are trained on a single epoch: each of the batches consists of a new set of sequences with batch size 256. For the LLC estimates, we save 190 checkpoints: 100 are linearly spaced over the training run, and the remaining 90 are logarithmically spaced. We perform LLC estimation and other analyses on these checkpoints.
| Hyperparameter | Category | Description/Notes | Default Values |
|---|---|---|---|
| Data | # of training samples | 128,000,000 | |
| Data | Batch size during training | 256 | |
| Data | # of training steps | 500k | |
| Data | # of eval samples | 2048 | |
| Data | Dimensions of linear regression task (Task size) | 4 | |
| Data | Maximum in-context examples | 8 | |
| Data | Variance of noise in data generation | 0.125 | |
| Model | # of layers in the model | 2 | |
| Model | # of attention heads per layer | 4 | |
| Model | Size of the hidden layer in MLP | 64 | |
| Model | Embedding size | 64 | |
| Misc | Training run seeds | {(0, 1, 2, 3, 4)} | |
| Optimizer Type | Optimizer | Type of optimizer | Adam |
| Optimizer | Maximum learning rate | 0.003 | |
| Optimizer | Weight Decay | 0 | |
| Optimizer | Betas | (0.9, 0.999) | |
| Scheduler Type | Scheduler | Type of learning rate scheduler | OneCycleLR |
| Strategy | Scheduler | Strategy for annealing the learning rate | Linear |
| % start | Scheduler | Percentage of the cycle when learning rate is increasing | 0.5 |
Cite as
@article{hoogland2024developmental,
author = {Jesse Hoogland and George Wang and Matthew Farrugia-Roberts and Liam Carroll and Susan Wei and Daniel Murfet},
title = {Loss Landscape Degeneracy and Stagewise Development of Transformers},
journal = {Transactions on Machine Learning Research},
year = {2025},
url = {https://openreview.net/forum?id=2JabyZjM5H},
abstract = {We show that in-context learning emerges in transformers in discrete developmental stages, when they are trained on either language modeling or linear regression tasks. We introduce two methods for detecting the milestones that separate these stages, by probing the geometry of the population loss in both parameter space and function space. We study the stages revealed by these new methods using a range of behavioral and structural metrics to establish their validity.}
}